收稿日期:2011-10-09
基金项目:中国地震局地震科技星火计划项目(XH1017)与山东省地震局合同制项目(08Q08、09Q14、10Q10)联合资助.
基金项目:中国地震局地震科技星火计划项目(XH1017)与山东省地震局合同制项目(08Q08、09Q14、10Q10)联合资助.
(1.山东省地震局,山东 济南 250014; 2.济南市地震局,山东 济南 250001)
(1.Earthquake Administration of Shandong Province,Jinan 250014,Shandong,China)(2.Earthquake Administration of Jinan Municipality,Jinan 250001,Shandong,China)
Rough Set; Neural Network; study of earthquake cases; seismic anomaly indicator
采用《中国震例》作为数据源,通过初步整理分析和预处理,构建了较完备的震例研究样本集。尝试将粗糙集与BP神经网络相结合的方法引入到震例研究中,用基于粗糙集的属性约简算法从众多复杂的地震异常指标中筛选出对最终分类起决定作用的核心异常作为输入,震级作为输出,构建了泛化能力强的BP神经网络模型来模拟异常与地震之间的不确定关系。仿真测试结果表明:地震震级预测精度误差基本控制在-0.5~0.5级之间。
Firstly,using “China earthquake case” as data source,we built a fairly complete sample set for earthquake case study through preliminary analysis and pretreatment and introduced the combination of Rough Set and BP Neural Network to the earthquake case.Secondly,we selected the core abnormalities which plays a decisive role in final classification from a number of complex seismic anomaly indicators as the input by use of attribute reduction algorithm based on Rough Set,and took the discrete magnitude as the output.Furthermore,we built a generalized BP Neural Network model to simulate the uncertain relationship between the seismic anomaly and the earthquake.Finally,the result of simulation tests showed that the precision errors of earthquake magnitude prediction is between -0.5 and 0.5.
