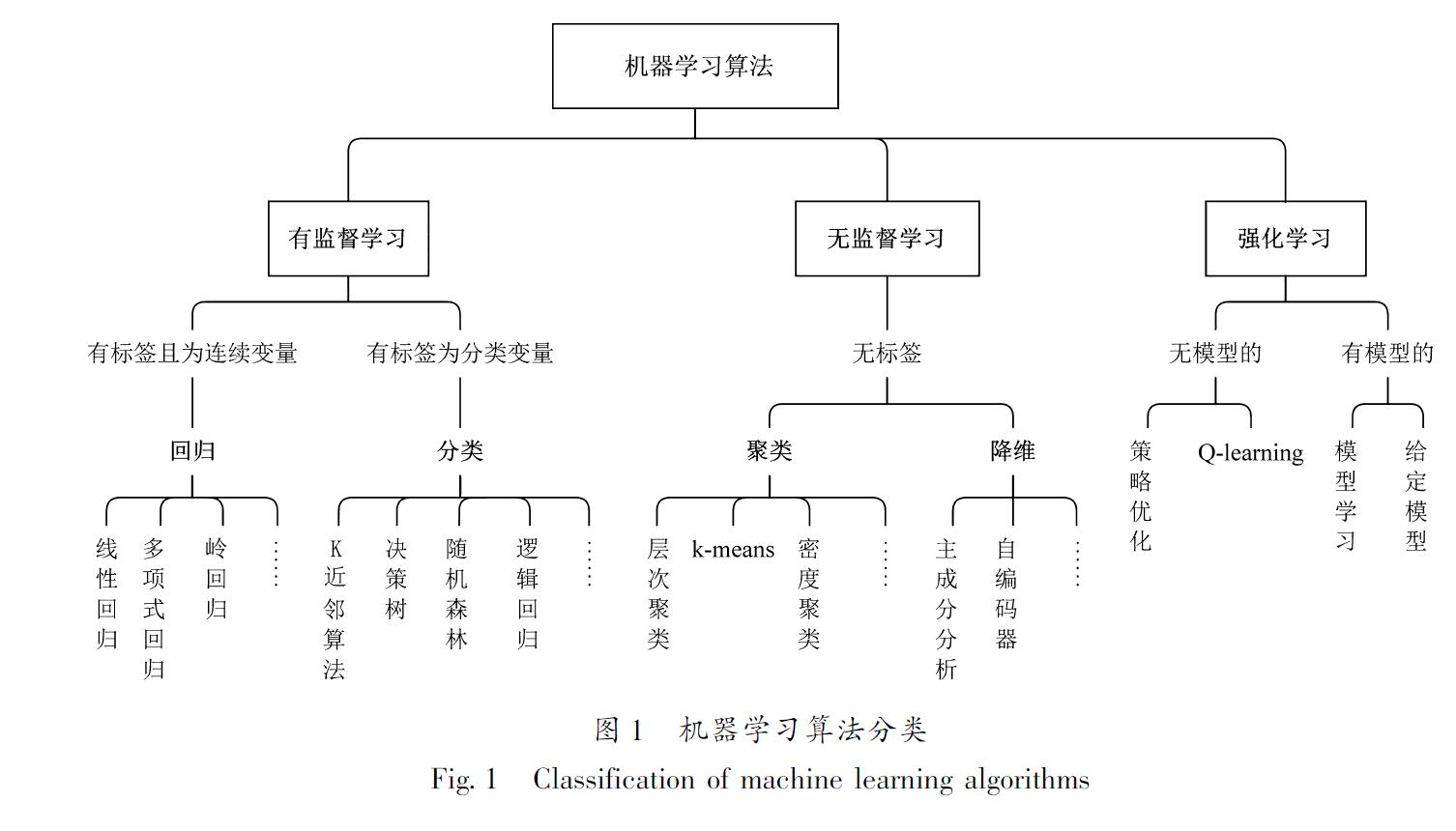
机器学习思想在地震预测中的应用最早起源于我国20世纪80年代,如石绍先和范杨(1990),石绍先和沈斌(1986)研究了多级判别、聚类分析等在地震预测中的应用,后续这种思想延伸到了神经网络中。由于神经网络在处理复杂的非线性问题时具有明显的优点,不需要对象有精确的数学模型,可通过神经网络结构的可变性,逐步适应外部环境的各种因素作用(王炜等,2000a),许多学者将其应用于地震综合预测(蔡煜东等,1993; 李荣峰,2000; 王炜等,2000; 王炜,吴耿峰,2000,2006a,b; 陈一超等,2008; 韩晓飞等,2012)。蔡煜东等(1993)运用神经网络对我国西南地区17个震例进行分析,建立了地震综合预报专家系统,对确定地区、确定时间范围内的地震强度进行预测; 李荣峰(2000)建立人工神经网络模型预测福建及其周边地区的年度最大地震震级,该模型的输入值为4个地震参数(b值、ML≥2.5地震的频次、每年地震释放总能量∑E和空间集中度C值),兼顾地震三要素,预测准确率可达90%; 王炜等(2000b)进一步探索Back Propagation(简称BP)神经网络在地震中期预报中的应用,结果表明中强地震前1~3 a,未来震中周围一般都开始出现明显的异常区,BP神经网络显示出一定的中期预报效果。但由于BP神经网络存在收敛速度慢、易陷入局部最小点等不足,陈一超等(2008)提出利用具有全局搜索能力的遗传算法,建立遗传算法和神经网络相结合的震级预测模型,震级预测误差小于传统BP神经网络; 韩晓飞等(2012)提出基于遗传算法结合广义回归神经网络的地震预测算法,震级预测误差也小于传统的BP神经网络算法。
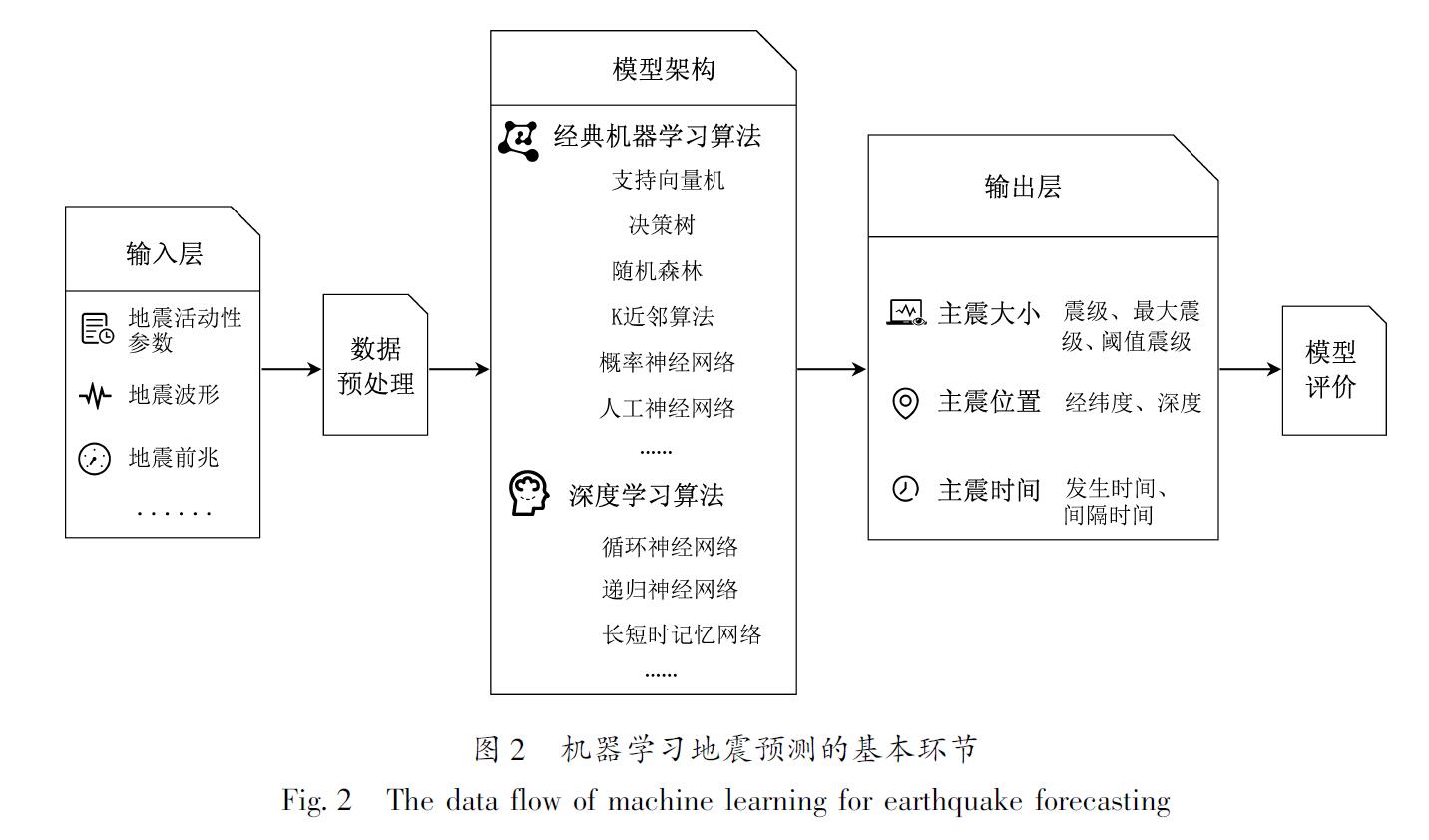
