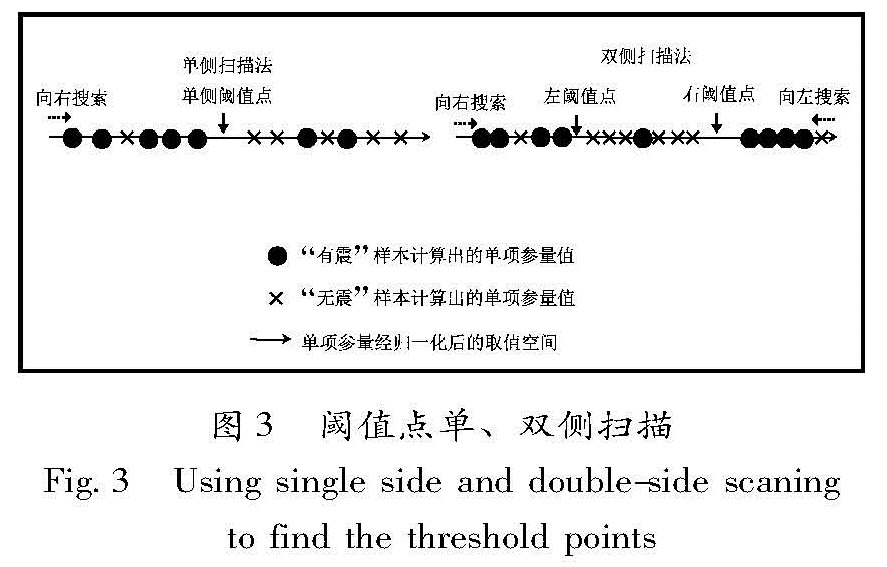
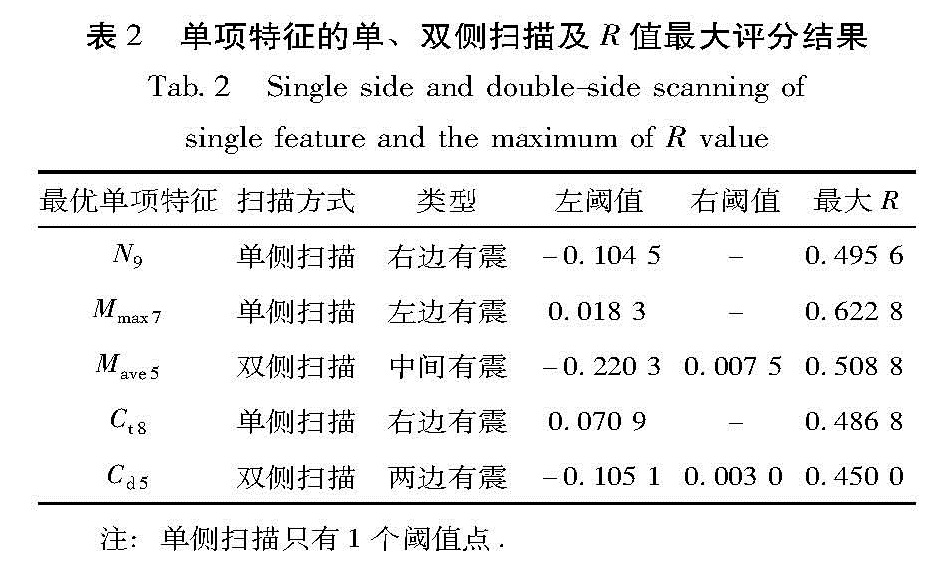
选取时间集中度Ct、空间集中度Cd(杨明芝等,2006)、地震频次N、平均震级Mave和最大震级Mmax共5个地震学参数进行单项特征的计算。经归一化、单双侧阈值扫描、R值计算后,获得5个参数的单项特征的阈值点和R值统计(表2),统计显示最优单项特征分别是:频次N9(即地震前9个月开始再向前推1年的年频次N、最大震级Mmax7(从震前7个月开始,时间向前推1年的时段内的最大震级Mmax)、平均震级Mave5(从震前5个月开始,时间向前推1年的时段内的平均震级Mave)、时间集中度Ct8(从震前8个月开始,时间向前推1年的时段内的时间集中度Ct)、空间集中度Cd5(从震前5个月开始,时间向前推1年的时段内的空间集中度Cd),每个最优单项特征的扫描方式及相应R值最大评分见表2。
表2 单项特征的单、双侧扫描及R值最大评分结果
Tab.2 Single side and double-side scanning of single feature and the maximum of R value
注:单侧扫描只有1个阈值点.
