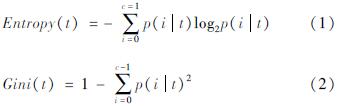1.1 资料收集和样本标签
本文收集整理了1966—2021年川滇及其附近区域(21°~35°N,97.5~106°E)范围内5级以上地震序列,去除余震序列中5级以上余震,并将多震型地震算为1次事件,共得到5级以上地震序列225组,其中5.0~5.9级地震序列180组,6.0~6.9级地震序列33组,7.0~7.9级地震序列11组,8.0级以上地震序列1组,最大为2008年5月12日四川汶川8.0级地震序列。为保证结果统一,对于采用ML震级标度的地震序列,根据公式MS=1.13ML-1.08换算为MS震级(刘瑞丰等,2015)。
根据地震序列类型震级差分类定义(蒋海昆等,2006a),采用序列主震与后续最大地震震级差ΔM=M0-M1,将序列类型划分为多震型、主余型和孤立型,并以此作为机器学习序列类型判定的样本标签:ΔM<0.6为多震型序列,包括震群型和双震型序列; 0.6≤ΔM<2.5为主余型序列,包括主余型和前震-主震-余震型序列; ΔM≥2.5为孤立型序列。
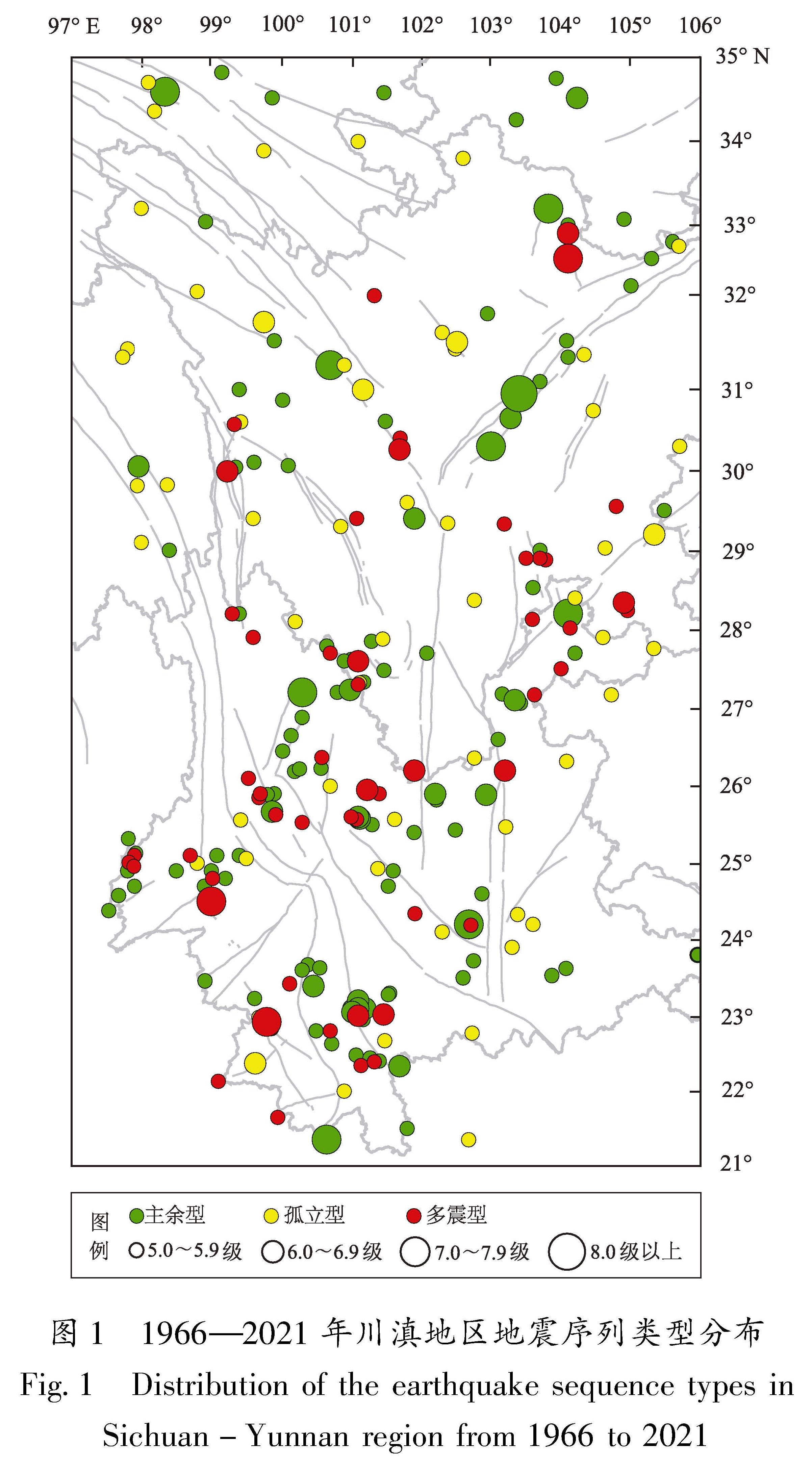
1966—2021年川滇地区地震序列空间分布如图1所示。由图1可见,地震序列类型空间分布具有一定的区域特征:多震型相对集中在滇西的下关和姚安、腾冲—保山块体的龙陵、澜沧等地,滇东的鲁甸、川滇交界的盐源、川西巴塘、川东马边、川东北松潘—龙门山断裂带的松潘等地也有多震型地震发生; 鲜水河—安宁河—小江地震带及金沙江—红河地震带以主余型地震序列活动为主。
图1 1966—2021年川滇地区地震序列类型分布
