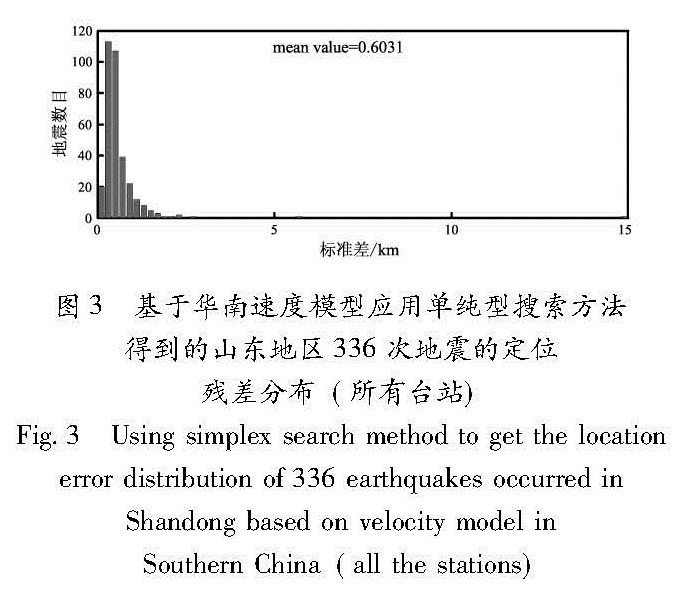
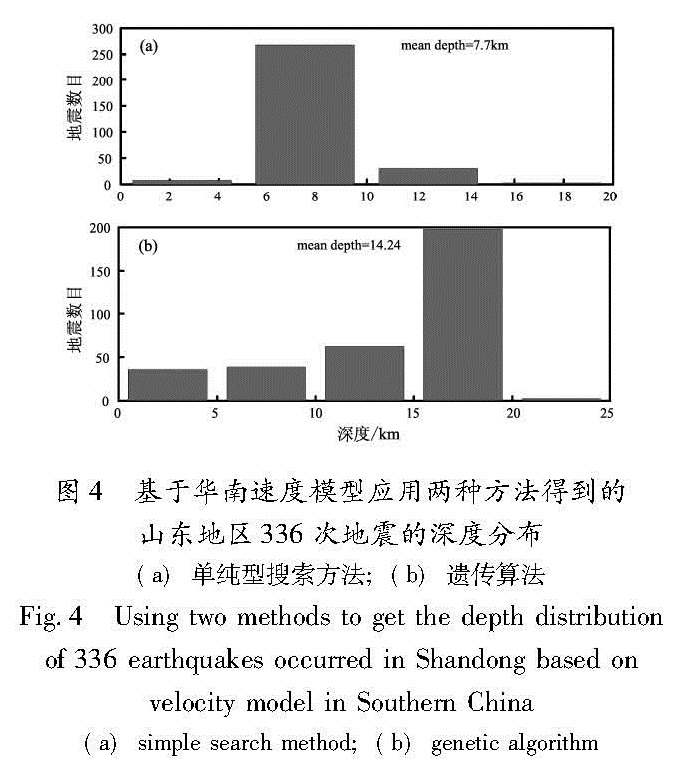
为了提高地震定位精度和计算速度,本文采用了一种利用走时残差和到时残差的绝对值极小值作为目标函数的方法,对遗传算法中的参数,
图1 基于不同模型得到的山东地区336次地震的定位残差分布(所有台站)(a)J-B模型;(b)IASPI91模型;(c)滕吉文模型; (d)华南速度模型
Fig.1 Location error distribution of 336 earthquakes occurred in Shandong based on different models(all the stations)(a)J-B model;(b)IASPI91 model;(c)Teng Ji-wen model;(d)velocity model in Southern China
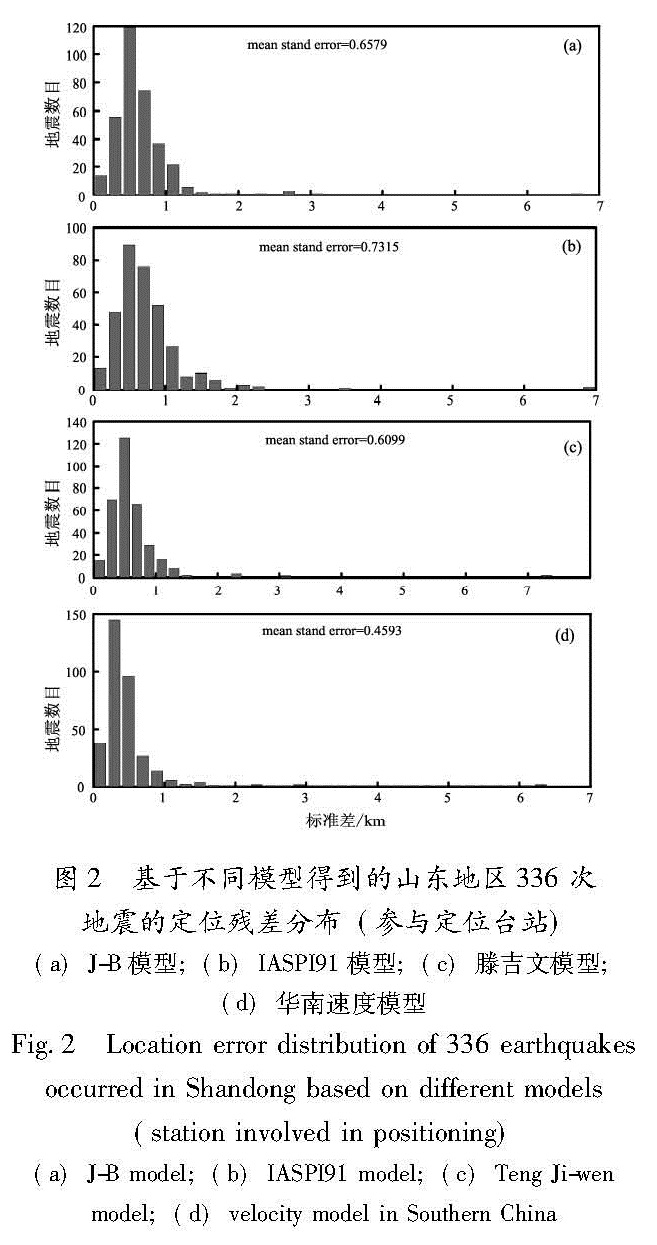
图2 基于不同模型得到的山东地区336次地震的定位残差分布(参与定位台站)(a)J-B模型;(b)IASPI91模型;(c)滕吉文模型; (d)华南速度模型
Fig.2 Location error distribution of 336 earthquakes occurred in Shandong based on different models (station involved in positioning)(a)J-B model;(b)IASPI91 model;(c)Teng Ji-wen
