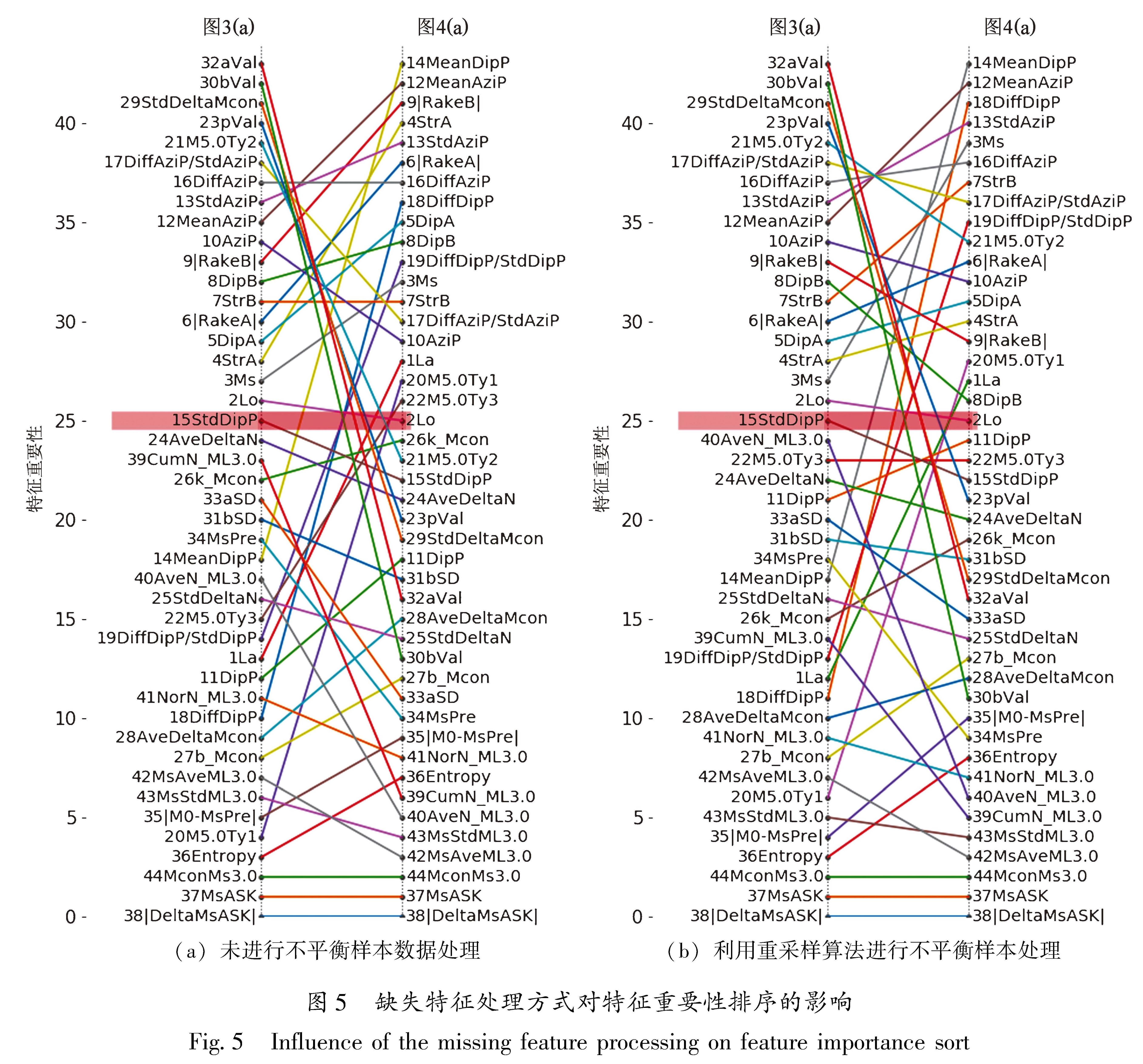
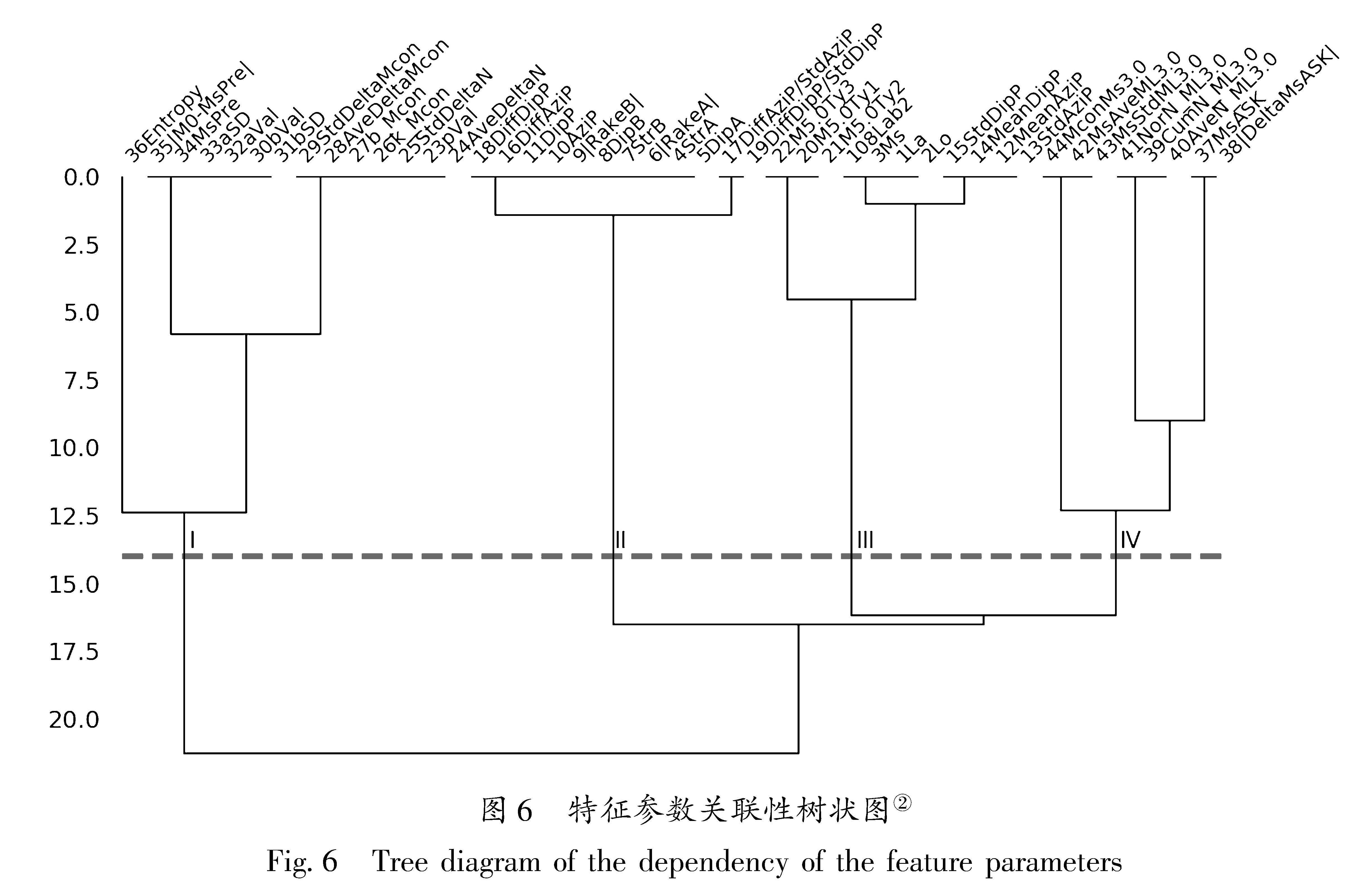
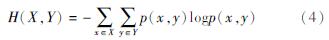2.1 现有地震序列类型判定方法
研究显示,构造和介质不均匀性以及应力水平对地震序列类型有重要影响(Mogi,1962; Takayuki,Hirata,1987; Chen,Knopoff,1987; Ben-Zion,James,1993; Ban-Zion,Lyakhovsky et al,2005; Somerville et al,1999; 苏有锦等,1999; Yamanaka,Kikuchi,2004; Kanamori,Brodsky,2004; 蒋海昆等,2006b; Aochi,Ide,2009; Marone,Richardson,2016; 曲均浩等,2015)。迄今为止尚无完全准确、普适的序列类型判定方法,当前使用较多的主要有定性类比和定量计算两类。震后早期,序列数据尚少,一般只能基于构造及历史地震活动定性类比的方法来判断序列类型; 随着序列地震数据逐渐增多,基于地震目录的序列参数计算结果被用于序列类型判定,依据震后不同时段序列参数变化特征,对序列类型进行定性(变化趋势)或定量(参数统计指标)的判定,例如大森公式p值、h值,G-R关系b值,归一化能量熵,地震震级、频次和应变等参数的变化。
