2.1 考虑属性和空间逻辑的灾情数据清洗实现
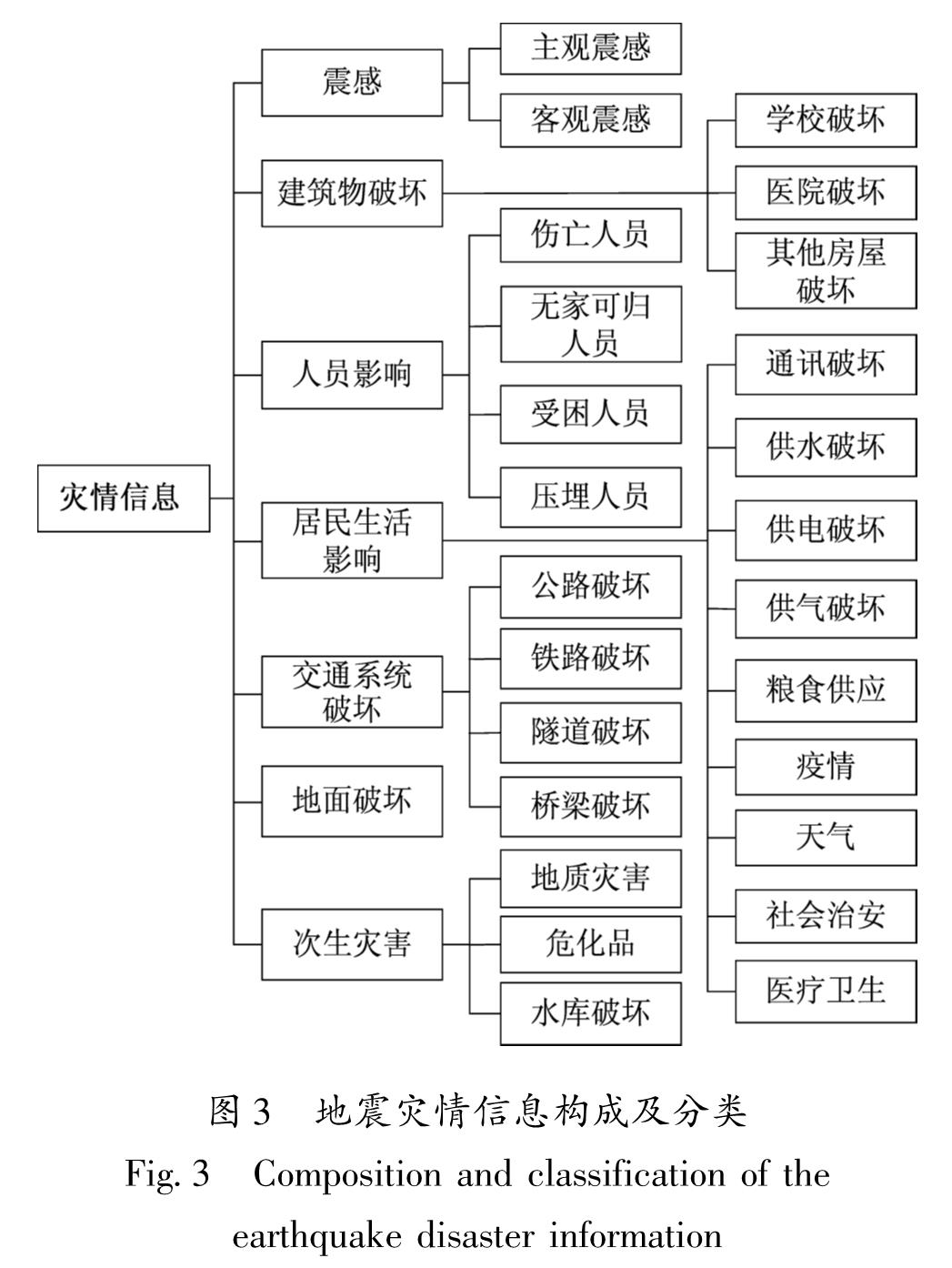
通过整理不同来源的地震灾情数据,可将地震灾情信息分为震感、建筑物破坏、人员影响、居民生活影响、交通系统破坏、地面破坏和次生灾害7大类(陈维锋等,2014),各大类又可细分为对应灾情下的25小类,灾情信息构成及分类如图3所示。
图2 地震灾情数据清洗器业务流程
Fig.2 The processing flowchart of the earthquake disaster data cleaner
图3 地震灾情信息构成及分类
Fig.3 Composition and classification of the earthquake disaster information
2.1.1 考虑属性逻辑
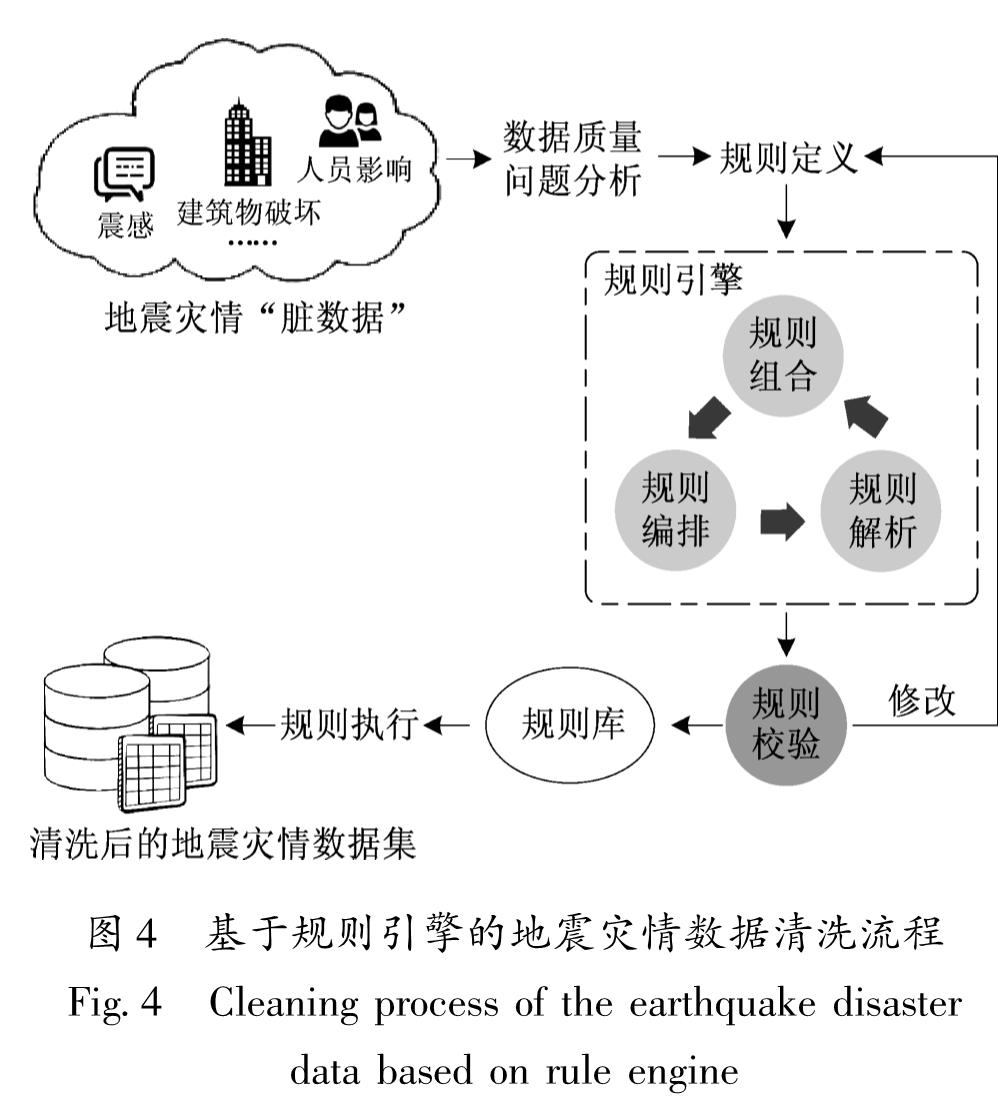
针对数据属性逻辑,采用逻辑分离的清洗框架中基于规则引擎的清洗方法,将逻辑关系通过一系列规则表达后,实现数据清洗,清洗流程如图4所示。首先对源数据集进行质量分析,找出数据存在的质量问题,针对不同的质量问题按照标准的规则编码规范定义数据清洗规则(赵志伟,2018),然后应用规则引擎组合、编排及解析定义的规则,再通过样本数据集校验经规则引擎处理后的清洗规则,根据校验发现的问题对规则进行反复修改,最终形成规则库,通过规则执行实现地震灾情“脏数据”的清洗转换。
图4 基于规则引擎的地震灾情数据清洗流程
Fig.4 Cleaning process of the earthquake disaster data based on rule engine
通过分析历次地震中不同来源的地震灾情信息,笔者发现灾情数据存在的质量问题主要包括关键属性值缺省、字段记录重复、灾情属性值与实际受灾情况不符等,再基于规则引擎的规则编码规范,分别制定数据清洗规则。