Fig.1 Distribution of the earthquake sequence types in Sichuan-Yunnan region from 1966 to 2021
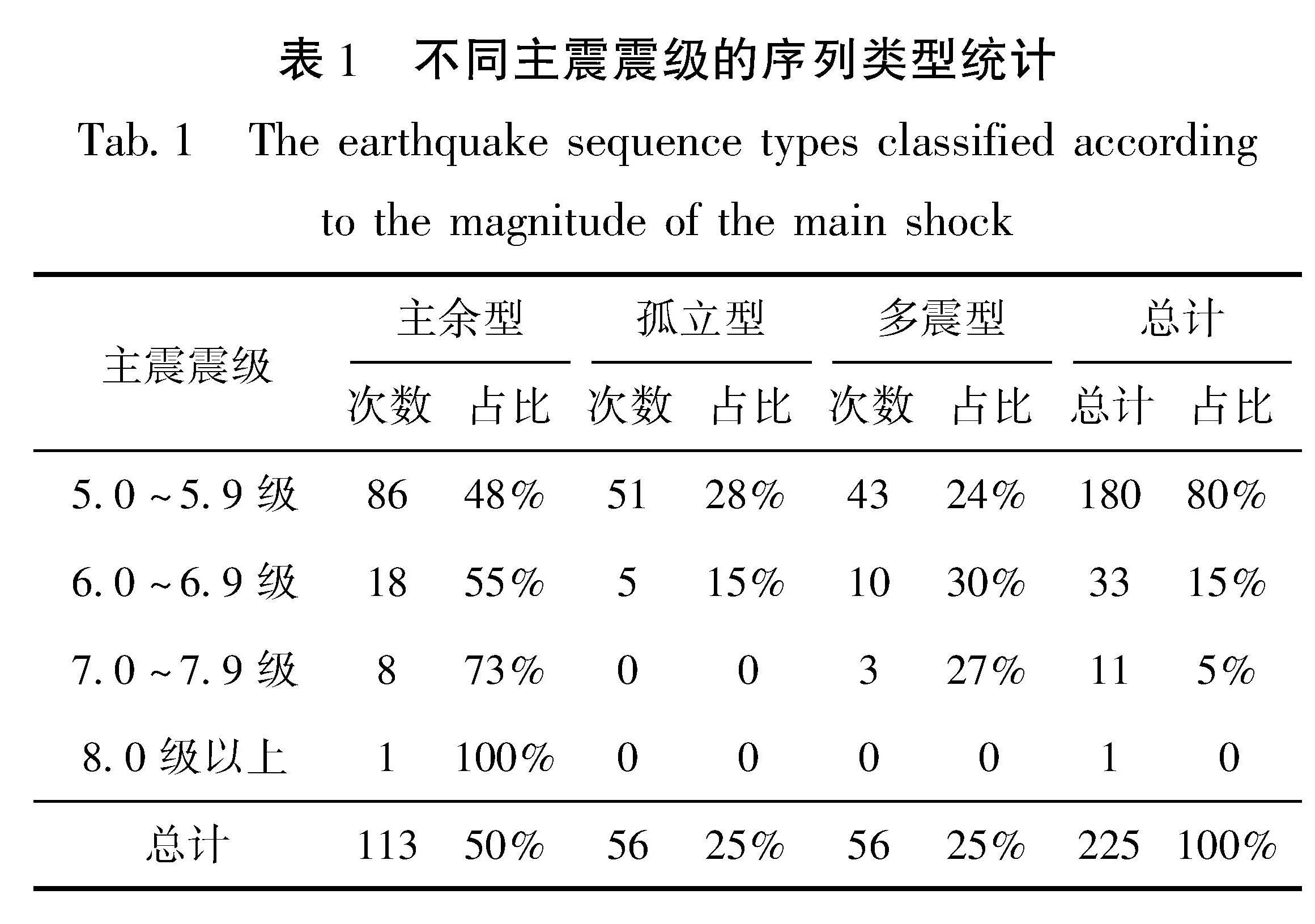
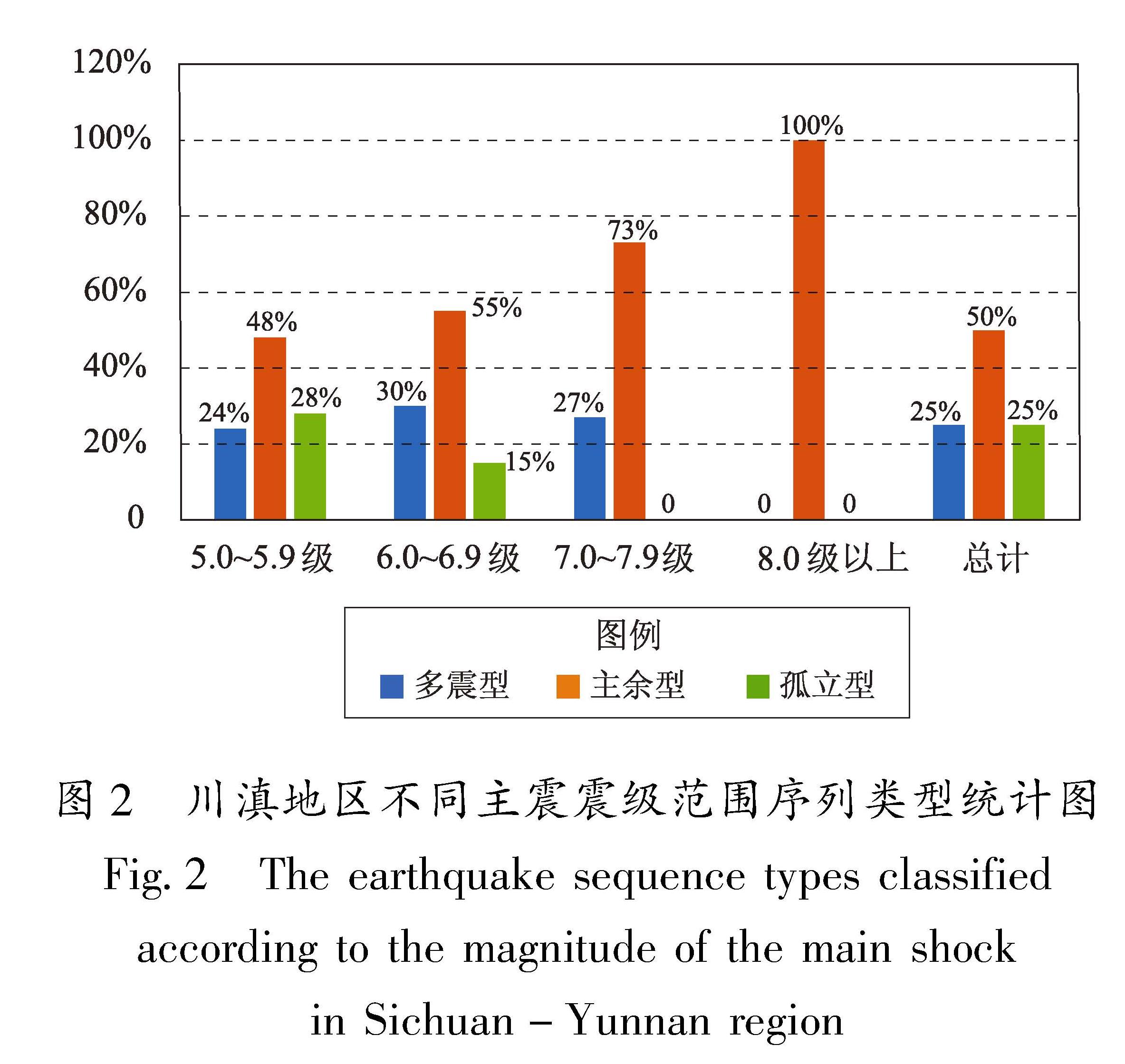
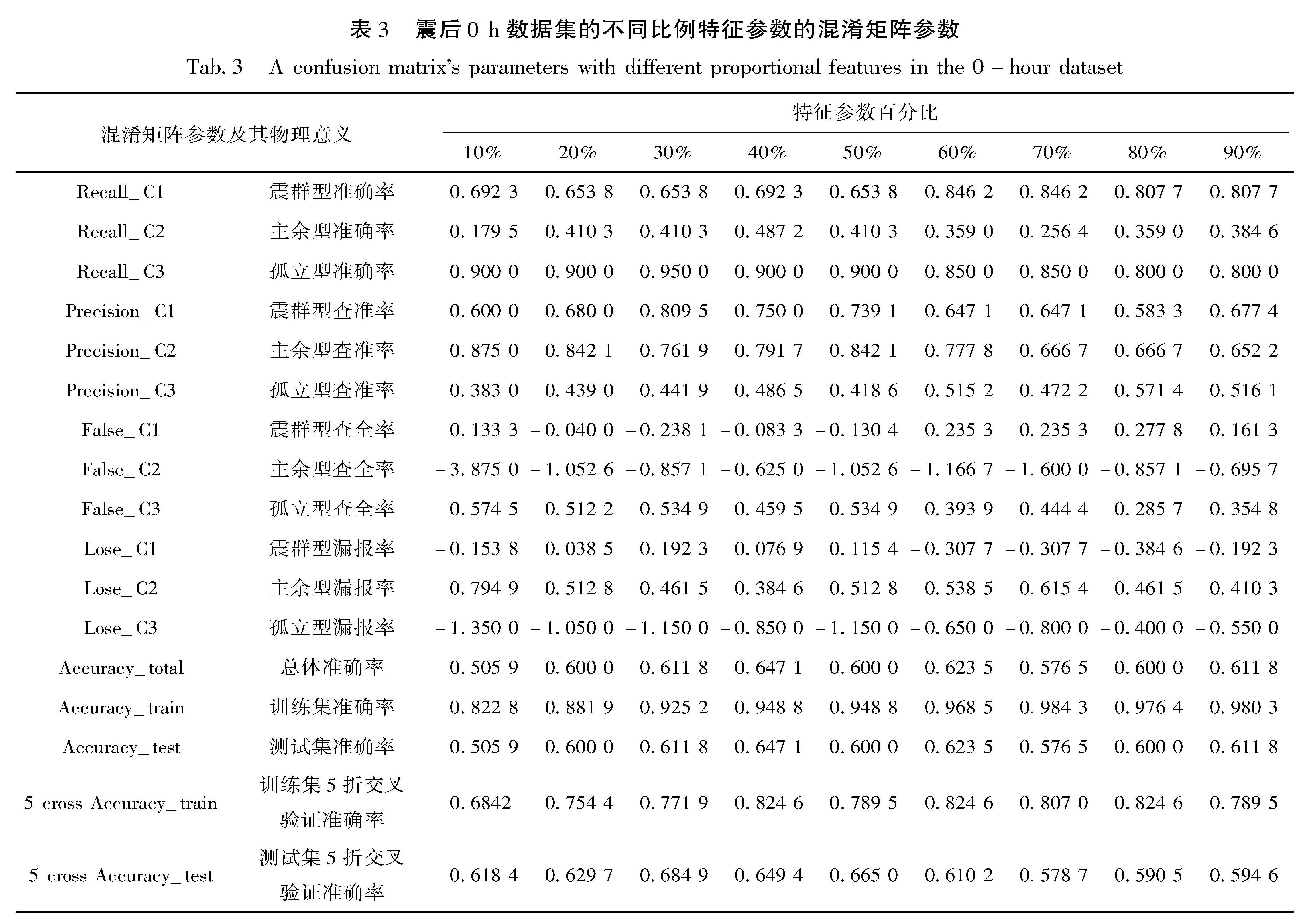
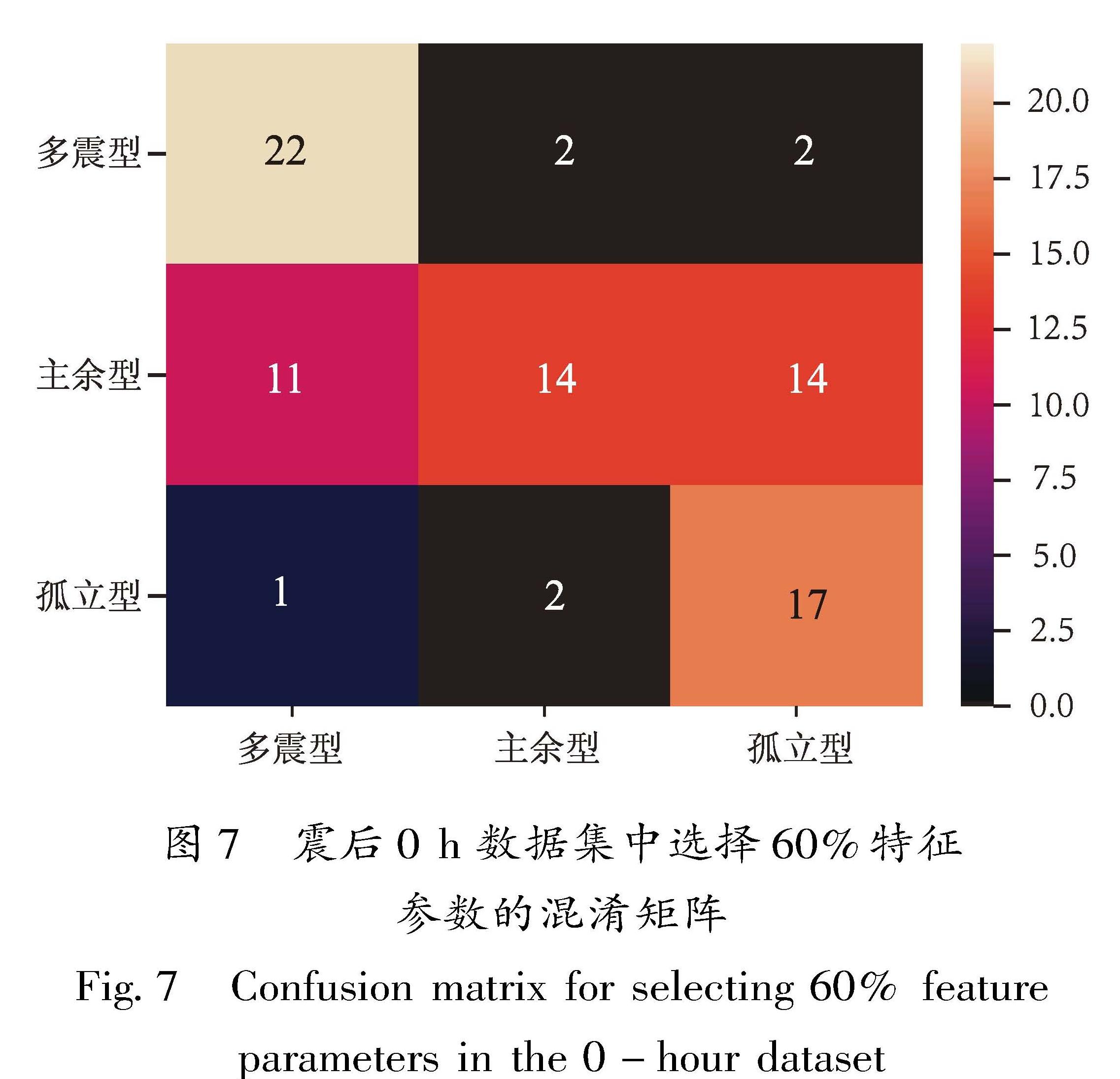
表1给出了不同范围内的主震震级的序列类型统计结果,由表1可见,主余型序列所占比例最大,约占全部序列的50%,多震型和孤立型序列各占25%; 主余型和孤立型序列合计约占75%,略低于前人78%~87%的统计结果(吴开统等,1990; 蒋海昆等,2006a; 苏有锦等,2014),表明川滇地区多震型地震的比例相对较高,具有独特的区域特征; 孤立型序列所占比例则随着主震震级升高而降低,无 7 级以上的孤立型序列,主震震级最大的孤立型序列为1981年四川道孚6.9级地震序列; 6级以上地震多震型序列比例相对较高,这与全国(蒋海昆等,2007a)及南北带中段(祁玉萍等,2021)的统计结果有一定差异,这可能是由于云南多震型序列的6、7级地震序列相对较多。
表1 不同主震震级的序列类型统计
Tab.1 The earthquake sequence types classified according to the magnitude of the main shock
图2 川滇地区不同主震震级范围序列类型统计图