基于地震目录的统计地震学方法在当前地震序列类型判定中发挥着不可替代的作用,而基于数字地震记录的研究结果也得到越来越多的应用。例如震源机制一致性和波形相似性方法就被广泛提及(陈颙,1980; Wiemer,Wyss,2002; 王俊国,刁桂苓,2005),但不同研究者得到的认识有一定差异(崔子健等,2012; 黄浩,付虹,2014)。由于应力降与震后断层面上的剩余应力水平有关,因而应力降或视应力也被尝试用于序列类型判定(陈学忠等,2003; 钟羽云等,2004; 秦嘉政等,2005)、余震区应力水平估计及强余震预测(杜迎春,2000; Baltay et al,2011; 王培玲等,2013; 周少辉,蒋海昆,2017)。需要指出的是,尽管基于地震波的方法因其能够直接获得震源或路径信息而受到重视,但到目前为止,要给出地震序列类型的定量判据仍十分困难,难点首先在于从理论上无法给出不同类型序列“应该”具有的震源特征,仍然只能采用震例统计的方式进行分析,而这又由于已研究样本有限使得结果欠缺统计显著性(Abercrombie,1995; Ide,Beroz,2001; Allman,Shearer,2009),加之中小地震应力降或视应力等震源参数随震级变化(Dysart et al,1988; Trifu,Radulian,1989; 吴忠良等,1999; 赵翠萍等,2011; 华卫等,2012; 周少辉,蒋海昆,2017),更是带来了诸多的不确定性。因而,本文备选特征未包含基于数字地震记录计算的这些震源或介质参数。
2.2 备选特征