地震预测是世界性科学难题,因为地震的孕育和发生是很复杂的自然现象。在研究探索中,人们发现地震发生前会出现大量异常现象,且异常现象出现的种类多少、持续时间与地震之间有一定的关系,但这种关系具有很强的不确定性,是一种非线性映射关系,很难通过简单的解析表达式来描述,这使得地震预测具有较高的难度。
神经网络可以通过学习大量样本得到输入与输出之间高度非线性映射关系,这与一些学者从历史震例中总结出某些规律的地震预测思路相一致。但在实际信息处理时,一旦输入信息量过大,神经网络结构就会变复杂,使得训练时间大大延长,实效性变差。粗糙集可以解决这个问题,它可以通过发现数据之间的内在关系、去掉冗余、抽取核心属性从而简化输入。因此,本文尝试将粗糙集与BP神经网络相结合应用于震例研究中,通过粗糙集属性约简算法对震例数据进行处理,将众多地震异常中筛选出的核心异常作为输入,将震级作为输出,构建泛化能力强的神经网络模型来模拟异常与地震之间的不确定关系,为地震预测研究提供更客观的指导。
粗糙集理论(Rough Set,简称RS),是波兰学者Pawlak(1982)提出的一种能够定量分析处理不精确、不一致、不完整信息与知识的理论方法。从本质上讲,粗糙集反映了认知过程在非确定性、非模型化信息处理方面的机制和特点,是一种有效的非单调推理工具。粗糙集和其它处理不确定问题的理论最显著的区别是:它无需提供任何先验信息,只需从给定问题的描述集合出发,找出该问题的内在规律,所以对问题的描述和处理是比较客观的。
可辨识矩阵(Discernibility Matrix)是由波兰华沙大学的著名数学家Skowron 和 Stepaiuk(1994)提出来的,是近年来在粗糙集约简上出现的一个有力工具,在粗糙集理论中,它的地位非常重要。其核心思想是:将数据表中所有与属性区分有关的信息都浓缩在一个矩阵中,把存在于复杂的信息系统中的全部不可区分关系表达出来,且不改变原来系统中的潜在知识,从而大大提高系统获得知识的效率。通过该方法可以很容易求得约简和核,所以基于可辨识矩阵的属性约简算法简单易行,许多属性约简算法都将它作为基础。
设S=(U,C∪D,V,f)为一个决策表, 其中,U=(x1,x2,…,xn)为论域, C={c1,c2,…,cm} 为条件属性集, D={d}为决策属性集, 且A=C∪D, V是属性的值域集, f是属性空间向值域空间的映射函数f:U×A→V, 则可辨识矩阵可定义为M(S)=[mij]n×n。 其中矩阵项定义为 mij(i,j=1,2,…,n; k=1,2,…,m), 公式如下:
mij={0 f(xi,d)=f(xj,d),
{ck〖JB<1|〗ck∈C} f(xi,d)≠f(xj,d)且f(xi,ck)≠f(xj,ck),
f(xi,d)≠f(xj,d)且f(xi,ck)=f(xj,ck).(1)
由式(1)可知,当两个样本的决策属性值相同时,矩阵元素mij定义为0,表明这种情况不能区分两个样本; 当两个样本的决策属性值不同时,分为两种情况:(1)条件属性值不完全相同时,矩阵元素mij定义为条件属性值不相同的所有属性集合;(2)条件属性值完全相同,说明这两个样本发生冲突,互不相容,矩阵元素mij定义为空集。