尽管国内开展了许多探索性研究,但总的来看国外在人工智能地震技术研究方面远远走在前列。地震预测的重点是震级、时间、地点三要素,但目前大多数研究主要关注震级预测问题,即在固定区域、固定时间窗前提下,评估某级以上地震的发震可能性,即大多数研究实际上是将地震预测问题进行降维处理,转化为在固定区域、固定时间段内“有”或“无”某级以上地震发生的分类问题。
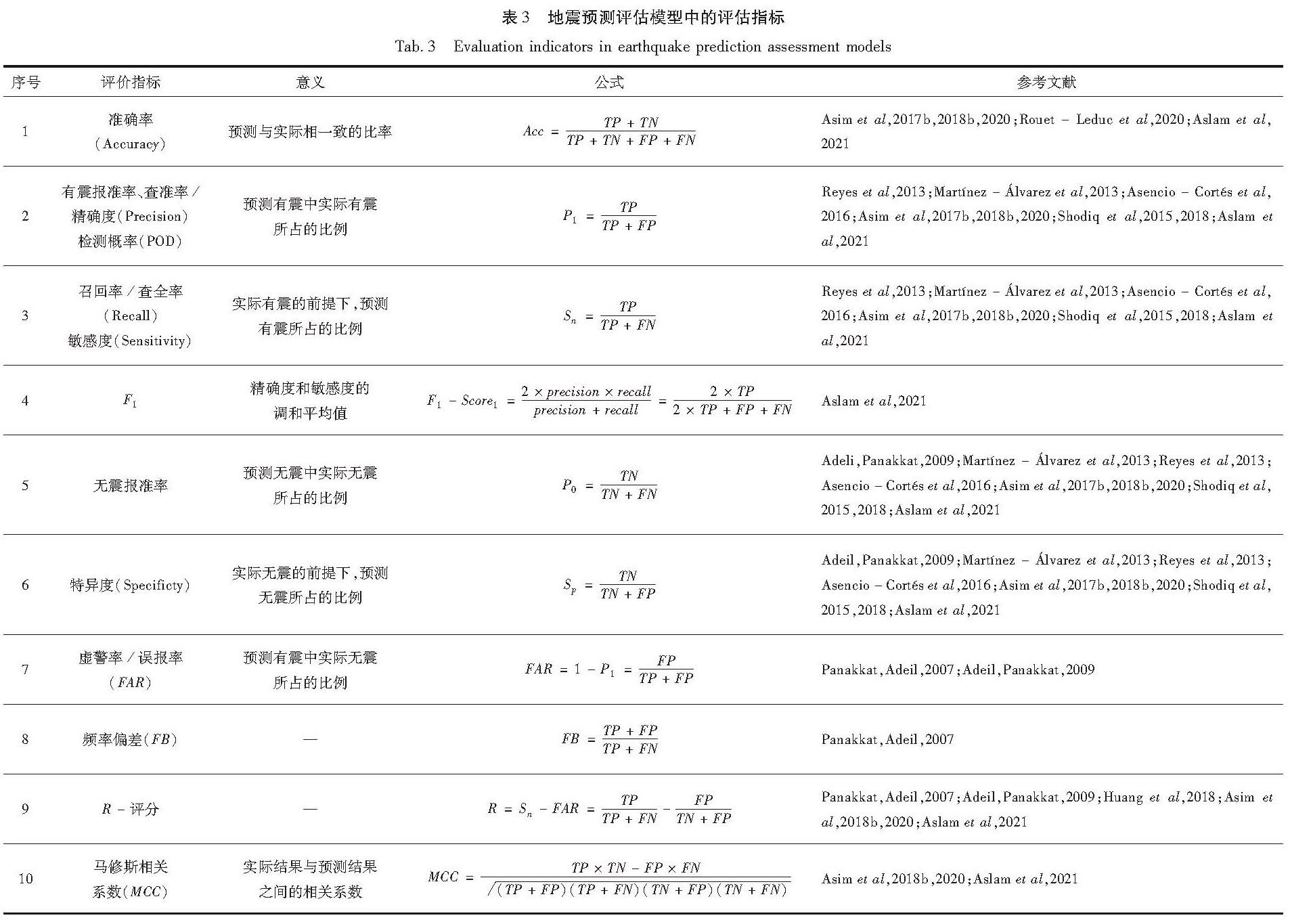
4.1 指定时空窗的地震震级预测
4.1.1 神经网络
人工神经网络(Artificial Neural Network,简称ANN)较早被应用于地震预测研究。Alves(2006)针对地震时间序列的混沌特性,借鉴“金融振荡器(financialoscillators)”工具构建地震相关数据集,利用ANN对1998年7月和2004年1月2次5级以上地震进行预测,虽然预测时空、窗口较大,但也在一定程度上证明了ANN模型的地震预测潜力。为进一步探索ANN的地震预测效能,Reyes等(2013)采用ANN模型对指定区域未来5天内地震趋势进行预测,得到ANN预测效能受区域差异影响较大。而对于相同区域的预测,许多研究显示ANN似乎优于决策树、支持向量机、朴素贝叶斯、K-最近邻、ANFIS等分类器(Reyes et al,2013; Morales-Esteban et al,2013; Pandit,Pandal,2021)。也有研究指出,由于地震目录的结构化和表格化性质及有限的特征数量,比ANN更简单、更透明的机器学习模型似乎更为可取(Mignan,Broccardo,2019)。
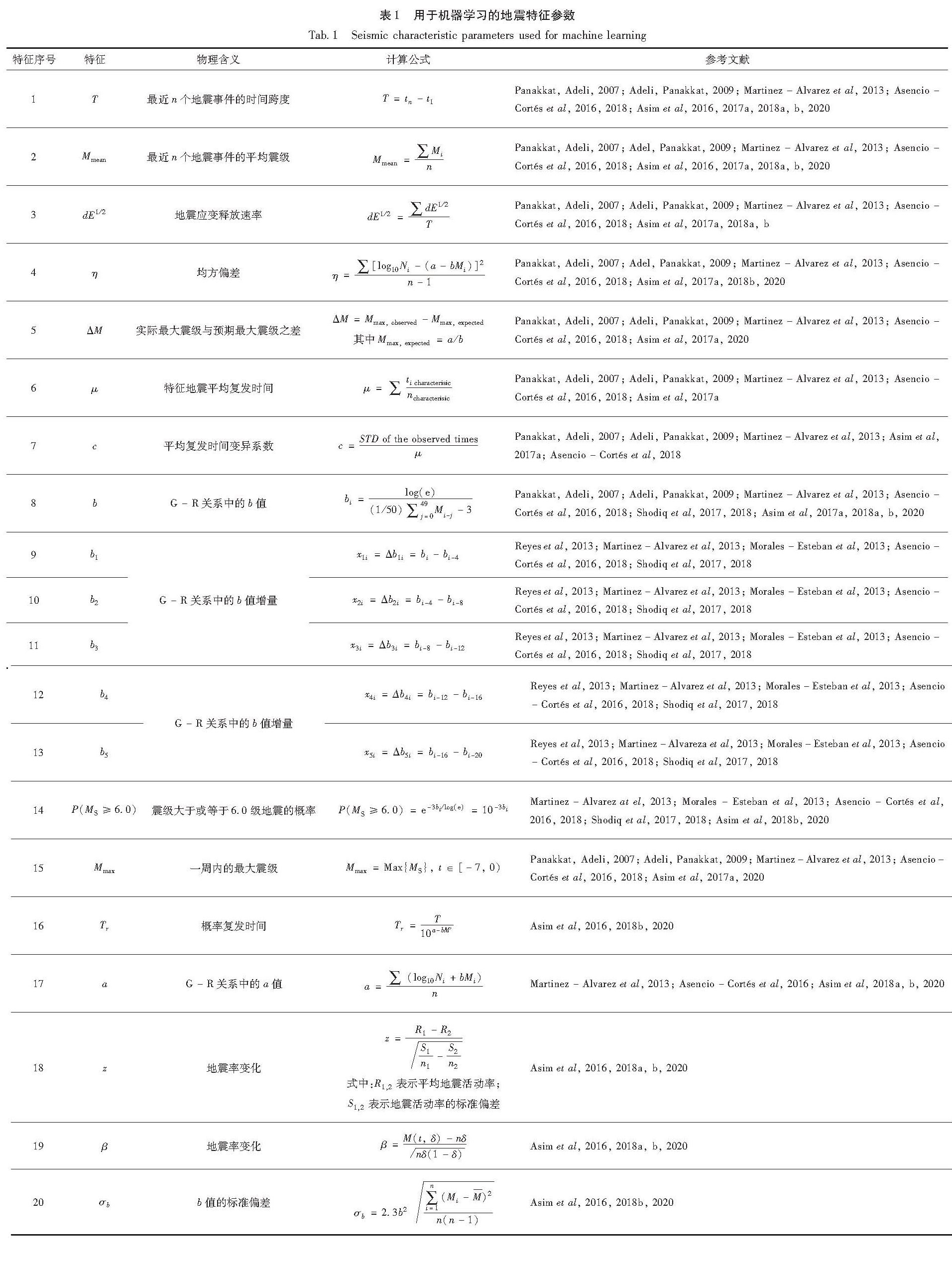
Panakkat和 Adeli(2007)采用前馈反向传播神经网络Levenberg-Marquardt(简称LMBP)、递归神经网络Recurrent Neural Network(简称RNN)和径向基函数神经网络Radial Basis