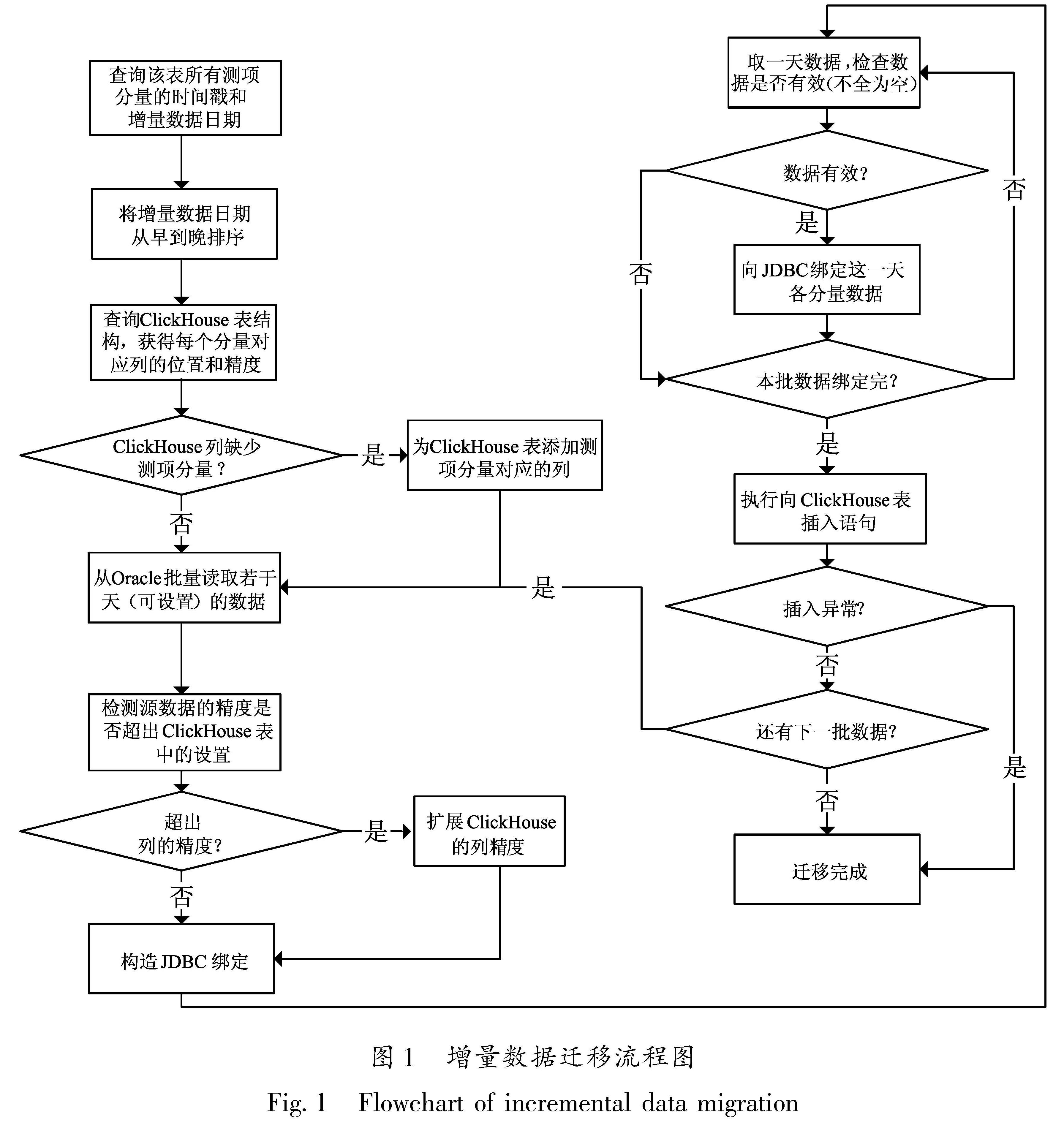
1.1 基础信息
原Oracle数据库中保存着国家地球物理台网的基础信息,比如台站、井泉、洞体、观测室等,这些信息的完整性要求较高,而且含有多达上百兆字节的BLOB(Binary Large Object,二进制大对象)字段,如台站建设报告,仍然需要存储在关系数据库中。考虑到ClickHouse自带访问MySQL数据库的引擎,可以实现ClickHouse和MySQL的表的跨库连接,所以把基础信息迁移到MySQL中,表结构仍然保持不变。
1.2 “十五”观测数据表结构
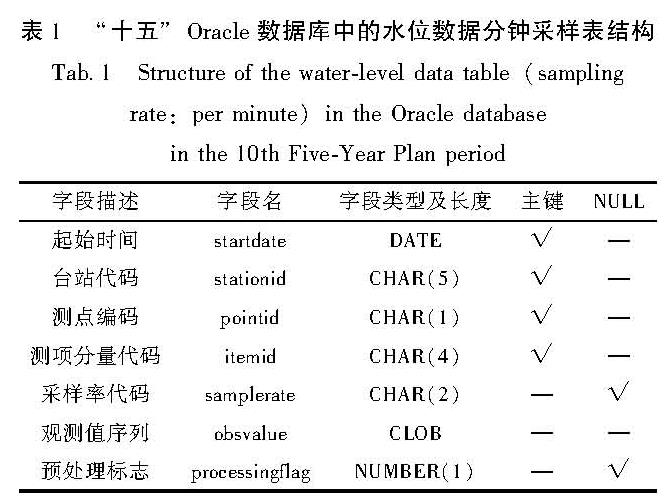
“十五”Oracle数据库中,观测数据按测项、数据类型、采样率进行分表设计存储,表结构类似。以水位数据为例,原始数据分钟采样表名为QZ_411_DYS_01,其中“411”是水位的测项代码,“DYS”为原始数据,“01”为采样率,结构设计见表1。存储时序观测数据的字段是obsvalue,类型是CLOB(Character Large Object,字符大对象),内容是空格分隔的以ASCII码表示的字符串数据。
表1 “十五”Oracle数据库中的水位数据分钟采样表结构
Tab.1 Structure of the water-level data table(sampling rate:per minute)in the Oracle database in the 10th Five-Year Plan period
1.3 ClickHouse的特性与表结构设计
(1)本地表和分布式表
ClickHouse本地表是存储在本地磁盘上的,对它的操作只影响本节点上的数据。分布式表可以理解为集群所有分片上的本地表的合并视图,对分布式表的操作会根据分片规则映射到相应的分片节点上。分片规则必须是以数值类型定义,实际应用中使用数据的年份进行分片,即将相同年的数据放置在同一分片上。
(2)日期类型