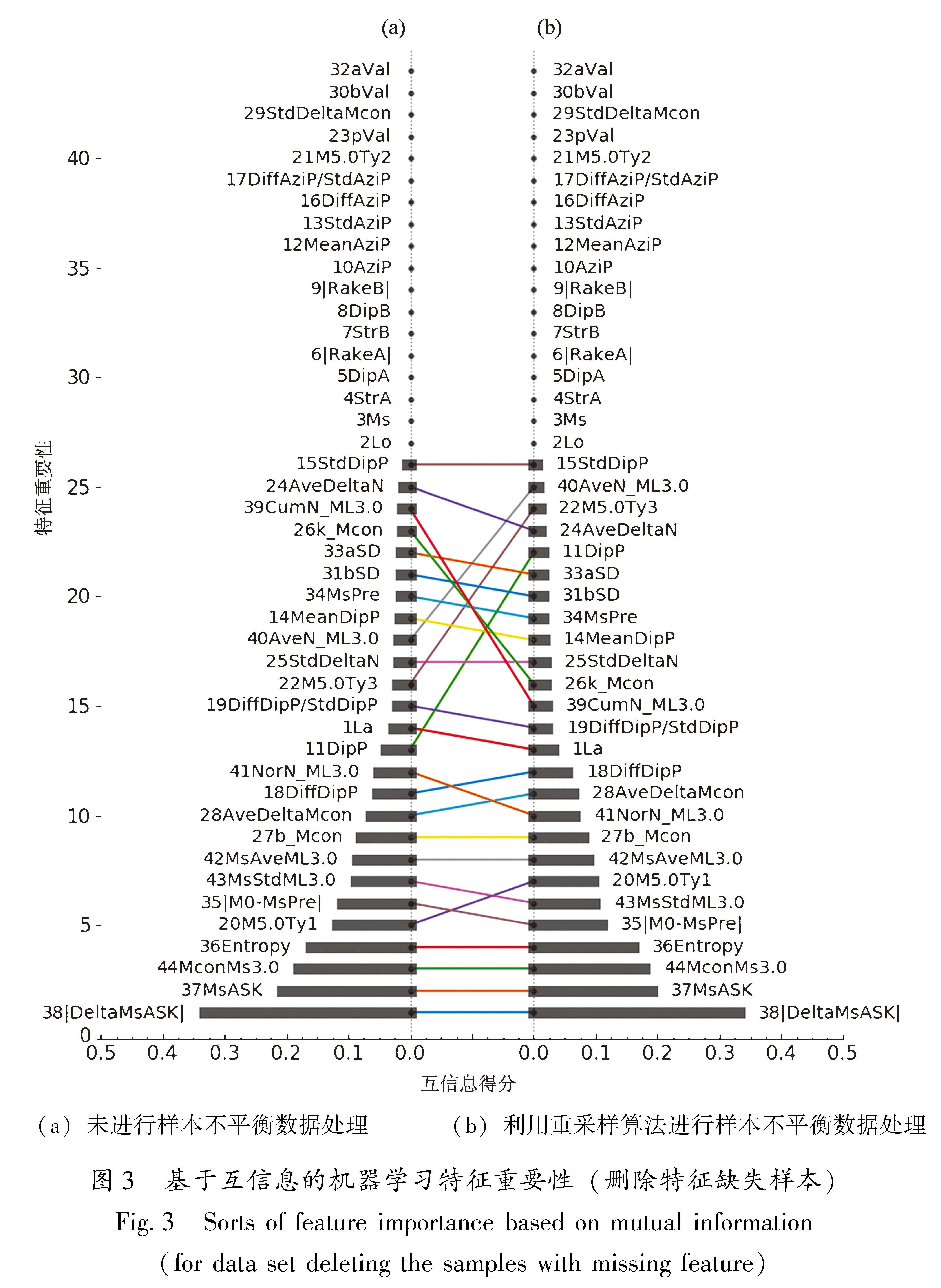
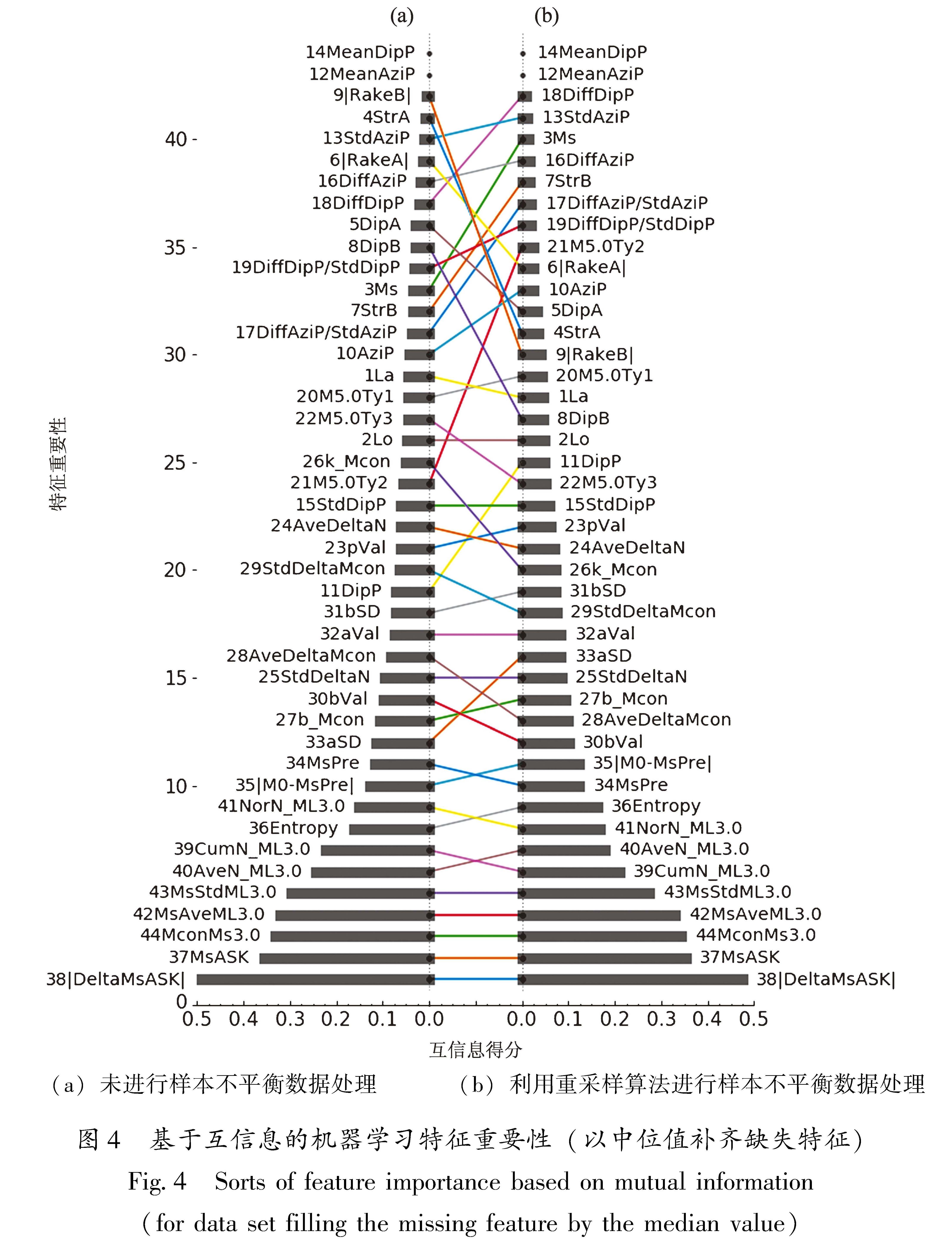
参考现有地震序列类型判定参数和方法,用于机器学习地震序列类型判定的备选特征见表2,主要依据参数来源细分为8类44个备选特征。
表2 机器学习序列类型判定备选特征列表
Tab.2 List of alternative features for judgement of the earthquake sequence types by machine learning
(1)主震相关参数(表2特征1~3)
余震活动强度与主震大小定性正相关,因而余震活动水平与主震大小直接关联(Båth,1965; Helmstetter,Sornette,2003; alohar,2014)。序列类型具有一定的区域特征(刁守中等,1995; 王华林等,1997; 郭大庆等,1998; 蒋海昆等,2006b),结合区域及发震构造特征的历史地震活动类比,可在一定程度提供序列类型判定的参考依据。因而,开展序列类型判定备选特征选择应考虑主震空间位置即经、纬度参数的影响。
(2)主震震源机制相关参数及相对于附近区域平均应力场的偏差(表2特征4~19)
地震序列类型与构造运动或主震破裂形式有一定关系(陈颙,1980; 秦保燕,刘武英,1992; Reasenberg,1999; 苏有锦等,1999; 蒋海昆等,2006b; 张国民等,2010),因而主震震源机制相关参数(表2特征4~11)被纳入作为机器学习的备选特征。