收稿日期:2012-03-07
基金项目:国家科技支撑计划项目专题五(2012BAK19B04-05)资助.
基金项目:国家科技支撑计划项目专题五(2012BAK19B04-05)资助.
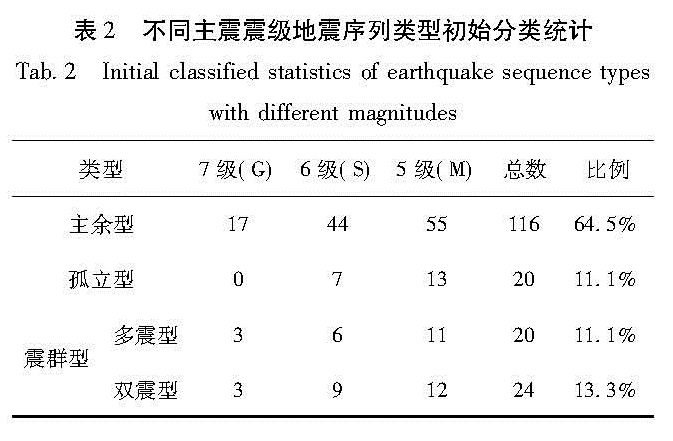
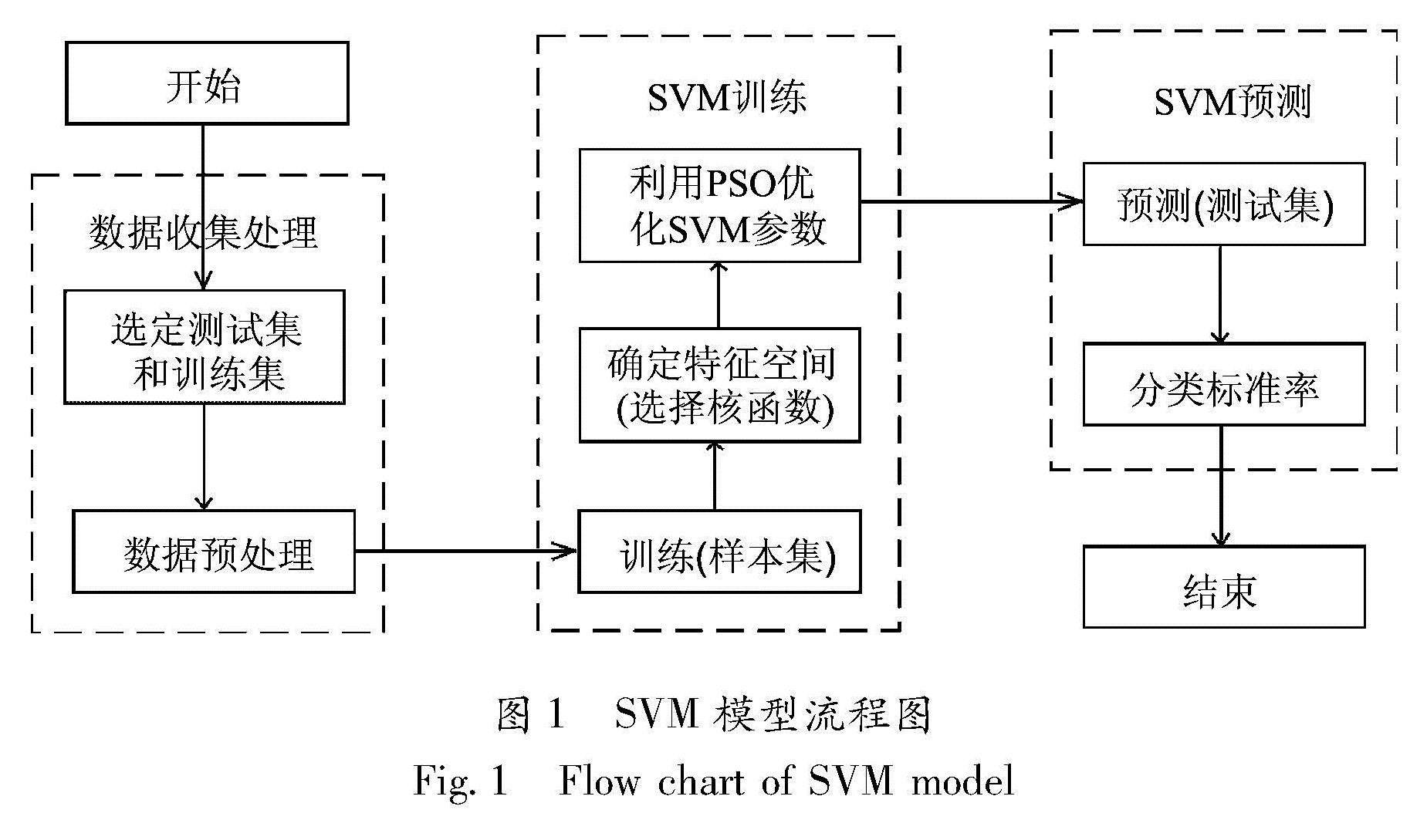
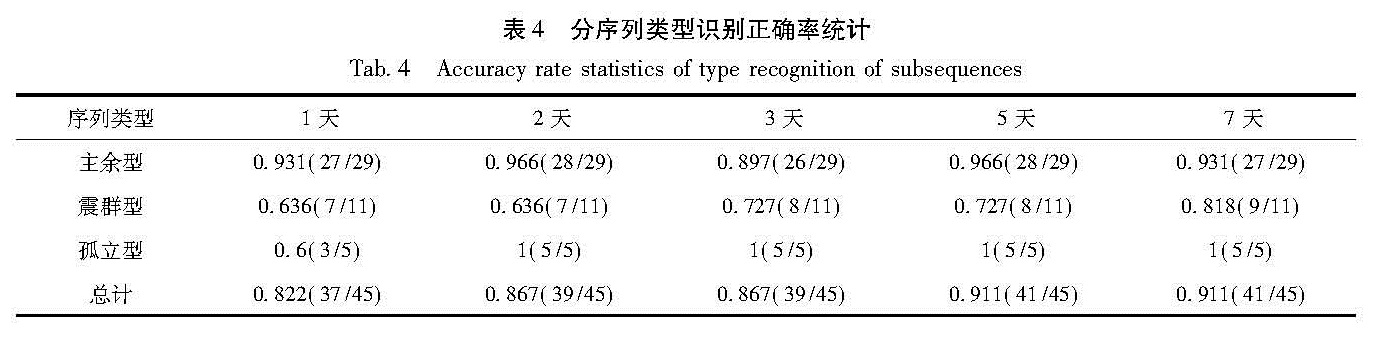
在Matlab环境下,通过构造SVM,建立地震序列特征参数与序列类型之间的一种非线性映射关系对地震序列类型进行早期分类预测。依据我国1970年以来的MS≥5.0地震序列资料,使用SVM对震后1、2、3、5、7天5个时间尺度的地震序列类型进行早期预测,识别效果较好,处理速度快,具有较强的实用性。
In the environment of Matlab, we construct Support Vector Machine(SVM)to build a kind of nonlinear mapping relationship between seismic sequence characteristic parameter and sequence type, and do the early predictions of earthquake sequence types. On the basis of MS≥5.0 earthquake sequences in China since 1970, we divide the data in 5 time scales according to one, two, three, five and seven days after the earthquake and apply the SVM to the early predictions of earthquake sequence types. The results show that it achieves good recognition and fast processing speed, and has a strong practicability.