可辨识矩阵的定义表明:矩阵中的属性组合数为1的元素项是对最终决策起决定作用的,是决策表的核属性(核属性可能为空),是必须保留的。显然,凡是条件属性组合中包含有核属性的矩阵元素,都可以仅用核属性就把决策表中决策值不同的记录区分开来,也就是说对于包含有核属性的矩阵元素而言,其属性组合中除核属性外的其他条件属性都是多余的,则这些元素项可被约简。因此,通过可辨识矩阵可以很容易地得到核属性。
属性约简是基于粗糙集理论的重要研究内容之一,范君晖等(2007)、张运陶和丁保淼(2007)、周必水和黄小克等(2007)、孙林嘉等(2009)、徐妙君和吴远红(2009)、董晓娜等(2010)已陆续将基于粗糙集的属性约简算法应用到了工业、商业、社会科学、医学、生物学、网络安全、地震等研究领域中。
基于可辨识矩阵的属性约简算法如下:
算法1
输入:决策表T; 输出:约简RED(初始时,设置RED=)。
步骤1:计算决策表T的可辨识矩阵M,并删除可辨识矩阵M中的重复项;
步骤2:依次扫描可辨识矩阵M的各元素,如果存在只含有一个属性的元素,则记为核属性CORE(CORE∈C), 令RED=RED∪{CORE},转至步骤3。如果不存在只含有一个属性的元素,转至步骤5;
步骤3:删除可辨识矩阵M中包含CORE的其他所有元素项;
步骤4:如果M=,则输出RED,算法结束。否则,转至步骤2继续循环;
步骤5:计算剩余属性的重要性(杨帆,2005),并按照其重要性大小进行排序,选出其中最重要的属性Csig(Csig∈C),令RED=RED∪{Csig},并删除可辨识矩阵M中含Csig 的其他所有元素项;
步骤6:如果M=,则输出RED,计算结束。否则,转至步骤5继续循环。
人工神经网络(Artificial Neural Network,简称ANN)是20世纪80年代中期兴起的一门科学,它模拟人脑的一些基本特征,利用非线性映射和并行处理方法,通过不断学习和训练,完成输入与输出之间的映射关系。ANN在模式识别、机器学习、决策支持、知识发现和数据挖掘等领域都得到广泛的应用。
1986年,美国加州大学的Rumelhart和McClelland(1986)在研究并行分布式信息处理方法时,提出了利用误差反向传播训练算法构造的一种神经网络Back-Propagation Network,简称BP神经网络。
据统计,在人工神经网络的应用中,80%以上所采用的是BP神经网络,因为其很好地体现了人工神经网络最完美、最精华的部分。它在结构上类似于多层感知器,是一种有隐含层的多层前馈型网络,可对非线性可微分函数进行权值训练,很好地解决了多层网络中隐含单元连接权的学习问题(Robert,1987)。由于其具备了结构简单、可调用参数多、训练算法全、可操控性强等优势,因此得到广泛应用。
具有隐含层BP网络的结构如图1所示,网络包括输入层、隐含层、输出层。其中隐含层可以由多层组成,每一层有若干个节点,前层和后层通过权值连接,同一层上的各节点之间无耦合连接。BP网络结构的每一层连接权值都可以通过学习来调节,它的基本处理单元(输入层除外)为非线性的输入输出关系,一般选Sigmoid型函数作为传递函数。