考虑导致地震破裂的应力场特征,主震附近区域平均P轴方位角、倾角及其标准差(表2特征12~15),主震P轴方位角和倾角相对于区域平均结果的偏差及离散程度(表2特征16~19)也一并纳入作为机器学习的备选特征。此处的“平均结果”来源于主震附近区域以往地震相关参数的统计,“附近区域”是以主震为圆心、以R为半径的圆域,R与震级MW相关,可粗略地认为等同于主震破裂尺度(Wells,Coppersmith,1994):

式(1)右侧加10为考虑定位误差而人为增加的一个常量(单位:km)。震级标度MS与MW之间采用下式进行粗略转换(Giacomo et al,2015):
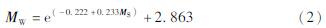
(3)主震附近区域历史地震序列类型相关参数(表2特征20~22)
基于与历史地震序列类型的定性类比,是当前最主要的序列类型判定手段之一(蒋海昆等,2015),表2第20~22行分别为主震附近半径为R的圆域范围内、震级MS≥x地震序列中,多震型、主余型及孤立型所占的比例。与主震震级相关的R由式(1)(2)计算得到,历史地震序列类型基础数据来源于当前正在实时运行并准实时更新的CAAFs系统基础数据(刘珠妹等,2019)。
(4)序列衰减相关参数(表2特征23~29)
序列衰减是余震活动的最主要特征,修改的大森公式n(t)=K(t+c)-p是对余震衰减的最经典描述,衰减系数p分布在0.6~2.5之间,均值为1.1(Utsu et al,1995; Freed,Lin,2001; Scholz,2002; Lyakhovsky et al,2005; 贾若,蒋海昆,2014)。