ClickHouse的日期字段是DateTime类型,与标准的Unix时间戳一样,不能表示1970年1月1日以前的日期。据了解,Tdengine、IOTDB等数据库也不支持。由于Oracle中有1970年前的数据,所以实际使用64位的整型数来存储时间戳,含义与Unix时间戳一致,代表1970年1月1日0时以来的毫秒数(负数为1970年前),与Java语言中Date类型的getTime方法得到的时间戳相同。
(3)主键
ClickHouse的主键与传统意义上的主键概念不同,它的主键主要用来建立索引查找数据更快,但是不具备唯一性约束,即相同主键的数据可以插入到同张表中。
(4)表引擎
ClickHouse最广泛使用的表引擎是MergeTree家族,它有很多分支。比如ReplicatedMergeTree是指集群中的表,它可以自动在副本之间同步数据。ClickHouse不具备真正的更新和删除功能,它的删除和更新需通过后台的合并来间接实现,合并的时间不可预知。而在实际应用中,原始和预处理数据都有少量的更新需求,使用ReplacingMergeTree引擎引入一个版本列可以保证最终数据表里相同主键的数据只保留1条。考虑到多副本的数据安全性,最终所有的本地表都用ReplicatedReplacingMergeTree表引擎来建立。
为保持与原Oracle数据库设计的兼容,Oracle数据表中所有字段都保留,obsvalue字段则被拆分为时序数据格式单独建表存放。为利用ClickHouse的高速查询优势,将Oracle数据库中所有原始和预处理记录合并到一张表中,但不包含obsvalue字段。ClickHouse数据记录表结构见表2,分布式表与本地表字段相同。
表2 ClickHouse数据记录表结构
Tab.2 Structure of the data-record table in ClickHouse
(5)时序数据表
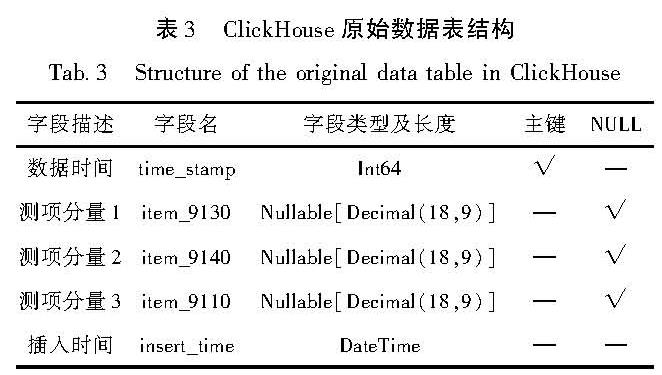