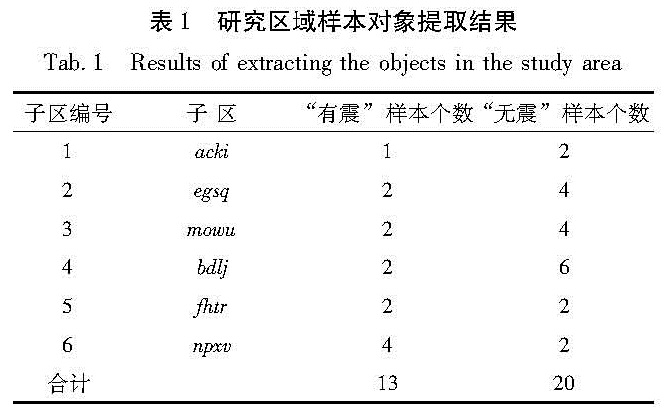
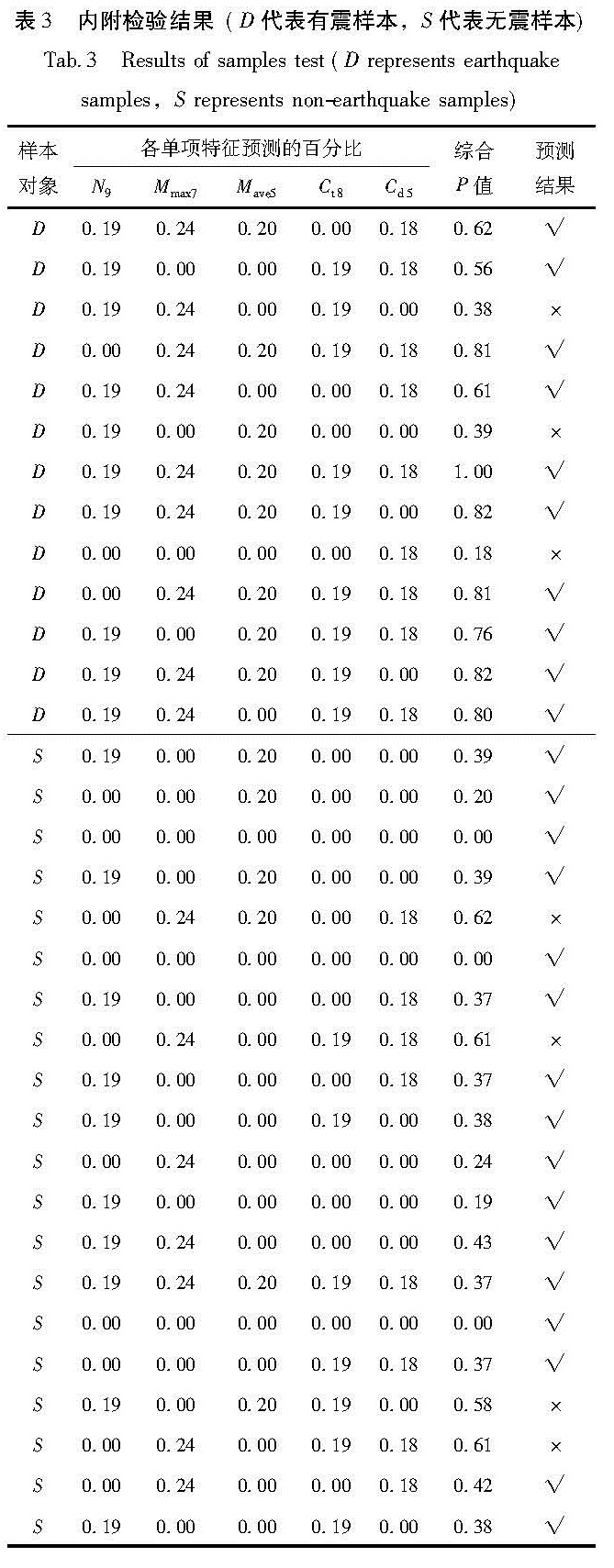
按R值加权后,最优单项特征N9,Mmax7,MAve5,Ct8,Cd5的权重分别为:0.19,0.24,0.20,0.19,0.18。利用最优单项特征按R值加权计算综合参数P,对13次“有震”样本和20次“无震”样本进行检验,结果“有震”样本报错3次,“无震”样本报错4次,综合R值评分为0.6(表3)。
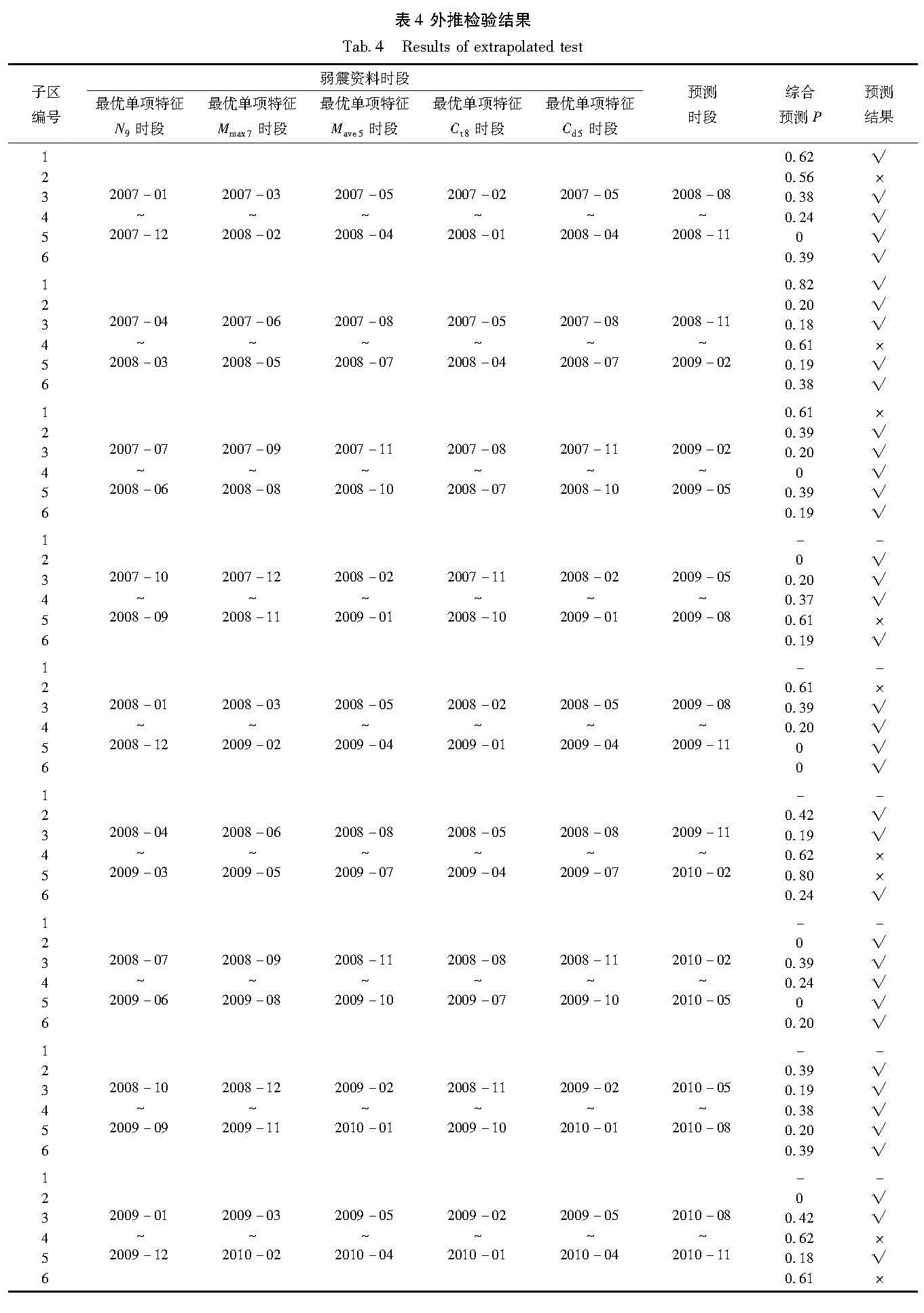
以未进行经验获取的2007年1月至2010年11月的地震目录进行外推预测检验(表4)。由于最优单项特征是从已发生的震例中提取出的经验,是从地震发生时刻向前反推的方式获得的结果,在实际预测中无法预知发震时刻,因此本文采用如下方式使用最优单项特征进行实际地震预测:
① 计算单元格内2007年1月至2007年12月1年的弱震频次N,由于N9是对未来第9个月即2008年9月的震情进行预测; 对于最大震级Mmax7,2007年3月至2008年2月的弱震资料与2008年9月的震情对应; 