p值与区域地壳介质状况有关(Creamer,Kisslinger,1993; Rabinowitz,Steinberg,1998; Jones,Craven,1990; 曲均浩等,2015),余震衰减还受控于应力状态(Narteau,2009)。在修改的大森公式基础上,刘正荣等(1979)、刘正荣和孔绍麟(1986)提出的 h值方法,在余震跟踪预测中发挥着重要作用。因而,本文为机器学习序列类型判定而构建的备选特征数据集中包含了大森公式相关参数的计算结果(表2特征23~29)。其中特征23为大森公式衰减系数p值; 特征24、25分别为指定时段基于修改的大森公式计算的完备震级以上的理论地震频次与 实际地震频次之差的绝对值及标准差,两者共同表征了修改的大森公式与实际地震频次变化的贴合程度; 特征26为指定时段单位时间折合震级的线性衰减速率(假定为线性衰减),特征27为折合震级线性衰减纵轴截距(ML),特征28、29分别为实际折合震级与线性衰减理论折合震级之差绝对值的平均值及标准差,三者间接表征了序列应变能释放时间衰减特征,以及理论预期相对于实际的偏差。
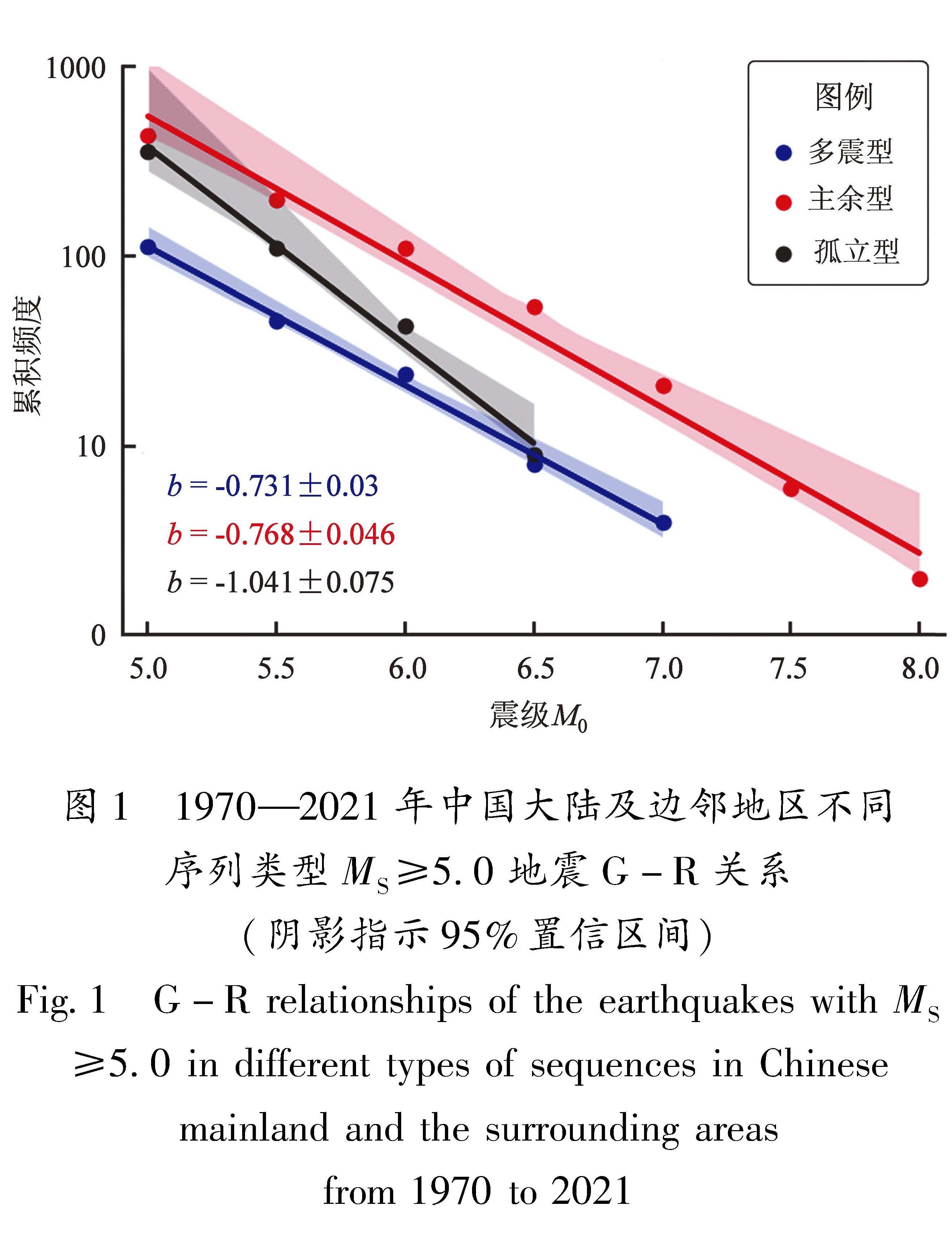
(5)G-R关系相关参数(表2特征30~35)