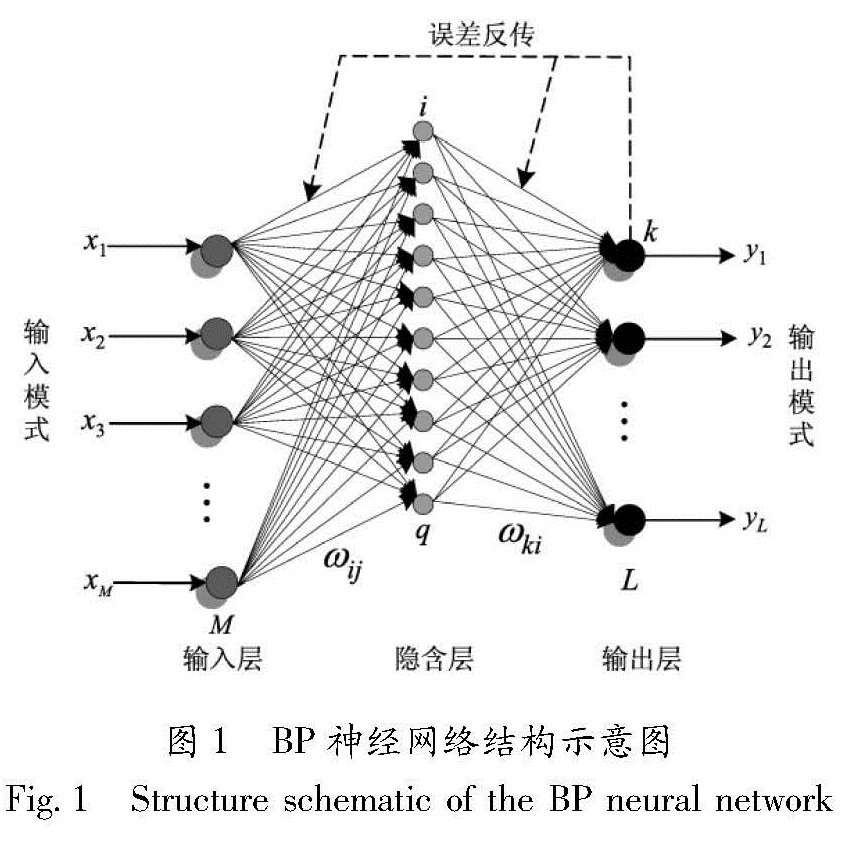
图1 BP神经网络结构示意图
Fig.1 Structure schematic of the BP neural network
震前异常的种类多少、持续时间与震级大小
之间的关系是一种非线性映射关系,很难通过简单的解析表达式对其进行描述,如何客观合理地分析这种关系,是地震预测研究领域中的关键问题。神经网络最大的优势是可以通过输入信息充分逼近任意复杂的非线性关系,具有自学习、自适应能力,并有很强的容错性,对输入数据中存在的噪声也不敏感。因此,选用神经网络模型可以很好地模拟地震异常指标与震级之间的关系。但震前出现的异常数量繁多,如果不作处理,将全部指标作为输入来构造神经网络,会使得网络结构复杂,训练时间过长,甚至得不出想要的结果。一些学者凭经验或数理统计挑选一些异常指标构造神经网络,这样有些主观和盲目,对实际的预测结果也可能有一定影响。通过粗糙集属性约简算法提取核心异常指标作为输入,可以降低网络结构的复杂程度,缩短训练时间。因此,本文提出了一种基于粗糙集的BP神经网络在震例中的应用模型(图2)。
基于粗糙集的BP神经网络在震例中的应用模型包括粗糙集属性约简模块、神经网络构造及训练模块、神经网络仿真测试模块。各模块的主要功能如下:(1)粗糙集属性约简模块:从震例数据库中提取数据,对其进行异常赋值、震级离散化等相关预处理。将处理后的异常指标构造可辨识矩阵,利用基于可辨识矩阵的属性约简算法进行计算,提取核心异常指标;(2)神经网络构造及训练模块:在Matlab环境下,将甄选出的核心异常指标作为输入神经元,离散化震级作为输出神经元,构造BP神经网络。调用震例数据库中
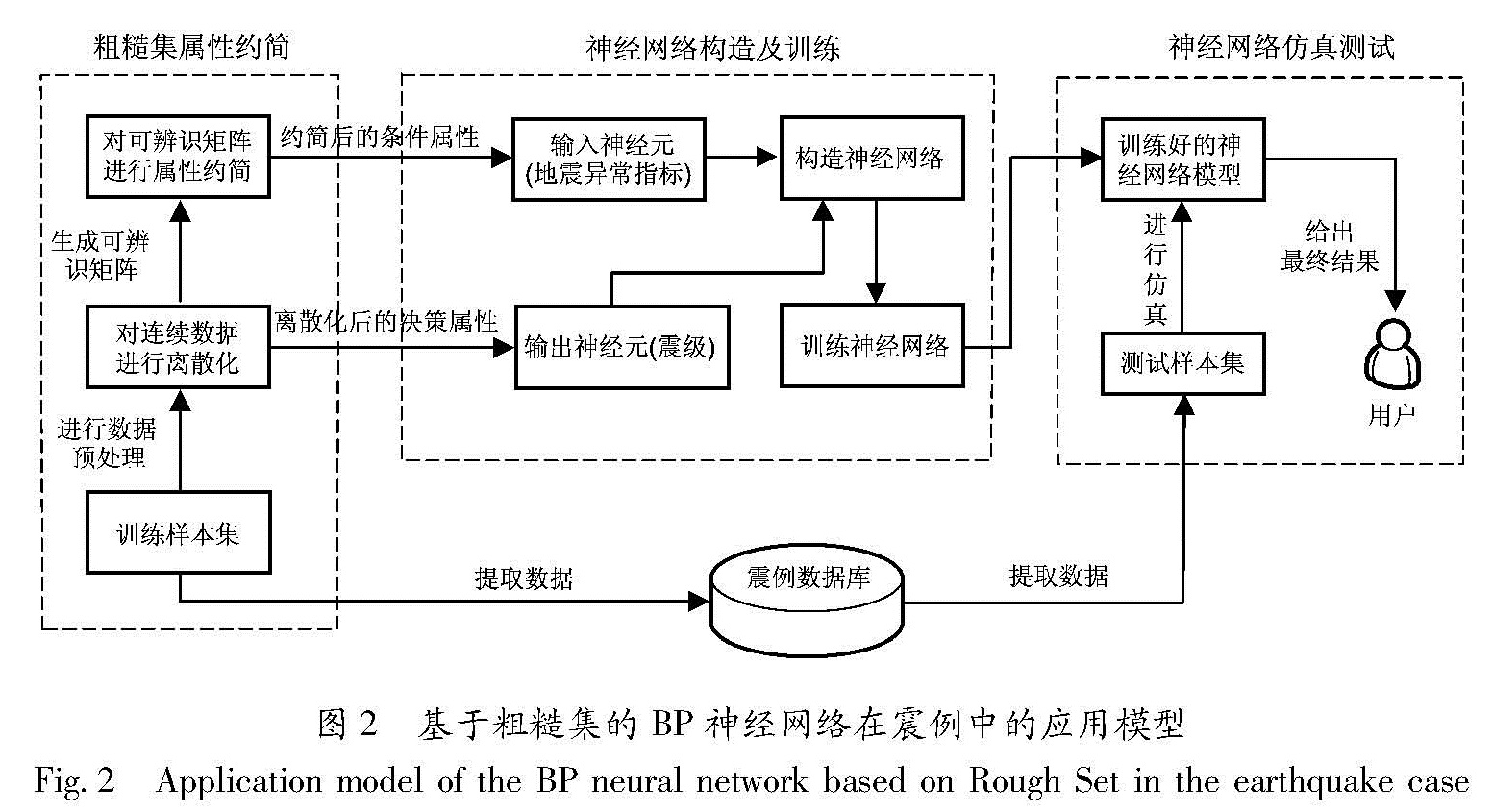
图2 基于粗糙集的BP神经网络在震例中的应用模型
Fig.2 Application model of the BP neural network basedon Rough Set in the earthquake case
75%的数据作为训练样本集进行训练,从而建立核心异常指标与震级之间的一种非线性映射关系;(3)神经网络仿真测试模块:调用震例数据库中剩余25%的数据作为测试样本集,使用训练好的BP神经网络进行仿真测试,尝试对震级进行预测。
《中国震例》(张肇诚等,1988,1990a,b,1999,2000; 陈棋福等,2002a,b,c,2008)收录了1966~2002年中国大陆发生的所有5.0级以上地震的震例研究报告,后又增补了4条4.5~4.9级的地震震例,书中对每条震例的地震基本参数及震前异常等都做了详细分析和总结,是迄今为止国内最完整、最丰富的震例资料,是地震预测研究和探索地震规律的重要科学资料。在一些学者关于震例的研究中,已有很多重要的理论成果(付虹等,2008; 蒋海昆等,2009)