Fig.2 The earthquake sequence types classified according to the magnitude of the main shock in Sichuan-Yunnan region
1.2 特征构建
监督学习的输入是学习样本的特征集合和样本标签。特征工程是机器学习地震预测的最关键环节。对地震预测这类机理不明、单项特征与标签之间关系不唯一的分类任务,如何确定训练样本数据集的输入特征,是机器学习数据准备的最重要工作(蒋海昆,王锦红,2023)。
在地震序列特征研究方面,有3个重要的统计定律:①地震序列的频度-震级关系遵从G-R关系; ②地震序列的频度随时间的衰减遵从修正的大森公式; ③地震序列的主震与最大余震的震级差D遵从巴特定律。
国内外学者以这3个定律为基础,对地震序列的时、空、强分布特征开展了大量的研究(Ben-Zion,Rice,1993; Ben-Zion,Lyakhovsky,2006; 蒋海昆等,2006c,2007b; 崔子健等,2012; 黄浩,付虹,2014)。其中,对地震序列的判定多是从序列本身及其频次和能量的演化特征着手,进行定性(变化趋势)或半定量(参数统计指标)的判定(蒋海昆等,2007c),但在震后早期阶段,由于序列数据少,大多只能通过对比该地区长期地震活动的特点来判断序列类型,并在此基础上建立基于震例类比的震后趋势早期判定技术系统(刘珠妹等,2019)。震后随着时间的推移,地震目录和地震波形数据积累会越来越多,可用于序列类型判定资料和方法也越来越多。
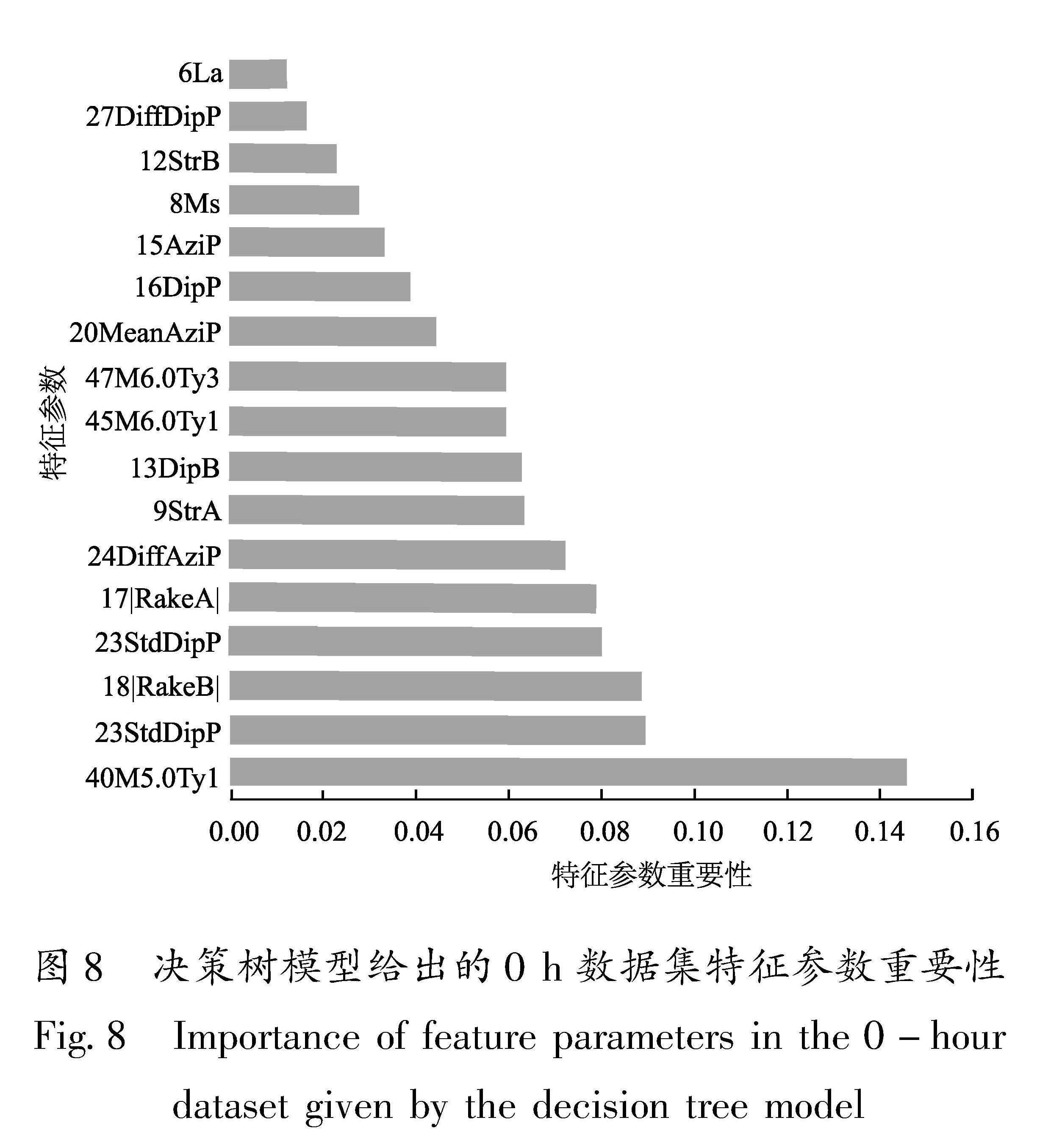