完整地震序列的震级-频度关系遵循G-R关系LogN=a-bM,比例系数b值介于0.6~1.1之间,与构造及背景应力状态有关(Utsu,2002)。G-R关系相关参数是机器学习地震预测研究中使用最为广泛的一类参数(王锦红,蒋海昆,2023)。表2特征30、31为MLE方法计算的G-R关系比例系数b值及标准差; 特征32、33为G-R关系比例系数a值及标准差(Gulia,Wiemer,2019); 特征34为基于G-R关系外推的最大余震震级,即依据b值截距方法(国家地震局科技监测司,1990; 刘正荣,1995; Shcherbakov et al,2013)估计的最大余震震级,这在当前最大余震震级预测中发挥着重要作用。已有研究显示,震后足够长时间之后,序列G-R关系外推最大余震震级逐渐趋近于真实的最大余震震级(苏有锦等,2014); 特征35为序列主震震级与G-R关系外推最大余震震级之差的绝对值。
(6)归一化能量熵(表2特征36)
归一化能量熵是描述地震序列能量分配均匀程度的一个统计量,反映了序列地震能量分配均匀程度随时间的变化(朱传镇,王琳瑛,1989; 王琳瑛,舒曦,1997)。余震序列性质判定单参数判据的统计研究显示,归一化能量熵具有相对较强的序列分类能力(蒋海昆等,2006a)。
(7)序列地震震级相关参数(表2特征37、38)
余震活动强度与主震大小定性正相关,早期一般认为主震与最大余震震级差ΔM是一个与主震震级无关的常数(平均约为1.2; Båth,1965)。