Function(简称RBF)3种模型预测南加州和旧金山地区1991年1月至2005年9月后续单位时间(月)的地震强度,模型输入即表1中8个地震相关特征参数,并使用4种不同的统计指标(检测概率POD、虚警率FAR、频率偏差FB和R分数)评估模型的预测精度,结果表明与LMBP和RBF网络相比,RNN具有更高的预测精度,尤其在中强度地震(5.5≤M<6.5)预测时,不同模型之间的差距最明显; Adeli和Panakkat(2009)使用特征作为概率神经网络(Probabilistic Neural Network,简称PNN)的输入来预测相同地区的地震,结果显示PNN对M≤6.0地震的预测结果比RNN更好。上述8个地震参数还被用于预测兴都库什和巴基斯坦北部的地震,在兴都库什地区,线性规划增强集成分类器(Linear Programming Boosting,简称LPBoost)在预测灵敏度方面有比较好的结果,而神经网络则倾向于产生更低的误报率(Asim et al,2016); 在巴基斯坦北部地区,前馈神经网络则表现更好,其准确率可达75%(Asim et al,2017b)。从上述研究可见,即使用相同的地震活动性特征和相同的机器学习算法,在不同地区也会产生不同的预测效果,可能是由每个区域构造及地震活动特点存在差异所致。尽管机器学习提供了特征或模型选取算法,但主要为针对特定数据的模型与数据之间吻合程度的一系列统计学指标,不同特点的地震活动区域适用哪些特征和算法并没有明确的认识,还是只能使用不停的尝试、检验、调参等方法来进行选择和优化。
随观测数据的急剧增加,ANN模型不断复杂化,深度神经网络Deep Neural Networks(简称DNN)、RNN等学习模型也不断推出。Li等(2020)提出一种可以有效融合显性和隐性特征的深度学习模型A Deep Learning Model for Earthquake Prediction(简称DLEP),在8个具有不同特征的典型地震带上进行测试,认为DLEP在地震震级预测方面具有更好的泛化能力和更高的准确性。RNN的优势在于对序列数据具有记忆,能够更好地反映地震活动的时间依赖特性,因而也被应用于地震预测研究。