支持向量机(SVM)(Cortes,Vapnik,1995)是一种常用的监督学习方法,其数学模型是基于1范数的损失函数,这使得其训练过程需要求解复杂的二次规划问题。而LS-SVM在继承SVM优点的情况下,将二次损失函数引入SVM,并将不等式约束条件替换为等式约束条件,极大地提高了计算效率。给定一组数据集{(xi,yi)}Ni,i=1,2,……,N,其中xi∈Rn为解释变量,yi∈R为响应变量,LS-SVM通过将目标函数最小化来找出解释变量与响应变量之间存在的非线性映射关系。其数学模型为:
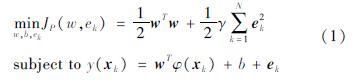
式中:e=[e1,e2,…,eN]T∈RN为误差变量; w=[w1,w2,…,wh]∈Rh和b∈RN通过使目标函数最小化得到; γ为正则化参数; 高维向量构建的矩阵φ(x)=[φ(x1),φ(x2),……,φ(xN)]T∈RN×h, 其中φ(·): Rn→Rh表示从n维到具有h维的高维度希伯特空间的映射函数; 响应或输出变量y=[y1,y2,……,yN]T∈RN。用拉格朗日乘子法将方程(1)的求解问题转换为对偶问题求解,并引进拉格朗日乘子,以构建拉格朗日函数:
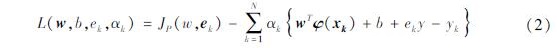
式中:α=[α1,α2,……,αN]T∈RN为拉格朗日乘子。利用Karush-Kuhn-Tucker(KKT)条件的最优性求解式(2),即分别求拉格朗日函数对w,b,ek,αk的偏导数,可得:
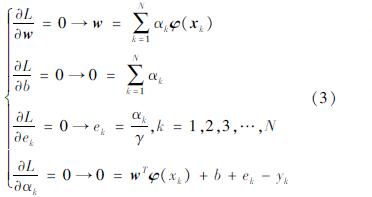
特征向量之间的内积在计算时较为复杂。为此,本文选用高斯核函数代替特征向量之间的内积,其计算模型如下:
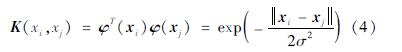
式中:σ2为核参数。LS-SVM模型的预测精度与两个超参数(σ2和γ)的取值息息相关,因此,本文引入樽海鞘优化算法(SSA)对其进行确定。此外,为了识别数据集中最能影响模型预测性能的解释变量组合(即最优特征组合),本文构建了一个控制解释变量组合的参数f,并将其作为优化参数耦合进SSA中,与前述两个超参数同时进行优化,进而形成樽海鞘算法优化支持向量机(SSALS-SVM)的数学模型。具体过程如下所述:
首先,给定f、σ2和γ 的取值范围,随机生成n个(f,σ2,γ)组合,其数学模型为:
(fi,σ2i,γi)=rand*(ub-lb)+lb,i∈(1,2,…,n) (5)
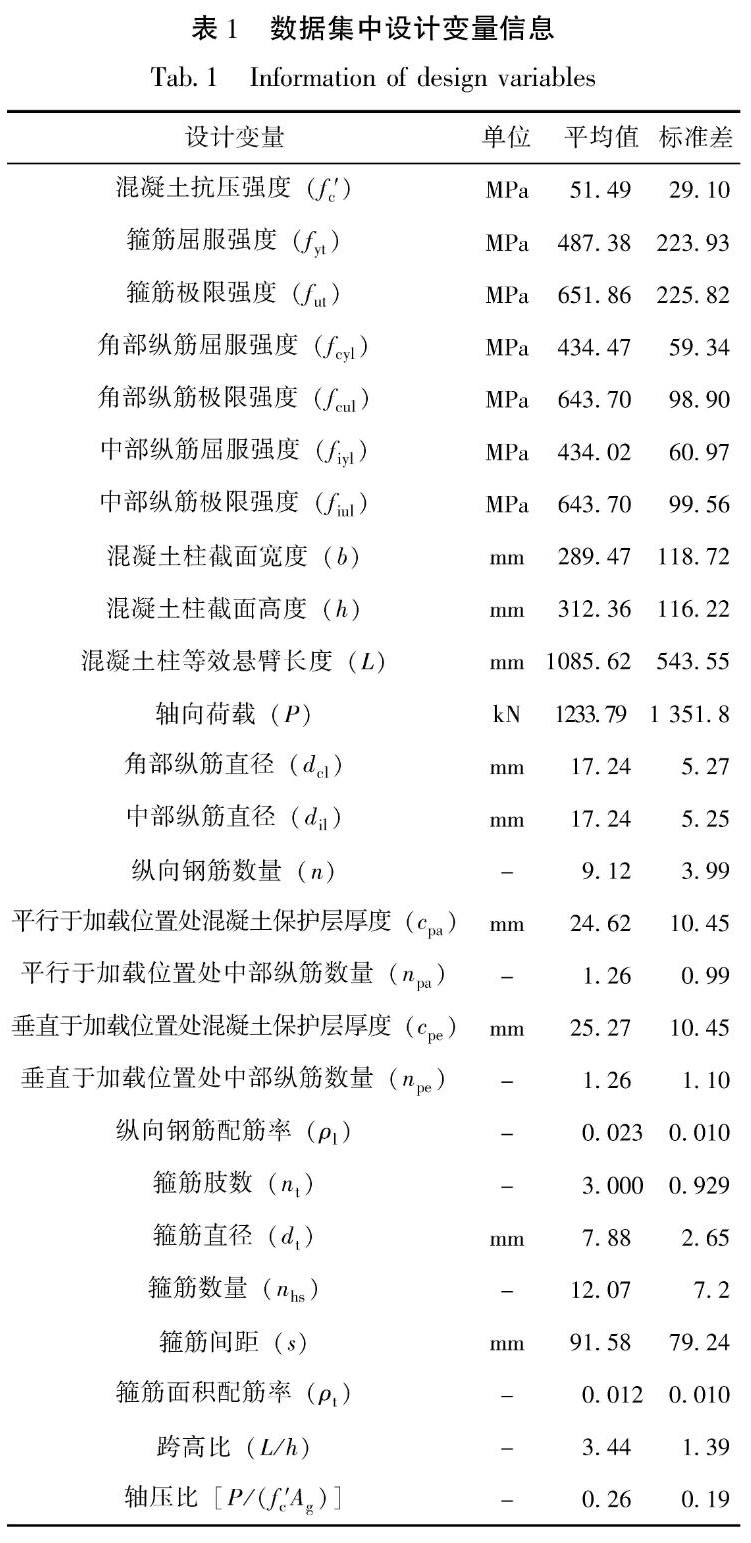
式中:f为挑选的特征数目; ub为f、σ2和γ的上界; lb为f、σ2和γ的下界; d为参数的数目。根据随机生成的f数值,随机从数据集中选取f个解释变量进行组合,作为最优特征组合的候选者。此外,σ2和γ也需要同时进行优化,因此需要建立f +2个决策变量,具体形式如图1所示。
图1 超参数和输入变量组合形式