异常和地震的关系可归纳为4种:1.异常出现,有地震发生; 2.异常未出现,有地震发生; 3.异常出现,无地震发生; 4.异常未出现,也无地震发生。这4种关系可以描述为以下4种情况:A.从异常出现层面来说,1和3构成理论上的完备集; B.从地震发生层面来说,1和2构成理论上的完备集; C.从异常未出现层面来说,2和4构成理论上的完备集; D.从无地震发生层面来说,3和4构成理论上的完备集。其中,4无有用信息,包含4的C和D在实际研究中价值不大。2和3的情况很常见,也正是造成大量“漏报”(报无实有)和“虚报”(报有实无)的原因(吴绍春,2005)。完整意义下的研究应该是A和B的总和,但是由于3的缺失或不完备使得A成了实际上的不完备集,所以无法开展研究。因此本文的研究只针对B。
本文对《中国震例》中记载的209条震例的异常信息进行详细整理,按观测手段统计:测震学异常指标共计74项,前兆异常指标共计84项。经整理分析和统计归纳,最终得到异常指标共106项,其中测震学指标41项,前兆指标65项,详细信息如表1所示。

表1 地震异常指标详表
Tab.1 Detailed table of seismic anomaly indicators
异常种类多少及其持续时间是研究问题的两个关键因素。异常的数量,可直接相加求得,但异常持续时间则无法直接获取。本文根据每条震例中异常的出现情况,通过统计其起止时间进行赋值。以SAIi(Seismic Anomaly Indicator)来表示第i项异常指标,用Ti来表示第i(i=1,2,…,106)项异常指标的持续时间,单位为月。分以下3种情况来讨论:
(1)异常未出现:如果某个地震之前,某项异常未出现,也就是书中未记载该项异常信息,那么其对应的T赋值为0。例如:“1975年2月4日辽宁海城7.3级地震”,未出现指标“应变释放”SAI8异常,因此,笔者给SAI8赋值为T8=0。
(2)某项异常只在单测点出现:某次地震之前,只有一个测点出现异常,T取该异常的持续时间。例如:“1976年4月6日内蒙古和林格尔6.3级地震”,1962年5月至1973年4月在和林格尔地区(300×400)km2范围内应变释放出现加速密集异常现象,起止时间共计132个月。因此,笔者给第15号震例的属性SAI8“应变释放”赋值为T8=132。
(3)某项异常同时出现在多个测点:某次地震之前,也可能存在某项异常同时在多个测点出现的情况。对于这种情况,异常持续时间如何赋值是个关键问题,因为在构造BP网络时,要把异常持续时间作为输入,如果处理不得当,会直接影响BP神经网络的结构,从而得不到理想的结果(王炜等,2000; 刘悦,2008)。本文采用加权求和法来解决以上问题,即把该异常出现在各测点的持续时间进行加权求和。假设某次地震前,某项异常指标SAIi(i=1,2,…,106)在多个测点j(j=1,2,…,n)均出现,则SAIi的持续时间Ti可定义为
Ti=∑nj=1ωjtij.(2)
其中,tij表示第i项异常指标在第j个测点的持续时间,ωj为权值,定义如下:
ωj=tij〖JB<2/〗∑nj=1tij.(3)
将式(3)带入式(2),可得
Ti=∑nj=1(tij〖JB<2/〗∑nj=1tij)tij=(∑nj=1(tij)2)/(∑nj=1tij).(4)