model;(d)velocity model in Southern China如各种适应度函数、变异概率进行了对比分析,同时考虑了地震定位计算中的一些约束条件。
4.1 目标函数选择
遗传算法在地震定位过程所用到的目标函数为
φ(k)=∑mi=1(Oi(k)-Ti(k))2,
i=1,2,…M; k=1,2,…Q.
(5)
式中,M表示未知变量; Q表示种群个数。应用理论到时和观测到时差的平方和作为判断误差的标准。
地震定位会受到发震时刻与震源深度间强烈的折中关系及反演问题的非线性影响,为从根本上解决该问题,根据高星等(2002)的研究结果,笔者采用种利用走时残差和到时残差的绝对值极小值作为目标函数的方法,基本函数表示为
E(r,T0)=E1(r,T0)+E2(r).(6)
式中,E(r,T0)就是传统所选的目标函数,可具体表示为
E1(r,T0)=∑Nj=1|Wjdtj|p.(7)
式中,dtj=(Tj-T0)-τj(r)。其中,Tj是第j个地震台站P波至到时; T0为发震时刻; τj(r)表示假定地震震源位于r时的理论走时; N为台站总数; Wj为加权因子; p一般取2。
E2(r)函数可表示为
E2(r)=∑N2|Wj[(Tj-T1)-(τ1(r))]|p.(8)
式中,T、τ下脚标1表示P波到时最小时所对应的台站。可见,E2(r)与发震时刻无关。
定位问题中采用的目标函数E(r,T0)的优点在于发震时间与震源深度之间折中关系对定位结果的影响被减弱了。
4.2 适应度函数选择
最常用的适应度函数有3种,第一种是用线性函数表示为
Pr=a-bφk.(9)
式中,b=Q-1(φmax-φavg)-1,a≥b·φmax.
第二种用幂函数表示为
Pr=φck.(10)
式中,c=1.005.