长短期记忆网络Long Short Term Memory(简称LSTM)作为一种特殊的RNN能够更好地解决长序列训练过程中的梯度消失和梯度爆炸问题,因而被广泛应用,如Wang等(2017)从地震活动空间相关的角度出发,利用LSTM学习不同位置地震之间的时空关系,即使在地震监测能力低的地区,仍然能够使用该方法判断是否有地震发生; Kail等(2021)同样基于LSTM,研究预测震级高于给定阈值的地震是否会从选定时刻开始的10~50天在给定区域发生,并进而解释日本地区历史地震之间的时间依赖特性。由于卷积神经网络(Convolutional Neural Network,简称CNN)和RNN等震相自动识别技术的出现,基于深度学习的地震监测技术快速发展(Perol et al,2018; Mousavi,Beroza,2020),使得地震监测台网可检测出更多的地震事件,其空间分辨率和震级完备性也显著提高,这不但可以改进传统的统计和基于物理的地震预测方法,对基于AI的预测方法、特征构建以及模型训练也大有裨益(Mousavi,Gregory,2022)。
4.1.2 多种机器学习模型集成
同一种数据、多种机器学习模型的联合使用和相互印证可能是当前可以考虑的一种途径,如Asim等(2018b)将地震特征与基于遗传规划Genetic Programming(简称GP)和自适应增强Adaptive Boosting(简称AdaBoost)集成分类方法相结合,定义了一个地震预测系统(Enhanced Particle Swarm Optimization,简称EPSO),用于预测未来15天M≥5.0地震发生的可能性,对兴都库什、智利和南加州地区进行的地震预测,预测精度P1分别为74%、80%和84%,与Asim等(2017b)预测结果相比,提高了约15%; 在巴基斯坦北部也印证了EPSO系统的低误报率(Aslam et al,2021)。