同理对于平均震级Mave5,该时段是2007年5月至2008年4月; 对于时间集中度Ct8,该时段是2007年2月至2008年1月; 对于空间集中度Cd5,该时段是2007年5月至2008年4月。
② 计算上述各个时段相应的地震学参数值并作归一化处理。
③ 将归一化后的地震学参数值与相应的最优单项特征的阈值点(表2)进行比较,如果参数值位于“有震”区间,则判断未来有地震发生,否则判为无震。
④ 将判为有震的最优单项特征的R值累加并计算百分比,若大于50%,则综合预测认为未来有地震发生,否则认为未来无地震发生。
⑤ 以第①步中各参数的开始时间为起点,以窗长1年,步长3个月进行时间扫描,每滑动一次就重复②~④步。
⑥ 针对每个单元格重复步骤①~⑤后,计算结束。
表3 内附检验结果(D代表有震样本,S代表无震样本)
Tab.3 Results of samples test(D represents earthquake samples,S represents non-earthquake samples)
2007年1月至2010年12月研究区共发生M
S5.5以上地震3次,分别是:青海海西2008年11月10日6.3级、2009年8月28日6.4级和2009年8月31日5.9级地震,震中位于子区1内。
表4是以1年为窗长,3个月为滑动步长,以4个月为预测时间的预测结果。其中,子区编号代表6个子区,弱震资料时段给出了计算每个最优单项特征所用的弱震时段,针对预测时段,5个最优单项特征给出综合预测结果。
可以看出,1号子区2008-08~2008-11、2008-11~2009-02和2009-02~2009-05,前2个时段内综合P值分别为0.62和0.82,预测为有震,这与2008年11月海西6.3级地震事实相符,而2009-02~2009-05综合P值为0.61,但事实上2009-02~2009-05时段内1号子区并无地震发生,因此认为该预测与事实不符,属于虚报。由于受2008年11月10日海西6.3级地震的影响,且与2009年8月28日海西6.4级地震的发震间隔不足1年,已经不满足本文的计算条件(至少连续2年的弱震资料),因此以符号“-”表示1号子区的最优单项特征不满足计算条件。除去“-”的情况,表4中共有48次预测,针对2008年海西6.3级地震有2次预测,预测结果正确,其余均为对无震时段内的预测,共有9次虚报。