例如:“1973年2月6日四川炉霍7.6级地震”的“地震频度”指标(SAI11)在两个测点均出现了异常,分别持续了2个月和20个月。因此,根据式(4),可计算该震例的异常SAI11持续时间为T11=18.36。
由于粗糙集方法不能直接处理连续属性,因此需要先把震级进行离散化处理,本文选择等距离离散法将震级划分,如表2所示。

表2 震级离散化
Tab.2 Magnitude discretization
(1)论域
由于异常指标共106项,数据量繁多,如果直接进行处理,可能会降低约简算法的执行效率。鉴于测震和前兆是相对独立的研究体系,本文将震例数据分为测震学指标和前兆指标,并分别构造可辨识矩阵来进行约简。去除测震学指标中震前无任何测震异常的7条震例,剩余的202条震例信息构成研究测震学指标的论域。同理,对于前兆指标,去除震前无任何前兆异常的17条震例,剩余的192条震例信息构成研究前兆指标的论域。
(2)条件属性
《中国震例》记载的每一条震例中,很多异常指标可能是震后通过研究认识到它与地震的关系后加上去的。根据目前的资料已无法分辨哪些异常是震前确实存在,并且被地震工作者识别到的; 哪些异常是震前确实出现了,但无法断定是否是异常; 哪些异常是震后通过总结追加上去的。因此本文约定:无论哪种情况,凡是在某条震例记载中出现的异常指标,在决策表的条件属性中都表示为1,未在震例记载中出现的则为0。
(3)决策属性
如果决策属性以“地震是否发生”来赋值,每一条震例的决策属性都是1,就起不到决策作用。考虑到本文研究的是震前异常出现的种类多少、持续时间与震级的关系,所以选择震级的大小作为决策属性。
综上所述,就测震学指标而言,论域为202个震例,条件属性为41个测震异常,决策属性为震级。根据条件属性的取值,每条震例可描述为一个由41个“0或1”组成的序列。那么,202个震例就对应202个序列,可根据式(1)生成测震学指标的可辨识矩阵,即(202×202)阶的矩阵,如表3所示。同理,对于前兆指标,论域为192个震例,条件属性为65个前兆异常,决策属性为震级,也可按上述原理生成前兆指标的可辨识矩阵,即(192×192)阶的矩阵。

表3 测震学异常指标的可辨识矩阵
Tab.3 Discernibility matrix of seismometry anomaly indicators
根据算法1,逐项扫描可辨识矩阵,对于重复项只保留其中一项。检索可辨识矩阵中只含有一个属性的项即核属性Core,将其加入约简RED,并删除可辨识矩阵中含Core的所有项。若可辨识矩阵已为空,则RED就为最终所求的约简,若不为空,则计算剩余属性的重要性,依重要性排序,依次将目前最重要的属性Csig加入到RED,并删减掉包含Csig的所有项,直到矩阵为空为止。
对测震学指标的可辨识矩阵进行约简,最终得出测震学指标的核属性依次为:06、11、10、02、08、25、16、37、12、04、01、15、14、20、39、09、21、17、34、19、31、22。然后将包含这些核属性的矩阵项约简后,矩阵为空,算法结束,以上的核属性即为所求的约简RED。整理可得经过粗糙集属性约简后的核心测震学异常指标如表4所示。