(1)关键属性值缺省
应用于地震应急中的灾情信息应具备完整的上报时间、地点、受灾情况等关键属性,若关键属性值缺省则可能失去实际应用的价值,关键属性值缺省的记录经数据清洗后将被剔除。清洗规则如下:
<rule name=" Attribute default" >/关键属性值缺省规则集
<parameter identifier=" Eqdata" ><class>Data</class></parameter>
<java:condition>Eqdata.getByTime(" Time" )=null</java:condition>/时间字段为空
<java:condition>Eqdata.getByLocation(" Location" )=null</java:condition>/地点字段为空
<java:condition>Eqdata.getByDisaster(" Disaster" )=null</java:condition>/灾情字段为空
<java:consequence>Eqdata.deleteDta(); </java:consequence>/执行剔除操作
</rule>
(2)字段记录重复
字段记录重复主要出现在震感类灾情信息中。因部分灾报员在上报震感信息时,除主震震感外,还持续上报了同一地点的余震震感,若两者相同将使记录重复,造成数据冗余的同时,还可能影响对主震震感的总体判断。因此按照时间顺序,对同一次震害事件,按照只保留先上报的主震震感,剔除余震震感的规则进行字段记录重复数据清洗。清洗规则如下:
<rule name=" Record repeated" >/字段记录重复规则集
<parameter identifier=" Eqdata.SubShock " ><class>Data</class></parameter>