Asim等(2018a)利用基于支持向量回归器(Support Vactor Reression,简称SVR)和混合神经网络(Hybrid neural network,简称HNN)的混合系统再次对以上3个地区进行地震预测检验,与灵敏度高达90%但精度P1较小的SVM-HNN预测模型相比较,该分类预测模型灵敏度相对低但精度P1较高,从实际应用的角度更为可取(Asim et al,2018b)。Asencio-Cortés等(2018)利用1970—2017年南加州地区约140万多条地震目录数据,采用16种地震特征参数,探索了4种回归算法(广义线性模型、梯度推进机、深度学习和随机森林)与集成学习相结合用于时间窗为7天的中强地震震级预测尝试,不同算法预测震级与实际震级的对比结果显示非常离散。史翔宇(2021)采用相同的16个地震活动性特征参数,对上述4种模型对预测结果的单独贡献进行分析,发现G-R类特征参数贡献度较大,地震能量类特征参数次之,不同模型和特征参数在不同地震区(带)的地震预测贡献度有较大的差异。
4.1.3 聚类和地震活动图像识别
纯粹的分类/聚类算法也被用于地震预测研究,如Florido等(2015)将原始数据转换成包含地震活动性参数b值的数据集,应用聚类算法对转换后的数据集进行离散化,构建地震活动的参数“序列”,将指定区域M≥4.4地震作为标签,对M≥4.4地震前的所有“序列”进行搜索,找出可能的地震前兆“序列”用于地震预测,在指定的评价语境下,其结果的准确率接近70%,肯定了所提出方法的有效性; Shodiq等(2015)提出一种空间分析和自动聚类技术来判断后续是否有大地震发生,使用山谷追踪技术确定最佳分类数为6类,在质心K均值优于其它K均值的情况下进行分层聚类,其结果显示对印尼地区未来1~6年的地震预测具有较高的准确性; Shodiq等(2017)进一步将自动聚类和人工神经网络相结合,预测印尼地区发生5.1级地震后5天内发生5.5级或6级以上地震的可能性,结果表明该模型能较好地预测6级以上地震,P0、P1、SN、Sp四项指标平均值达到75%,其中P0高达97%; Shodiq等(2018)使用同样的方法对该区域的余震进行预测,发现对M≥6地震的余震具有较好的预测效果,特异度Sp为99.16%。