同理可对前兆指标的可辨识矩阵进行分析,得到的核属性依次为:33、03、64、09、44、18、19、29、16、10、02、11、01、25、27、17、28,将它们存入RED,并将包含这些核属性的矩阵项约简后,矩阵仍不为空。然后,计算剩余属性的重要度Csig,依重要度递减排序,按照排序继续进行约简,直到矩阵为空,该算法结束。又加入到RED的属性有:22、26、43、38、21、49、31。整理可得经过粗糙集属性约简后的核心前兆异常指标如表5所示。由表4、表5可知,使用基于粗糙集属性约简的方法后,最终得出46项核心指标,其中测震学分类22项,前兆分类24项。整理所有经过粗糙集属性约简后的震例信息,即对每条震例记录中冗余信息进行删减,只保留46项核心异常指标。

表4 约简后的测震学异常核心指标
Tab.4 Core indicators of seismometry anomaly after reduction

表5 约简后的前兆异常核心指标
Tab.5 Core indicators of the precursory anomaly after reduction
(1)样本选择
调用经过粗糙集属性约简得到的核心属性的震例数据,将其中的 162条震例(约占总样本数的75%)作为训练样本,其余的40条震例(约占总样本数的25%)作为测试样本,在MATLAB R2007a环境下构造BP网络模型。
(2)归一化与反归一化
由于隐含层中的神经元选用Sigmoid型传递函数,所以在构造神经网络之前,先将训练样本归一化,使各样本元素的值为[0,1],这样才能确保网络对样本具有足够的输入敏感性和良好的拟合性。训练好的BP网络模型对测试样本进行仿真之后,需对仿真结果进行反归一化得到实际的震级。本文选用的归一化与反归一化方法如式(5)和式(6)所示。
X^=(X-Xmin)/(Xmax-Xmin),(5)
X=Xmin+X^(Xmax-Xmin).(6)
(3)BP神经网络的构造、训练及仿真测试
神经网络构造的主要工作是确定神经网络的层数和各层的神经元数目。输入神经元使用粗糙集属性约简后得出的46项核心指标,包括测震指标和前兆指标; 输出神经元即震级大小。
将训练样本以矩阵的形式导入神经网络模型,本文训练样本集共有162个样本,因此,该神经网络的输入为一个(46×162)阶矩阵,输出为一个(1×162)阶矩阵。在MATLAB R2007a环境下,建立了BP神经网络模型进行训练,如图3所示。
本文中测试样本集共有40个样本,因此,输入为一个(46×40)阶矩阵,输出为一个(1×40)阶矩阵。在Matlab环境下,将测试样本以矩阵的形式导入训练好的BP神经网络模型进行仿真测试。

图3 MATLAB下建立BP网络模型
Fig.3 BP neural network model based on MATLAB software
经过反复实验并对比多次实验的结果,得到以下结论:当隐含层神经元数设为20,训练误差设为0.01时,训练得到的BP神经网络结构最佳。用测试样本进行仿真实验,误差结果如图4所示。用来仿真实验的40个测试样本中,除了2个样本的震级差略大(图中以圆圈表示),其余样本的震级差都小于0.5(图中虚线之间部分)。
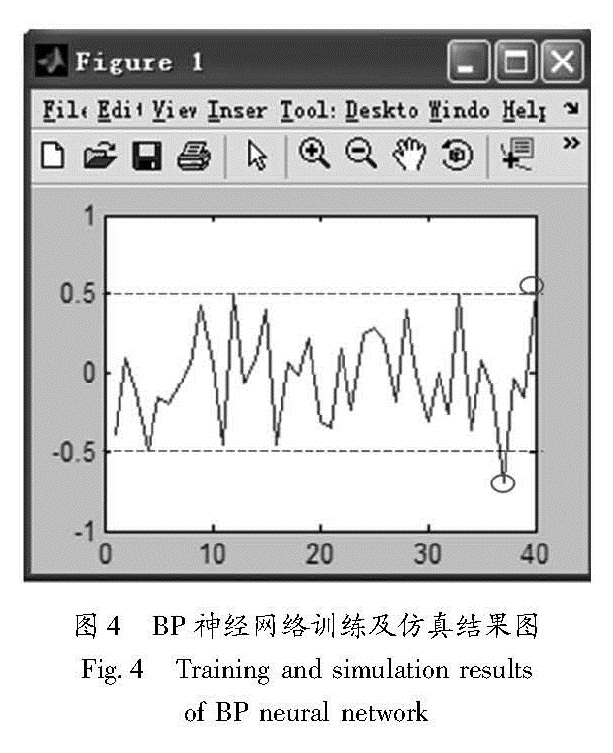