原Oracle中的obsvalue字段存储的是以空格分隔的字符串数据块。在ClickHouse中,该字段需要拆分成单个的数据按对应的时间戳,并以每行一个数据方式存储。为提高存储和查询效率,时序数据按测点、数据类型(原始、预处理或产品)和采样率建表。为了保证数据迁移后的精度,时序数据用Decimal类型保存。以中国地震局地质研究所白浮台(代码03002)测点3气象三要素观测仪原始分钟采样数据为例,本地表名为DYS_01_03002_3,分布式表名为DYS_01_03002_3_ALL。本地表结构见表3,分布式表字段与本地表相同。
表3 ClickHouse原始数据表结构
Tab.3 Structure of the original data table in ClickHouse
(6)产品数据表
产品数据表包括均值类产品数据和学科专业产品数据。均值类产品数据主要由预处理软件产生,在Oracle中的表结构比原始和预处理表仅缺少processingflag字段,所以均值产品数据在ClickHouse中可与原始和预处理数据一样,将均值产品的观测数据序列拆分到时序表(表3),将记录中其它信息存放在数据记录表(表2)中,用数据类型字段对均值产品类型进行区分。学科专业产品数据在Oralce中的表结构与原始或预处理数据差异很大,需要根据各自特点分别设计,此处不再赘述。
(7)日志表
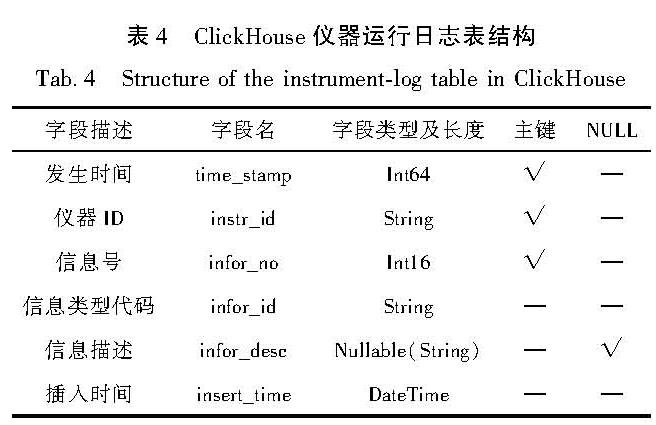
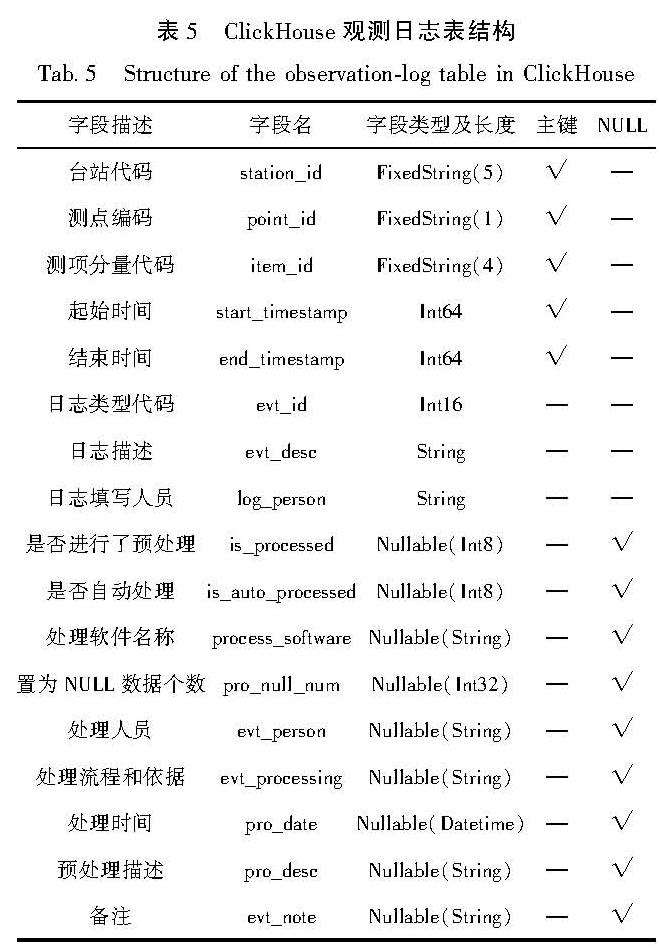
日志表包括仪器运行日志表和观测日志表,这两类表在Oracle中的表结构按测项进行分表。因为日志表每行数据量较小,而且不含有LOB字段,所以在ClickHouse中可以将各测项合并到1张表。仪器运行日志表结构见表4,观测日志表结构见表5。
表4 ClickHouse仪器运行日志表结构
Tab.4 Structure of the instrument-log table in ClickHouse
表5 ClickHouse观测日志表结构
Tab.5 Structure of the observation-log table in ClickHouse