<java:condition>Eqdata.SubShock.getByLocation(" Location" )=Eqdata.SubShock.getByLocation(" Location" )</java:condition>/地点字段相同
<java:condition>Eqdata.SubShock.getByDisaster(" Disaster" )=Eqdata.SubShock.getByDisaster(" Disaster" )</java:condition>/震感灾情字段相同
<java:condition>Eqdata.SubShock.getByTime(" Time" )=time1</java:condition>/读取时间字段
<java:condition>Eqdata.SubShock.getByTime(" Time" )=time2</java:condition><java:condition>time1.before(time2)</java:condition>/比较时间先后
<java:consequence>Eqdata.SubShock.deleteDta(time2); </java:consequence>/执行剔除操作
</rule>
(3)灾情属性值与实际受灾情况不符
在接收到的震感、建筑物破坏、交通系统破坏等灾情信息中,存在灾情属性值与实际受灾情况不符的情况,例如同一地点的震感信息为无震感,但建筑物破坏信息中的建筑物破坏属性却为部分破坏,灾情信息间相互矛盾。针对这一问题,郭红梅等(2015)根据中国地震烈度表对人的感觉、房屋破坏及其他震害现象描述建立了地震灾情信息对应关系,如表1所示。表中不同灾情信息对应的灾情属性设计如下:主观震感灾情属性:Ⅰ级:无震感; Ⅱ级:仅仅有感; Ⅲ级:震感强,可行走; Ⅳ级:站立不稳,行走困难; Ⅴ级:被地震摔倒。客观震感灾情属性:Ⅰ级:房屋破坏不可见; Ⅱ级:房屋破坏不易见; Ⅲ级:少数房屋轻微破坏,房屋破坏可见; Ⅳ级:多数房屋轻微破坏,房屋破坏易见; Ⅴ级:多数房屋破坏; Ⅵ级:多数房屋毁坏。建筑物破坏灾情属性:Ⅰ级:完好; Ⅱ级:部分破坏; Ⅲ级:毁坏。交通系统破坏灾情属性:Ⅰ级:通行; Ⅱ级:通行困难; Ⅲ级:中断。
表1 地震灾情信息对应关系
Tab.1 Correspondence relationship of earthquake disaster information
对灾情数据进行融合,即当同一地点的灾情属性值满足表1中某一列的条件时,可通过制定规则检测并修正灾情属性值与实际受灾情况不符的记录。以建筑物破坏灾情信息为例的部分清洗规则如下:
<rule name=" Attribute error" >/属性值与实际不符规则集
<parameter identifier=" Eqdata" ><class>Data</class></parameter>
<java:condition>Eqdata.SubShock.getByDisaster(" Disaster" )=" Ⅱ级" </java:condition>/主观震感灾情属性为Ⅱ级
<java:condition>Eqdata.ObjShock.getByDisaster(" Disaster" )=" Ⅰ级" </java:condition>/客观震感灾情属性为Ⅰ级
<java:condition>Eqdata.Traffic.getByDisaster(" Disaster" )=" Ⅰ级" </java:condition>/交通系统破坏灾情属性为Ⅰ级