进一步的研究显示,Båth定律并不严格适合所有余震序列,实际ΔM介于0~3之间,受震源机制、震源深度、序列类型、区域构造特征、断层之间相互作用等多种因素的影响(Kisslinger,Jones,1991; Helmstetter,Sornette,2003; 蒋海昆等,2006c,2015; 苏有锦等,2014; alohar,2014; Rodríguez-Pérez,Zúñiga,2016; Apostol,2021),这意味着同等强度主震的余震活动水平可以明显不同。在实际预测应用方面,Shcherbakov 等(2013)、Shcherbakov和Turcotte(2004)提出改进的Båth定律并引入推定最大余震震级对最大余震震级进行估算; 也有研究利用主震震级、余震分布尺度等参数之间的统计关系(蒋海昆等,2007c; 吕晓健等,2010)、震级差(刘蒲雄等,1996)等来对最大余震震级进行估计。基于以上研究,表2特征37、38分别为指定时段最大余震震级、序列主震与该最大余震震级差的绝对值。随震后时间的推移,特征37将趋近于序列最大余震,特征38会趋近于序列主震与序列最大余震震级差ΔM,而ΔM是序列标签的确定依据。
(8)序列地震频次相关参数(表2特征39~44)
已有研究显示,震后不同时段小震频次(王志东等,1982; 陈荣华等,1994)及应变释放(戴英华等,1990)特征一定程度上含有序列的分类信息。据此,表2特征39~41分别为震后指定时段ML≥x小震的累积频次、日均频次及相对于震后首日的归一化频次; 特征42~44分别为ML≥x小震的平均震级、平均震级标准差和折合震级,两者分别从小震频次和震级/应变释放的角度,反映指定时段余震活动的平均水平以及震级分布的离散程度。