与计算机视觉类似的地震活动图像识别也被用于地震预测,如Huang等(2018)提出一种基于图深度学习的机器学习地震预测方法,将中国台湾地震活动图转换为图像,共产生65 536个特征(对应256×256像素图像),利用CNN从标有地震信息的地理图像中提取隐含特征,用过去120天的地震事件预测未来30天的地震。如果未来30天的最大地震震级大于等于6级,则将该图像标记为1,否则标记为0。该CNN模型的R值评分约等于0.303,在不需要人工设计特征的情况下,该方法已展现出良好的应用前景。
4.2 发震位置和发震时间预测
目前大多数机器学习地震预测研究均针对指定时空域的未来地震活动水平估计,对地点及时间预测的研究并不多,如Madahizadeh和Allame-
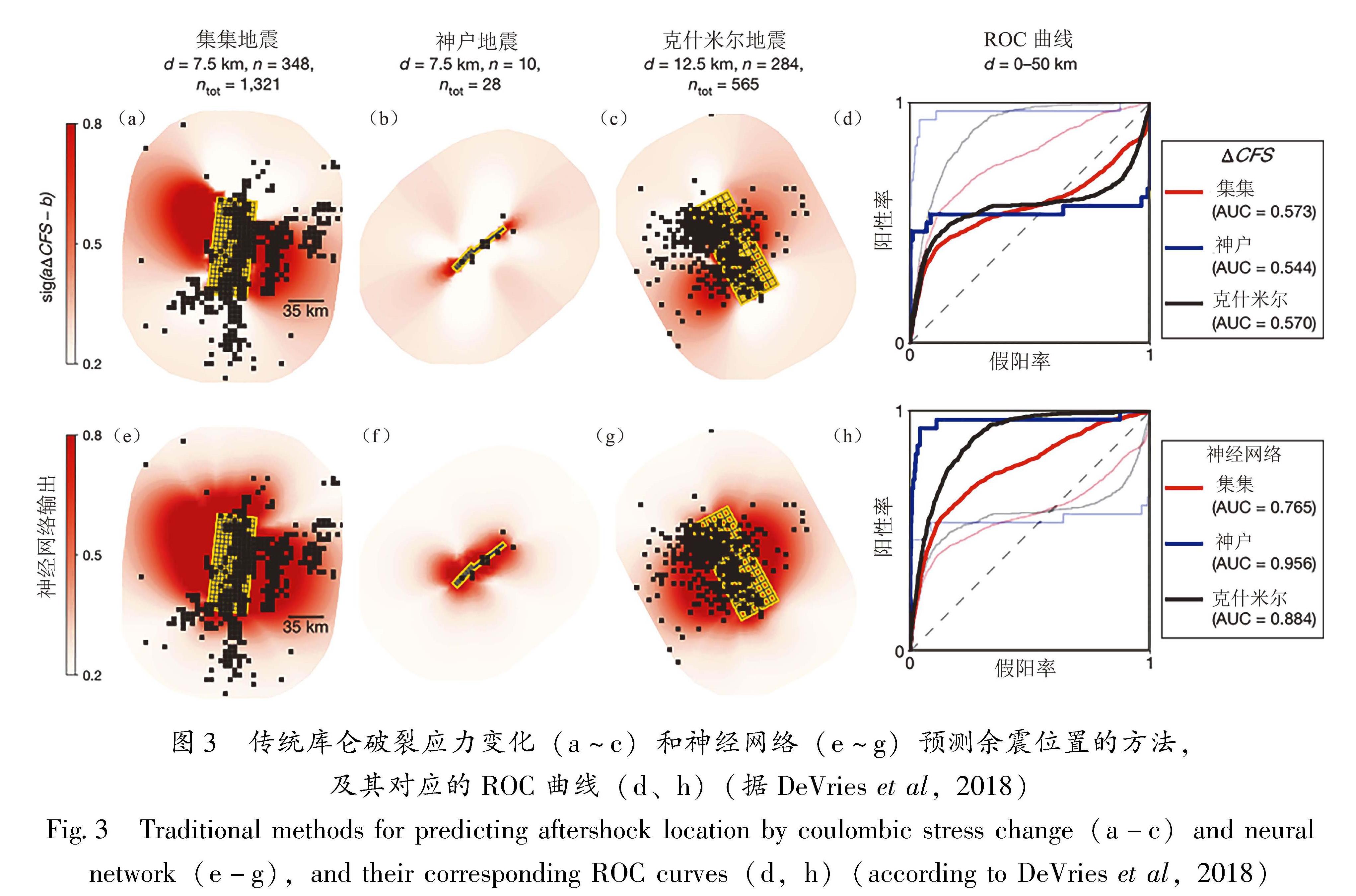
hzadeh(2009)基于人工神经网络对余震空间分布模式进行了研究,但研究对象仅为一个地震序列。DeVries等(2018)基于DNN对余震空间分布区域进行预测研究,共使用了一个包含30 000多个主震-余震对的独立测试数据集对余震进行二元分类(余震存在或不存在),其模型特征主要基于主震破裂模型计算的应力变化张量而设计,并非常用的地震活动性特征; DNN模型包含6个隐藏层,每个隐藏层由50个节点组成,总共产生13 451个自由参数,DNN在测试数据集上遍历所有的破裂滑移分布和网格单元得到的累积AUC值为0.849,大于经典库仑破裂应力准则AUC值(0.583),与ROC评价结果对比来看也是如此(图3)。结果表明DNN在余震地点预测方面比传统库仑破裂应力变化有更好的优势,能够更好地解释余震的空间分布。他们进一步分析认为,对余震地点预测起主要作用的是偏应力张量第二不变量,因而认为DNN给出的预测结果在物理上可解释。