<java:condition>Eqdata.Building.getByDisaster(" Disaster" )!=" Ⅰ级" </java:condition>/建筑物破坏灾情属性不为Ⅰ级
<java:condition>Eqdata.Building.modifyDisaster(" Disaster" )=" Ⅰ级" </java:condition>/执行修正操作
</rule>
2.1.2 考虑空间逻辑
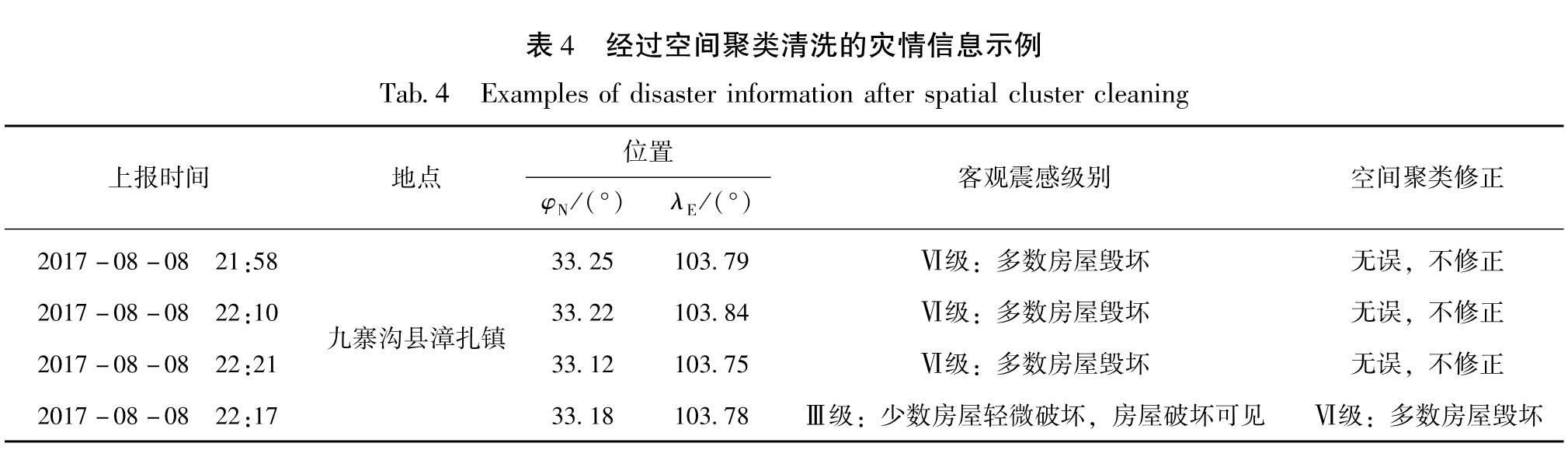
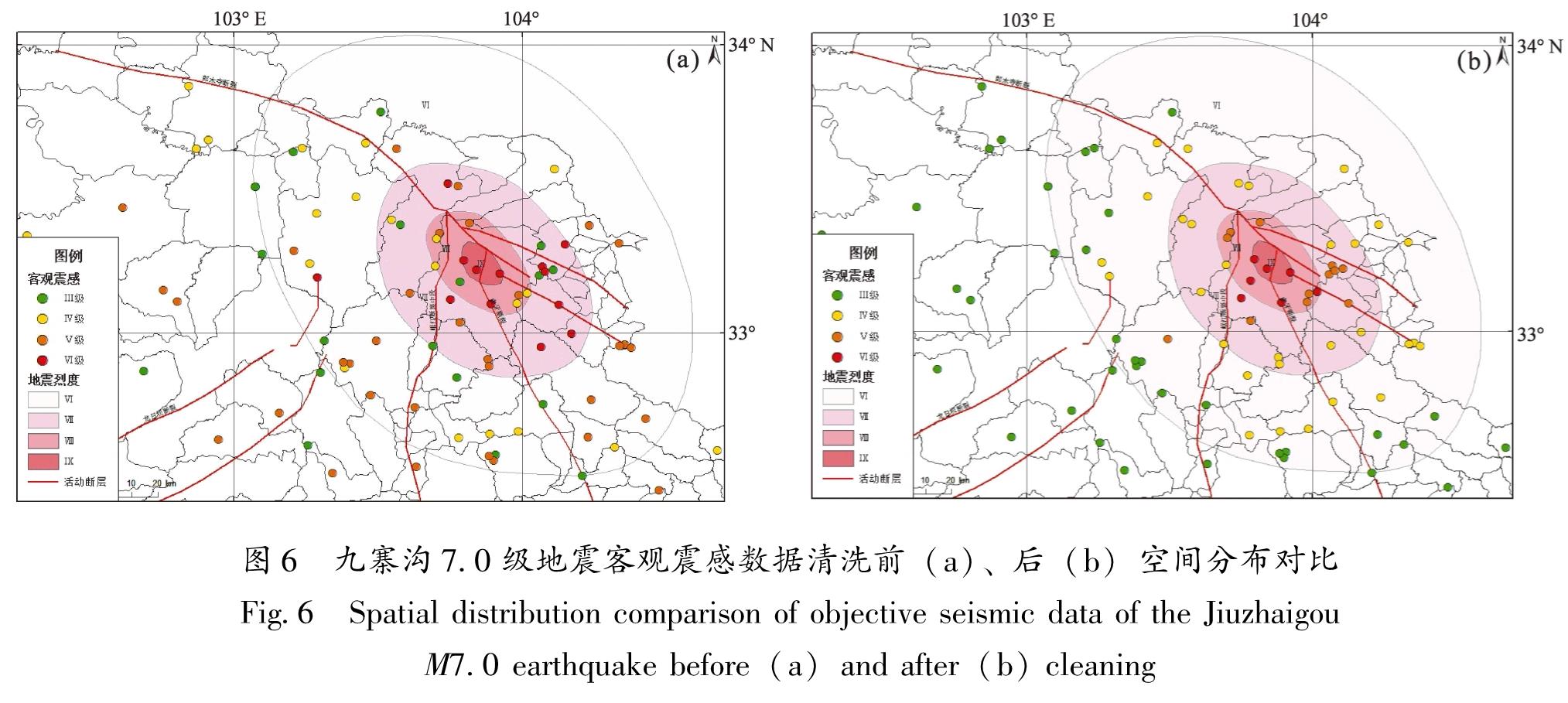
对于具有空间逻辑关系的数据,空间聚类分析方法根据数据的空间分布,将相同或相似属性的数据归入同一集合中,未被归入任何集合的数据为空间离群点,即数据异常点(李明等,2019),从而进一步发现基于规则引擎的方法在进行数据清洗后遗漏的异常孤立点数据。
首先从地震灾情数据中选定需要清洗的灾情数据集X=(x1,x2,…,xn),其中n为灾情数据记录条数,再从中随机抽取k个元组作为k个初始聚类中心点v(0)={v(0)1,v(0)2,…,v(0)k},然后通过公式(1)计算其他数据到初始聚类中心点的欧氏距离(杨俊闯,赵超,2019):
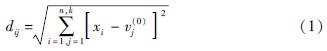
根据最短距离将数据划归到距离最近的聚类中心所在集合中,将通过计算但未被归入任何集合的数据暂时标记为异常点。在全部数据计算完成后,重新迭代计算聚类中心v(l),对数据再次进行归类,直至相邻两次计算的聚类中心间差距达到设定的阈值ε或没有变化为止,将仍未被归入任何集合的数据确定为异常点。算法实现部分关键代码如下:
public class DatacleanCluster {
private int k; //元组个数
private int num; //迭代次数