图4 BP神经网络训练及仿真结果图
Fig.4 Training and simulation results of BP neural network

表6 误差结果对比
Tab.6 Contrast of error results
前人使用神经网络进行地震预测的研究中存在以下两个问题:
(1)样本量小。蔡煜东等(1993)、杨居义和易永宏(2008)、陈一超等(2008)、陈以等(2011)仅选用部分区域的部分震例进行研究。如:选用云南滇西南地震区的17条震例资料作为研究样本。再如:王炜等(2000)选用大华北地区1975年至1998年7月发生5级以上的32条震例资料作为研究样本。选择小量样本进行研究,可能会导致研究结果以面概全,不够客观和全面。
(2)人为选择异常指标作为输入。蔡煜东等(1993)、王炜等(2000)、杨居义和易永宏(2008)、陈一超等(2008)、陈以等(2011)通常根据经验或简单的数理统计,对神经网络模型的输入人为进行选择。这种做法可能会使得整个研究过程不够客观和全面。
本文选用目前能够收集到的最完整的震例数据作为研究样本,以便在大量震例研究的基础上提取共性特征,使得研究结果更具普适性。然后提出了一种基于粗糙集的神经网络在震例中的应用模型,实现了用粗糙集属性约简算法来自动筛选核心地震异常指标,最后通过BP神经网络建立核心异常指标与地震震级之间的一种非线性映射关系,尝试对地震震级进行预测。实验结果如下:
(1)对《中国震例》中记载的209条震例的异常信息做了详细整理,最终得到异常指标共106项,其中测震学指标41项,前兆指标65项,构成了进行震例研究的较完备样本集。
(2)使用基于粗糙集属性约简的方法,从106项异常指标筛选出了46项核心指标,其中测震异常22项,前兆异常24项。这46项中囊括了前人经验研究中常使用的异常指标,如测震学异常指标中的地震条带、应变释放、b值和波速比等,前兆异常指标中的短水准、地倾斜、电位、水氡、水位等。这些指标可以从众多指标中通过粗糙集属性约简算法被自动筛选出来,足以证明该算法在解决此问题上的科学性和正确性。另外,该方法还筛选出了:前震活动、地震迁移、地震平静、地震活动增强等有关地震时空分布方面的属性; 以及小震调制比Rm、断层面总面积∑(t)值、地震活动性指标、η值、GL值、振幅比等异常指标; 形变学科中的重力、钻孔应变,电磁学科的电阻率、地磁低点位移、地磁Z、D、F,以及流体学科的气温、水温、硫化氢等异常指标。根据粗糙集属性约简算法的特性,得出的核心属性都是对最终分类起决定作用的。因此在今后的研究中,这部分异常指标的使用值得引起足够重视,将它们合理地应用到实际的地震预测研究中,可能会得到更客观、更全面的结果。
(3)最终预测的震级与实际的震级误差基本控制在-0.5~0.5(即不超过0.5级),结果基本符合地震预测精度要求。因此,使用粗糙集与神经网络相结合的方法对震级进行预测研究是行之有效的。今后,还可尝试使用数据挖掘中的聚类分析、关联规则、支持向量机等算法对核心异常开展进一步的探索研究。
本文的撰写得到山东师范大学信息科学与工程学院段会川教授的悉心指导,在此表示诚挚感谢!