该项工作受到广泛关注的同时也引起极大的争议,如Mignan和Broccardo(2019)认为,余震预测属于一种降维预测,本身就应该比主震预测容易,仅用较简单的ANN就完全可以达到很好的效果,且无需应力相关参数的计算,简化了余震预测过程, 限制了模型偏差,深化了对余震机理的认识和对预测模型的改善。
图3 传统库仑破裂应力变化(a~c)和神经网络(e~g)预测余震位置的方法,及其对应的ROC曲线(d、h)(据DeVries et al,2018)
Fig.3 Traditional methods for predicting aftershock location by coulombic stress change(a-c)and neural network(e-g),and their corresponding ROC curves(d,h)(according to DeVries et al,2018)
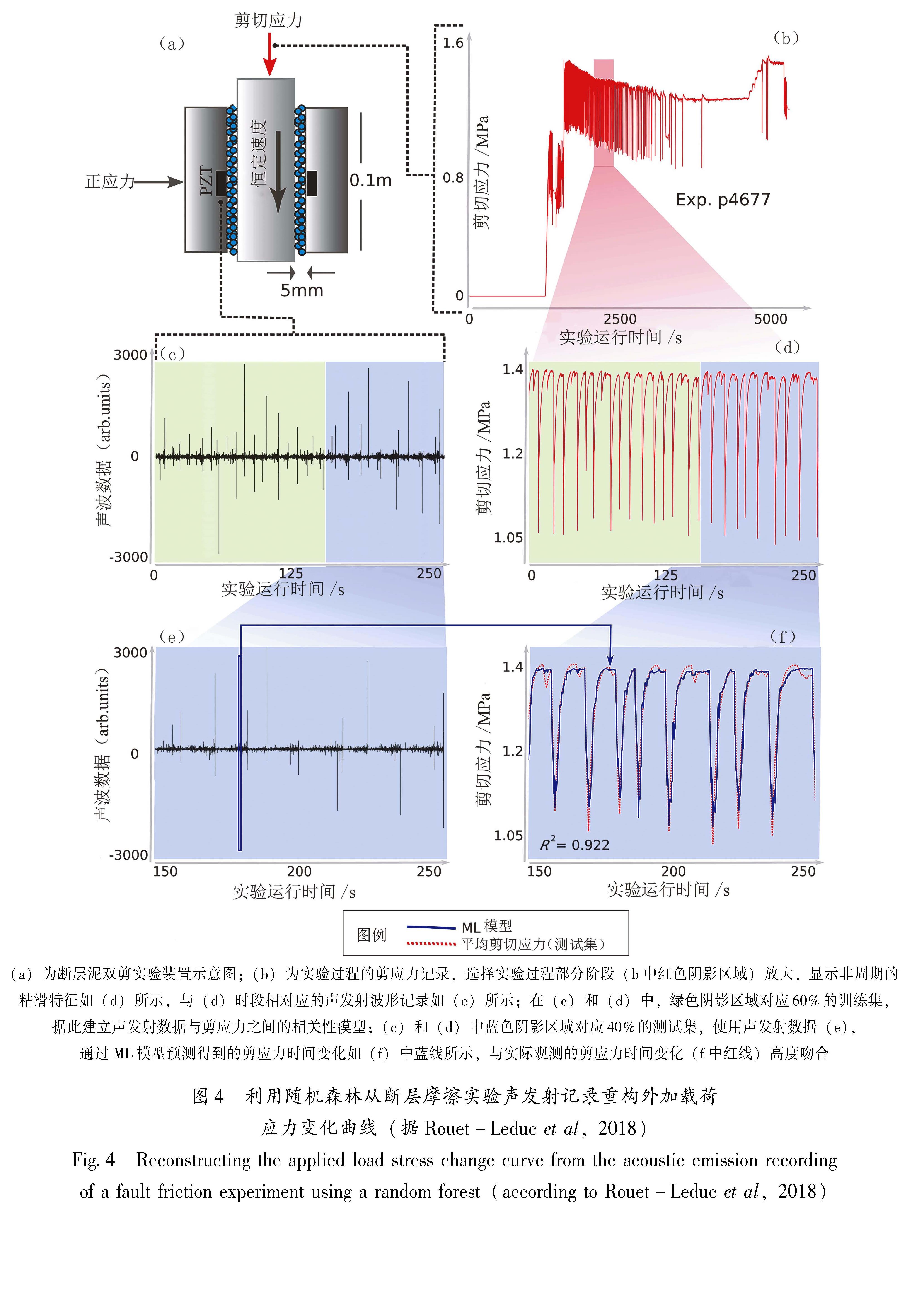
机器学习对地震发生时间的预测,目前仍停留在环境条件单一的实验室观测数据处理,而Rouet-Leduc等(2017,2018)基于剪切摩擦实验AE连续波形记录和同时期的剪应力记录,训练随机森林模型,训练样本约占记录数据的60%,预测并重现了另外约40%时间段的剪应力变化(图4)。这意味着可以通过连续波形记录,预测断层失稳(比拟于大地震)的时间。
图4 利用随机森林从断层摩擦实验声发射记录重构外加载荷应力变化曲线(据Rouet-Leduc et al,2018)
Fig.4 Reconstructing the applied load stress change curve from the acoustic emission recording of a fault friction experiment using a random forest(according to Rouet-Leduc et al,2018)