本文参考现有地震序列类型判定参数和方法,其中一些特征和方法选择机器学习地震序列类型判定的备选特征,主要包括主震、主震震源机制、主震附近区域历史地震序列类型占比、指定时段序列衰减、指定时段G-R关系、指定时段归一化能量熵、指定时段最大余震震级、指定时段小震频次及震级共8类相关参数(蒋海昆,王锦红,2023)。此外,刘正荣和孔绍麟(1986)通过对多次地震序列的h值进行震后分时计算,成功地判定出这些地震序列的类型,并预报了序列中的最大余震震级,因此本文采用了h值这一特征参数,根据其定义,将其归类为指定时段序列衰减相关参数。
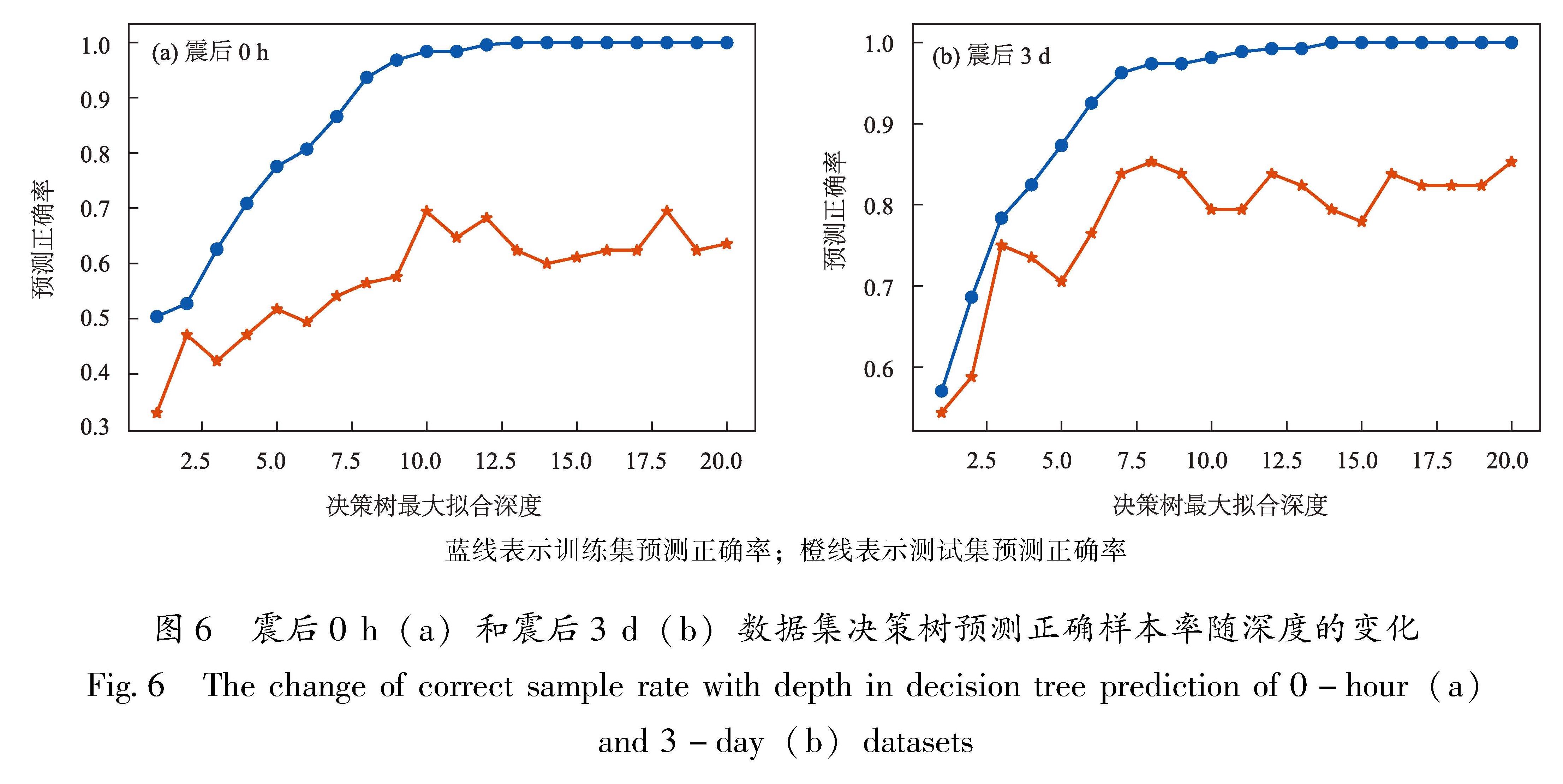
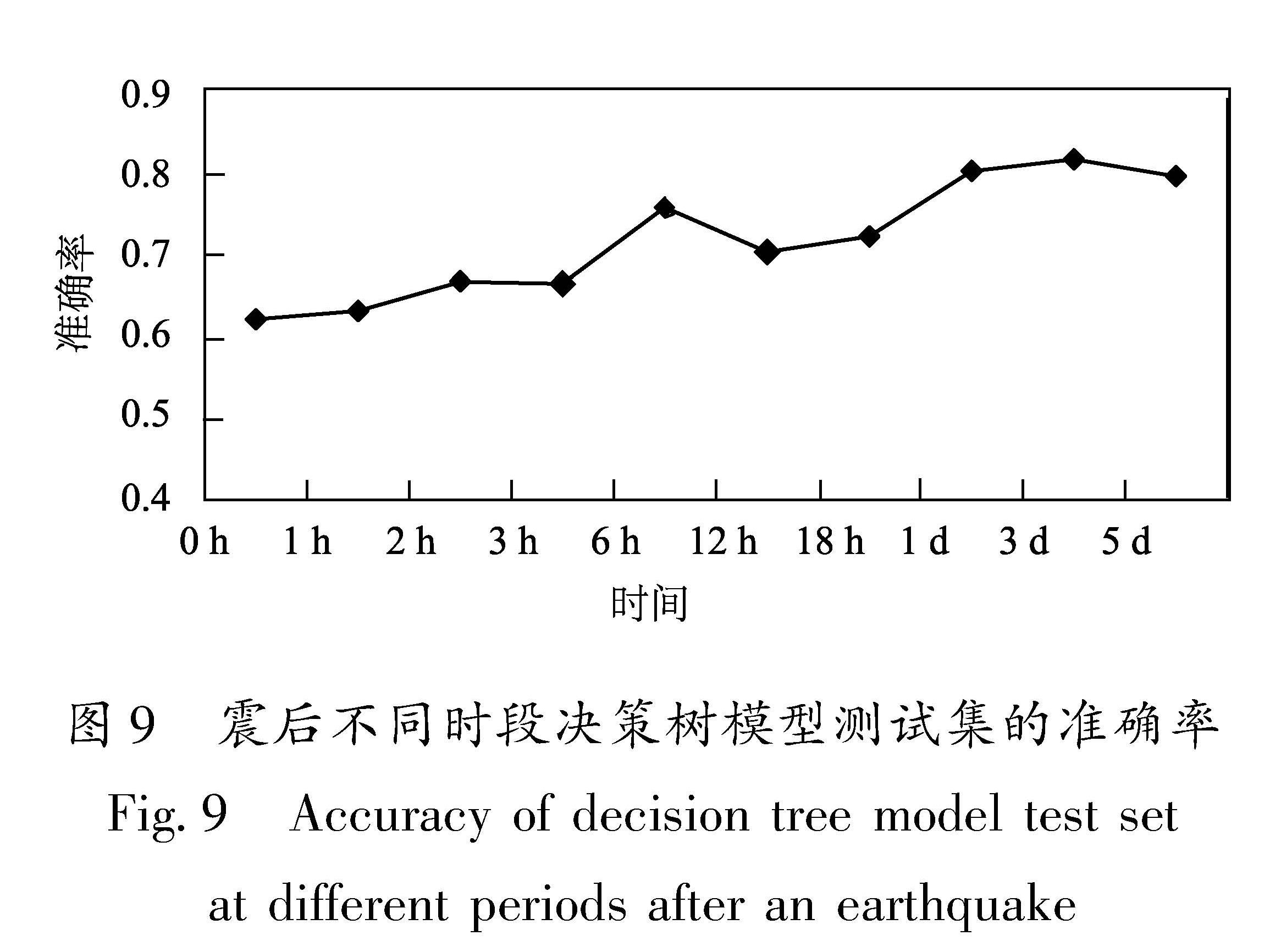
震后不同时间段数据集的构建及其划分,主要是依据震后趋势判定相关业务规定和实际工作需求来进行,如在显著地震发生后30 min内,产出震后快速研判意见,震后2 h内,产出震后首次会商意见。此外,根据《地震现场工作管理规定》 中国地震局.2013.地震现场工作管理规定(中震救函〔2013〕42号).等文件中给出的相关时间节点及震后趋势判定经验,和震后首次、震后1~3 d、4~7 d等多个会商时段工作需求,最终构建了震后0 h、1 h、2 h、3 h、6 h、12 h、18 h、1 d、3 d、5 d共10个时间尺度的特征参数数据集。
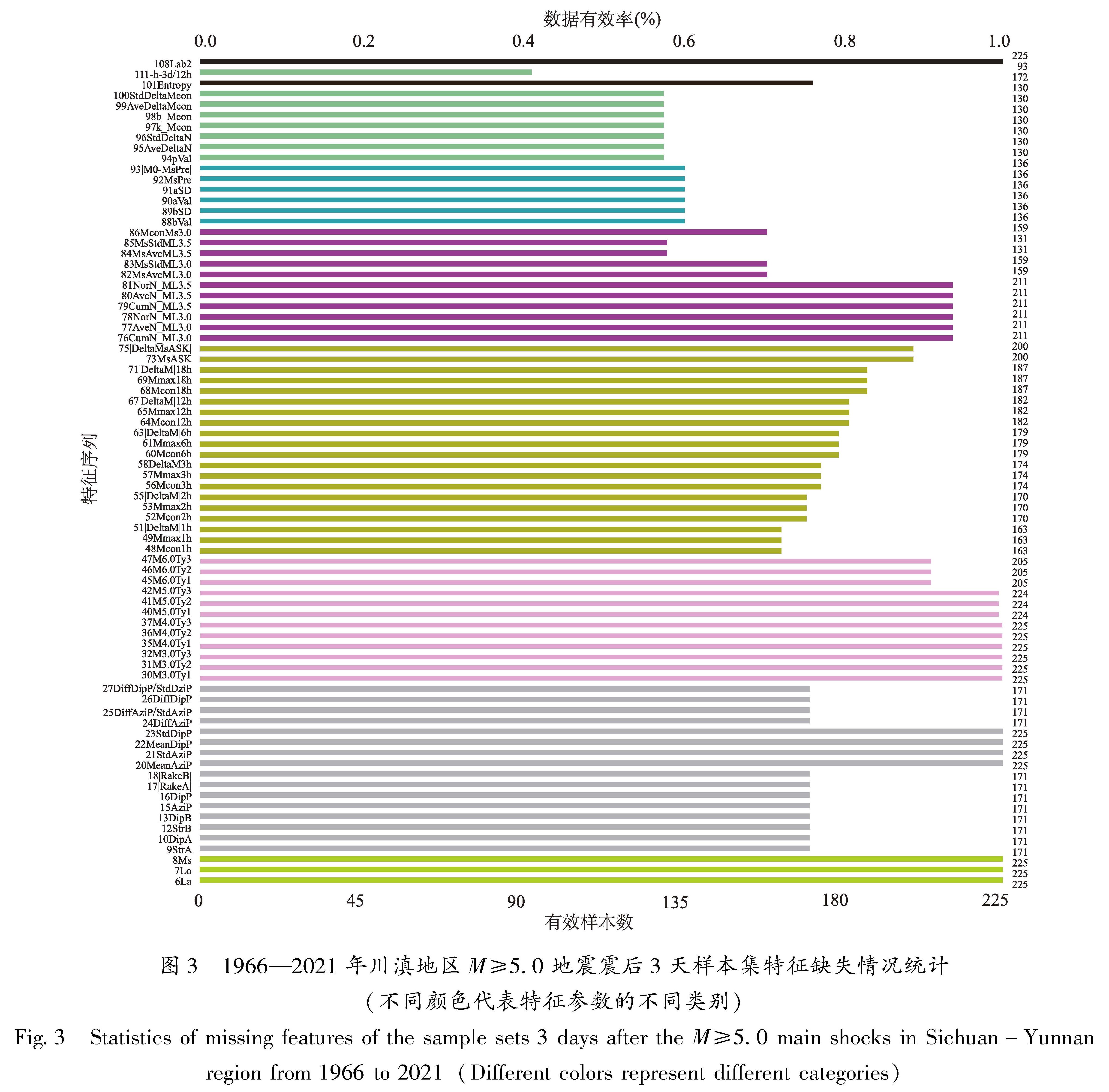
川滇地区225个地震序列样本备选特征参数缺失情况如图3所示。图中主震(浅绿色)及主震附近区域历史地震序列类型(粉红色)参数完备性相对较高,达100%。少部分地区由于历史上并没有6级地震发生,因此45M6.0Ty1、46M6.0Ty2、47M6.0Ty3这3个特征参数完备性略低,为91%; 主震震源机制相关参数(浅灰色)的特征完备性为76%。