第三种用指数函数来表示为
Pr=Aexp(-Bφk).(11)
式中,B=(φQ)-1, A=[∑Miexp(-Bφi)]-1.其中,φmax、φavg和φσ分别是目标函数的最大值、平均值和标准差。据系数Pr的大小,采用轮盘赌的概率选择方法,选择Q个个体组成新的种群,就完成了繁殖过程。
选取合适的适应度定标方案非常重要。在一般情况下,模型是由多个参数组成的。先将模型的每一参数编成一个二进制子串(基因),然后将这些子串串联成一个二进制串(染色体)。
经过对比筛选,本文选择线性适应度函数来实现遗传算法中的个体选择。函数为
f(k)=φmax-Q-1(φmax-φavg)-1φ(k).(12)
其中,Q为种群个数; φmax、φavg和φσ分别是目标函数φ的最大值、平均值和标准差。
4.3 变异概率选择
遗传算法的变异概率是改善遗传算法收敛情况的一个重要因素。由于变异只是遗传算法收敛过程中的一个小扰动,Sambridge和Gallagher(1993)提出了在基因的各个位分配不同的变异概率,高位码的变化导致参数变化较大,应分配较小的变异概率,低位码则应分配较大的变异概率。在遗传算法的初始阶段应在较大参数空间内搜索,可给以较大的变异概率,而在遗传算法的最后阶段己找到全局较优解,可给以较小的变异概率。根据这一思路,万永革等(1997a,b)给出了按迭代次数线性或指数下降的变异概率。结果表明,根据随迭代次数线性变化的变异概率比Sambridge和Gallagher(1993)采用按码位线性变化变异概率所得到的最小拟合差下降曲线的更平稳。随迭代次数指数变化的变异概率的最小拟合差在开始阶段和后面的阶段得到的最优解都比Sambridge和Gallagher(1993)采用按码位指数变化变异概率有所改善。平均拟合差在初始阶段的下降不如按码位指数变化变异概率,但在最后阶段比按码位指数变化变异概率的收敛情况要好。
设变异概率用Pm表示,变异概率初值用Pms表示,变异概率终值用Pme表示,迭代次数用n表示,最大迭代次数用N表示,则按迭代次数计算的线性变异概率表示为
Pm(n)=Pms-n*(Pms-Pme)/N.(13)
指数变异概率表示为
Pm(n)=exp(lnePms-n*(lnePms-lnePme)/N.(14)
按码位计算线性变异概率和指数变异概率时只是将迭代次数用n和最大迭代次数N分别用码位更换即可。
本系统采用的交配概率Pc=0.9; 变异概率按码位线性衰减变化,变异概率Pm的变化范围为0.1→0.001,即Pms=0.1,Pme=0.001。最大迭代次数为200次左右。
4.4 定位参数的初始选择
地震发生的最大经度范围是110.0°~125.0°E,搜索步长因子是1/212; 最大纬度范围是30.0°~42.0°N,搜索步长因子是1/212; 最大震源深度范围为0~20 km,搜索步长因子是1/211; 发震时间的最大范围为0~50 s(相对于第一个台站P波到时),搜索步长因子是1/211。台站和地震地理坐标与直角坐标变换的参考点为(36°N,118°E)。
当地震事件触发报警后,要对定位参数范围做进一步约束,地震初始震中位置选定为第一个台站的经纬度位置(Lat1,Lon1),纬度变化范围为
Lat∈[Lat1-1.2·Vφ(S^--P^-),Lat1+1.2Vφ(S^--P^-)].(15)
经度变化范围为
Lon∈[Lon1-1.2·Vφ(S^--P^-),Lon1+1.2Vφ(S^--P^-)].(16)
地震发震时刻(相对于第一个台站的P^-到时)的初值采用以下方法得到:
T=a(S^--P^-).(17)
式中,S^-、P^-表示第一个台站的直达波到时,a=Vφ/VP^-(Vφ表示虚波速度,VP^-表示平均速度),发震时刻的初始变化范围限制在0.8T~1.2T之间。
当触发报警的台站记录震相缺乏S^-波震相时,则根据震中近似位于以两个台站为焦点的双曲线上的规律,利用前三个台站P^-到时初步确定震中位置。若3个台站两两相交的双曲线交点集中于1个点时,即(Elat,Elon),则纬度变化范围设定为Lat∈[Elat-0.5,Elat+0.5],经度变化范围为Lat∈[Elon-0.5,Elon+0.5]。若3个台站两两相交的双曲线交点集中于多个点或无交点时,则从P^-波到时最先到达的前4个或5个台站中选取空间分布线性度最差的3个台站再按照上述方法初步确定震中位置。若任何3个台站的组合都出现双曲线交点集中于多个点或无交点时,则纬度变化范围设定为Lat∈[Elat-3,Elat+3],经度变化范围为Lat∈[Elon-3.5,Elon+3]。