Hulbert等(2019)基于实验室观测数据开展了类似的重构应力变化过程的研究,并进一步将机器学习用于常规地震与慢地震(包括震颤和瞬时加速和自驱动传播等其他慢滑模式)的识别,其研究肯定了预测各种粘滑和蠕变-滑动失稳模式的可行性,认为灾难性地震失稳前可能会有一组有组织的、潜在的可预测过程。但总的来看,迄今为止尚未见到类似方法在实际地震记录中的应用,其难点可能在于与实验室环境条件相比较,实际环境过于复杂。Wang 等(2021)利用迁移学习算法处理实验室剪切实验数据,实验数据来自一个双轴剪切装置,该装置可记录声发射数据以及计算摩擦系数所需的法向应力和剪切应力。首先通过数值方法模拟实验室观测数值,利用模拟的实验室数据训练机器学习模型,然后将其应用到实验室实际观测数据中预测地震(断层滑移),实现了从数值模拟到实验室剪切实验的迁移学习,同时引入交叉训练的方法来模拟实际地震观测数据不足的情况。结果表明实验中的失稳时间预测要比强度预测更加准确。通过迁移学习,研究人员可以从一个模型推广到另一个模型,从而克服数据的稀疏特性,但其所采用的数据驱动的方法仅对慢滑事件有效,而对于大规模粘滑断层却作用有限。
近期有学者对机器学习在地震预测研究中的概况也进行了总结(Mignan,Broccardo,2020),如Al Banna等(2020)利用“Earthquake”“Prediction”“Neural Network”“Machine Learning”等关键词搜寻了292篇相关论文,经过筛选最终选择84篇进行进一步分析,结果显示利用AI进行地震预测的文章数量近些年呈逐渐上升的趋势且涵盖了几乎所有的AI方法,其中ANN应用最多(约占33%)。按不同作者各自的评价规则及数据,23种AI算法的预测成功率均达到60%,其中神经动态分类-优化模型、反向传播自适应模型和改进的人工蜂群-多层感知系统以及随机森林等的预测准确率相对更高。DNN对复杂问题表现出更优的解决问题能力,在地震预测研究中应用也较为广泛。