震后,随着时间的延长,地震序列的数据逐渐增多,基于地震目录的序列参数计算结果被用于序列类型判定,因此震后1 h至5 d的数据集特征参数不断增加,其中1~18 h增加了不同时间段的折合震级、最大余震震级、震级差。1~5 d数据集还增加了满足计算样本条件的大森公式p值、h值,G-R关系b值、归一化能量熵等。随着时间的推移,指定时段最大余震震级相关参数(土黄色)的完备性略有增加,约为80%左右; 指定时段序列衰减(绿色)、G-R关系(蓝色)、归一化能量熵(棕色)等参数由于对计算样本量和监测能力有一定要求,完备性较低,约为60%(图3)。图3中108Lab2(黑色)为序列标签。
1.3 样本不均衡处理
所谓的不均衡数据集,是指数据集中各类别的样本量极不均衡。通常多数类与少数类样本比例明显大于1:1时,可认为属于不均衡样本。基于不均衡样本训练的模型,会倾向于受到多数样本类别的控制。为尽可能避免此类影响,一般要从数据或算法的角度,对不均衡数据进行处理。在不同类别样本占比不是特别悬殊的情况下,可以考虑随机采样方法。本文构建的225个地震序列的特征参数中,主余型序列样本数量最多,为113个,占50%,孤立型和震群型所占比例相当,均为25%,可见虽然样本数据不均衡,但比列并不特别悬殊,可以用随机采样中的过采样,从少数类样本中对特征进行随机采样,以组合构建新的样本,从而使样本数据均衡 柚子皮.2020.不平衡数据的机器学习.https://blog.csdn.net/pipisorry/article/details/78091626.。