private List<Double>X; //原始灾情数据集
private List<Point>X=new ArrayList<Point>();
public double getDis(Point x,Point v){return Math.sqrt(Math.pow(x.getX()-v.getX(),Math.pow(x.getY()-v.getY(),2)); } }; //计算其他点到聚类中心点的欧氏距离
public List<DatacleanCluster>cluster(List
<DatacleanCluster>cluster){
for(int i=0; i<num; i++){
Set<Point>center=new HashSet<Point>(); //迭代计算聚类中心
for(int j=0; j<k; j++){
List<Point>
Center=DatacleanCluster.get(j).getMembers();
int size=Center.size();
if(size<3){
Center.add(cluster.get(j).getCenter()); //得到新的中心点
continue; }
if(lastCenter.containsAll(center)){
lastCenter=center;
break; }}}//迭代计算的聚类中心不再变化,退出迭代
for(int ns=0; ns <k; ns++){
noise +=DatacleanCluster.get(ns.getError(); } //得到异常点集合
return DatacleanCluster; }
2.2 主要功能实现
根据系统总体架构及业务流程,笔者设计并实现了考虑属性和空间逻辑的灾情数据清洗器。地震灾情数据清洗器由灾情数据、规则清洗、数据融合、空间聚类、空间展示和系统管理6大功能模块构成。
数据清洗器采用统一的控制界面将各功能模块集成,实现系统主界面菜单、工具栏、数据选项卡、地图浏览窗口等构件的统一布局。系统主要功能实现如下:
(1)规则清洗模块
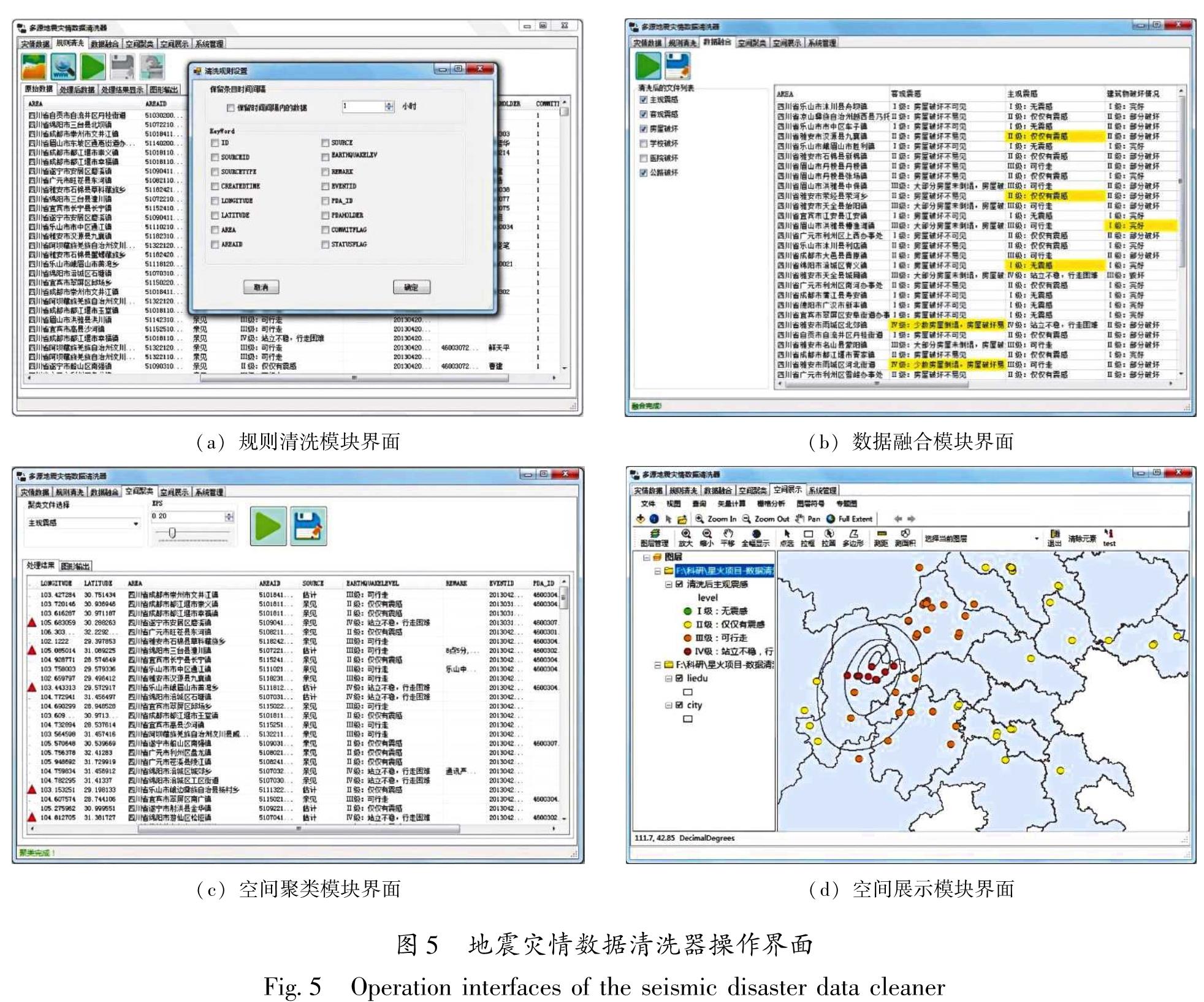
规则清洗模块采用规则引擎制定数据清洗规则,通过清洗规则设置,可对各类灾情数据中存在的关键属性值缺省、字段记录重复等问题进行检测与修正。在处理结果显示和图形输出选项卡中可查看数据清洗条数等详细记录及数据的空间分布情况,操作界面如图5a所示。
(2)数据融合模块
数据融合模块基于中国地震烈度表对人的感觉、房屋破坏及其他震害现象描述所建立的地震灾情信息对应关系,制定融合规则,将经过规则清洗的地震灾情数据进行融合,修正灾情属性值与实际受灾情况不符的记录,经过修正的灾情数据以黄色高亮显示,操作界面如图5b所示。
(3)空间聚类模块
空间聚类模块应用空间聚类分析方法,对通过规则清洗及数据融合初步清洗后的灾情数据进行聚类分析,进一步检测并修正异常的孤立点数据。在聚类文件中选择需要清洗的灾情数据,为使处理结果更符合实际情况,可针对不同的灾情数据设置不同的空间聚类半径。点击清洗按钮后,在处理结果选项卡中可查看聚类分析后的灾情数据,其中对经修正处理的灾情数据进行了标记,操作界面如图5c所示。
(4)空间展示模块
空间展示模块可分级展示选定灾情数据的总体空间分布情况,与导入的烈度圈等矢量数据进行对比,制作输出专题图,并提供基础的矢量计算及栅格分析等空间分析功能,实现灾情信息的可视化,操作界面如图5d所示。
图5 地震灾情数据清洗器操作界面
Fig.5 Operation interfaces of the seismic disaster data cleaner