此外,应使用交叉验证来开展模型评价。交叉验证中,通过多次划分,大大降低了由某一次随机划分带来的偶然性,通过多次划分、多次训练,模型也能遇到各种各样的数据,从而提高其泛化能力,以确保不会出现过拟合现象 Kamekin.2018.不平衡数据集的处理.https://www.cnblogs.com/kamekin/p/9824294.html.。
图3 1966—2021年川滇地区M≥5.0地震震后3天样本集特征缺失情况统计(不同颜色代表特征参数的不同类别)
Fig.3 Statistics of missing features of the sample sets 3 days after the M≥5.0 main shocks in Sichuan-Yunnan region from 1966 to 2021(Different colors represent different categories)
1.4 特征数据缺失处理
一般来说,未经处理的原始数据中通常会存在缺失值、离群值等,因此在建模训练之前需要对缺失值进行处理。如图3所示,川滇地区仅225个小数据样本,数据缺失会进一步加剧样本不足的问题。缺失值处理有删除、统计值填充、统一值填充、前后值均值填充、插值法填充、建模预测填充等多种方法 Phoenix Studio.2020.特征工程之缺失值处理.https://blog.csdn.net/weixin_41503009/article/details/105550244.。在统计值填充方法中,“统计值”可选择平均值、中位数、众数、最大值、最小值等,具体使用哪一种统计值要具体问题具体分析。根据本文特征参数数据样本特点,笔者采用同类样本中位值对缺失特征进行补齐。
具体做法是:对每一个特征参数,分别计算多震型、主余型、孤立型特征中位值,之后对该类样本中缺失该特征的样本,以该中位值进行补齐。例如对主余型样本的归一化能量熵(101Entropy), 基于172个无Entropy值缺失的样本,计算其中位值,进而对有Entropy值缺失的主余型样本,用该中位值进行补齐。对多震型、孤立型样本也做类似计算处理。对所有缺失特征进行中位值补齐之后,所有样本都可参与模型训练。结果显示,缺失特征补齐的数据预处理方式,不但可显著增加可用样本量,更可以明显提升特征与序列分类之间的关联性(蒋海昆,王锦红,2023)。
1.5 数据拆分
在机器学习中,人们通常将原始数据按照比例分割为训练集和测试集。训练集用于训练模型,如通过利用训练集中数据,训练拟合一些参数来建立分类模型; 测试集用来评价模型好坏,测试集不参与模型训练,主要用于测试已训练好的模型的准确能力等,但不能作为与调参、选择特征等算法相关选择的依据。
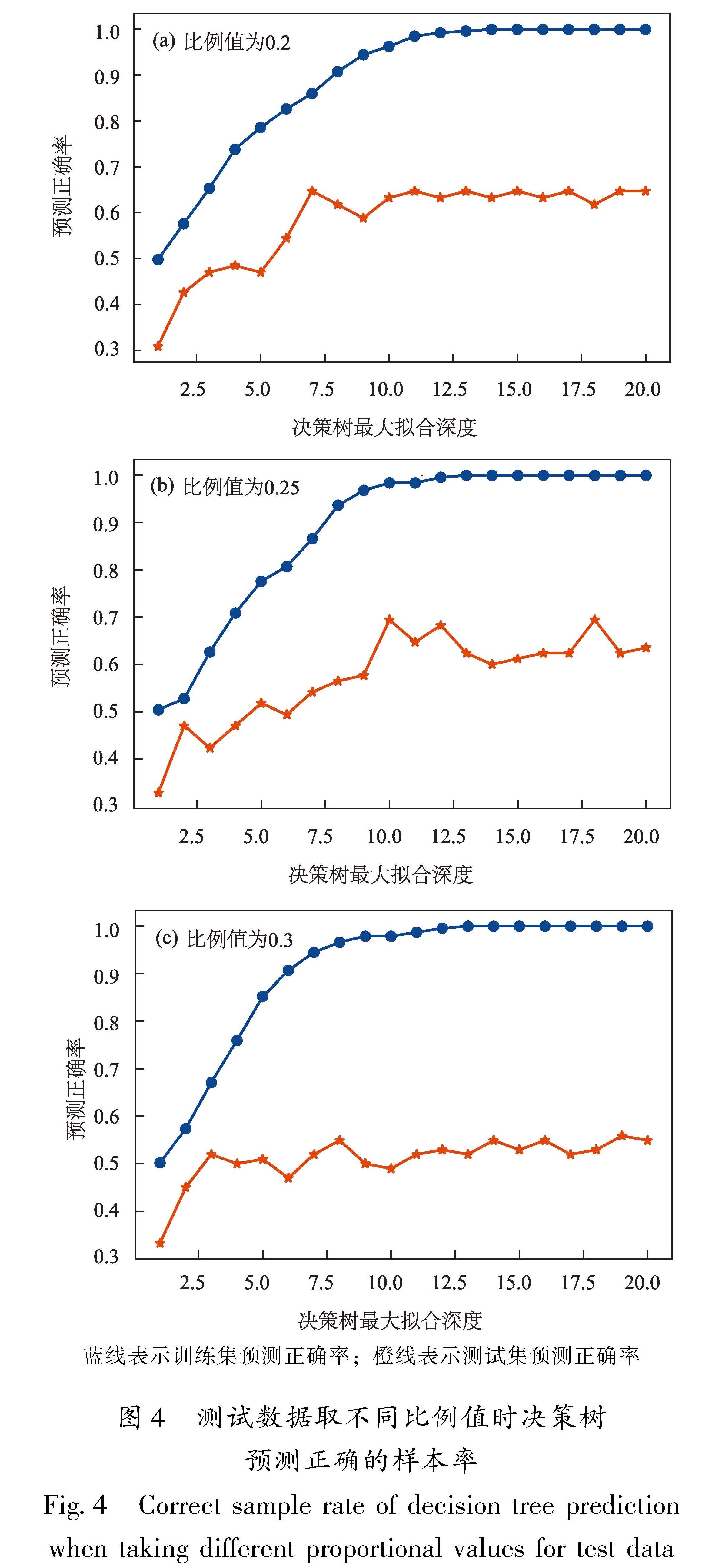
本文采用train_test_split函数将数据矩阵随机划分为训练子集和测试子集。采用震后0 h数据集,计算了训练集、测试集取不同比例值时决策树预测正确的样本率。图4给出了比例值为0.2、0.25和0.3时,决策树模型给出的训练集和测试集预测正确的样本率随决策树最大拟合深度的变化图。
结果显示,决策树最大拟合深度为1~10时,训练集预测正确率随决策树最大拟合深度逐渐增大,在最大拟合深度达到10以后,正确率相对稳定,且取不同比例值对训练集预测正确率影响较小,但对测试集影响较大,最大拟合深度取0.25比例值,测试集的预测正确率相对较高。这表明,在本文构建的225个样本中,当测试集占整个数据集的25%时,模型预测正确的样本率最高。
1.6 特征选择
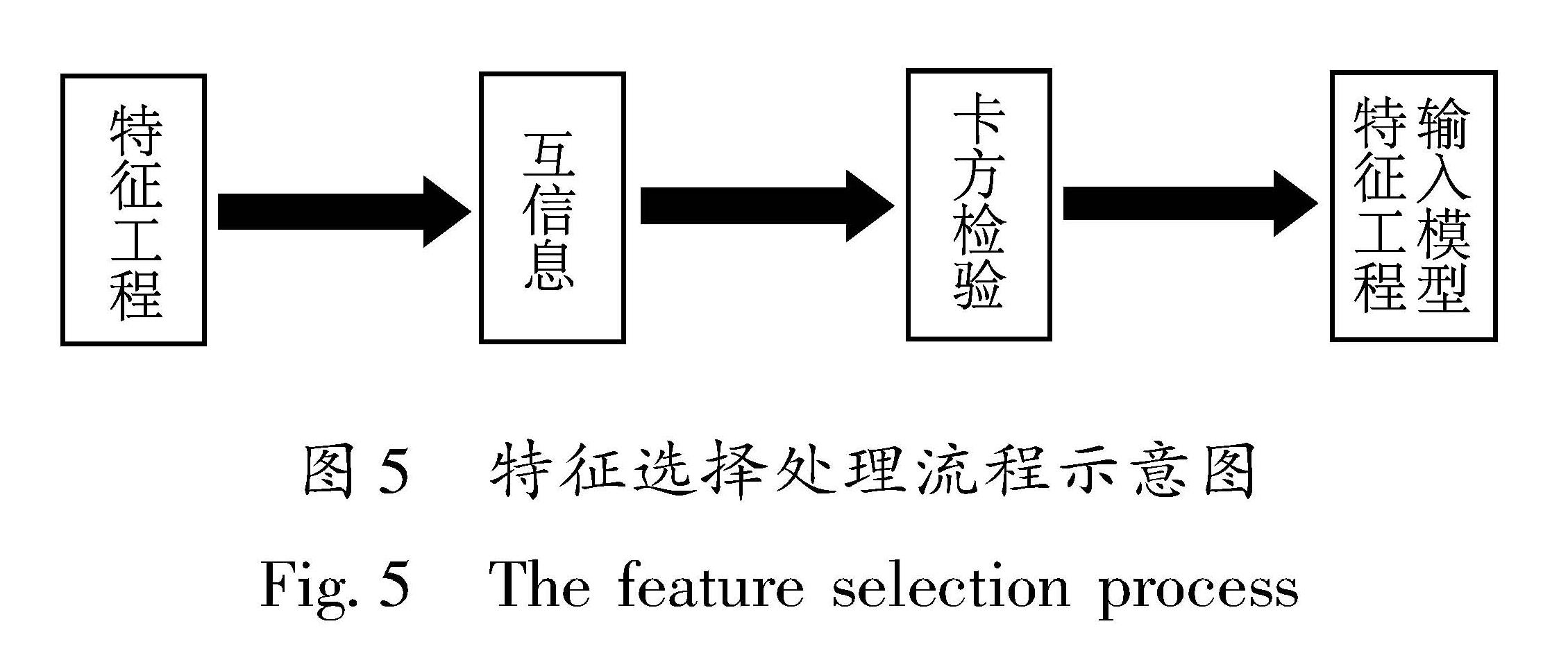
特征选择旨在通过去除不相关、冗余或嘈杂的特征,从原始特征中选择一小部分相关特征,以减少算力和存储消耗并简化模型,以便于实际应用过程中的特征构建。
对于地震预测问题,目前尚难有足够的认识去判断特征与目标之间、特征与特征之间的相关性。这种情况下需要依靠数学或工程上的方法来更好地进行特征选择,常见的方法有过滤法、包裹法、嵌入法等,其中过滤法按照发散性或者相关性对各特征进行评分。设定阈值或者待选择阈值的个数特征选择,常用的有方差选择法、相关性选择法、特征重要性选择法、互信息选择法、卡方检验选择法 微尘-黄含驰.2022.特征选择——详尽综述.https://zhuanlan.zhihu.com/p/514845162.。
图4 测试数据取不同比例值时决策树预测正确的样本率
Fig.4 Correct sample rate of decision tree prediction when taking different proportional values for test data
本文特征选择处理流程如图5所示。图中互信息可用于表征随机变量之间的相互依赖或相关性程度(蒋海昆,王锦红,2023),而卡方检验表征的是统计样本的实际观测值与理论推断值之间的偏离程度。实际观测值与理论推断值之间的偏离程度决定卡方值的大小,卡方值越大表明二者偏差程度越大,反之二者偏差越小。若两个值完全相等,卡方值就为0,表明两者完全符合。
图5 特征选择处理流程示意图
Fig.5 The feature selection process