Fig.1 Combination of hyperparameters and input variables
如图1所示,Pf为随机挑选的解释变量。将σ2、γ 以及Pf输入目标函数中进行评估。对于目标函数,其建立过程如下所示:联立式(3)中的各方程式,消除方程式中的w和ek,化简可得:
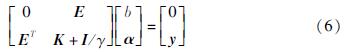
式中:E=[1,1,…,1]1×N; I为单位矩阵; K为核函数组成的核矩阵。
通过求解矩阵方程(6),可得模型参数α和b,进而可建立对偶空间下的预测模型,其表达式为:
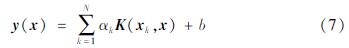
为了判断上述建立的f个解释变量是否为最优特征组合以及生成的σ2和γ值是否为最优参数,需要使用一种评估函数对通过方程(7)得到的结果进行评估。为此,本文采用均方误差(MSE)作为模型性能优劣的评估标准。其数学模型为:

因此,目标函数由方程(7)和方程(8)组成:方程(7)对结果进行预测,方程(8)对预测结果进行评估。基于已建立的目标函数,对n个(f,σ2,γ)组合进行评估,并对比n个MSE的大小,取其最小值作为本次评估的最佳适应度,对应的(f,σ2,γ)组合作为当前最优位置F。
将n个(f,σ2,γ)组合前一半设定为领导者,后一半设定为跟随者。领导者的位置跟F相关,根据F,通过一次次位置更新,不断向其靠近,位置更新公式为:
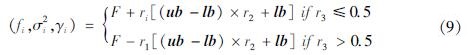
式中: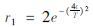 ; t表示当前迭代次数; T表示最大迭代次数; r3和r2是一个0~1的随机数,r3大于或小于0.5将决定领导者前进还是后退。跟随者的位置则与前一个个体位置相关,其数学模型为:
; t表示当前迭代次数; T表示最大迭代次数; r3和r2是一个0~1的随机数,r3大于或小于0.5将决定领导者前进还是后退。跟随者的位置则与前一个个体位置相关,其数学模型为:
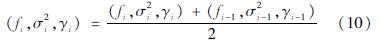
对于更新后的领导者和跟随者,其位置可能会超出设定的范围,因此需要将其重新限制到规定范围内。此外,当领导者和跟随者位置迭代更新后,需重新对其进行评估:将更新后的(f,σ2,γ)组合重新代入方程(4)、(6)和(7)中计算其预测值Ay^G1,并通过方程(8)计算其MSE。将更新后的每个(f,σ2,γ)组合的MSE与当前最佳适应度进行比较,若更新后的(f,σ2,γ)适应度优于当前最佳适应度,则以MSE更优的(f,σ2,γ)组合作为F。
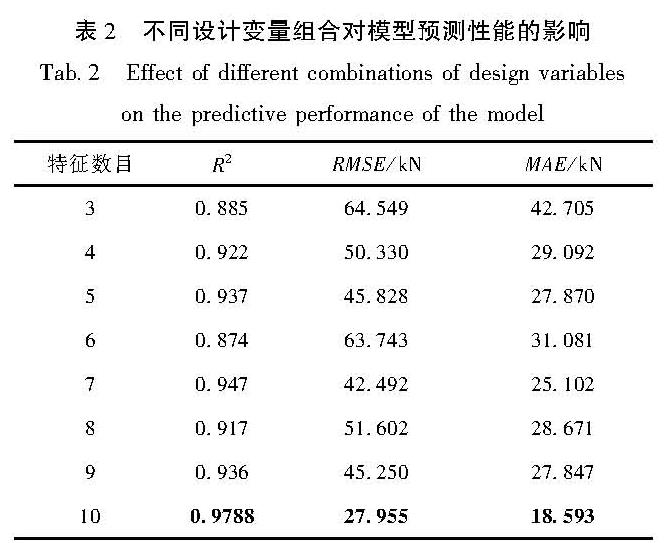
重复以上步骤,直到达到最大迭代次数或适应度达到最佳(MSE=0),输出当前的F作为最优(f,σ2,γ)组合,并输出最优特征组合(P1,…,Pf),进而可得到LS-SVM预测模型的最优
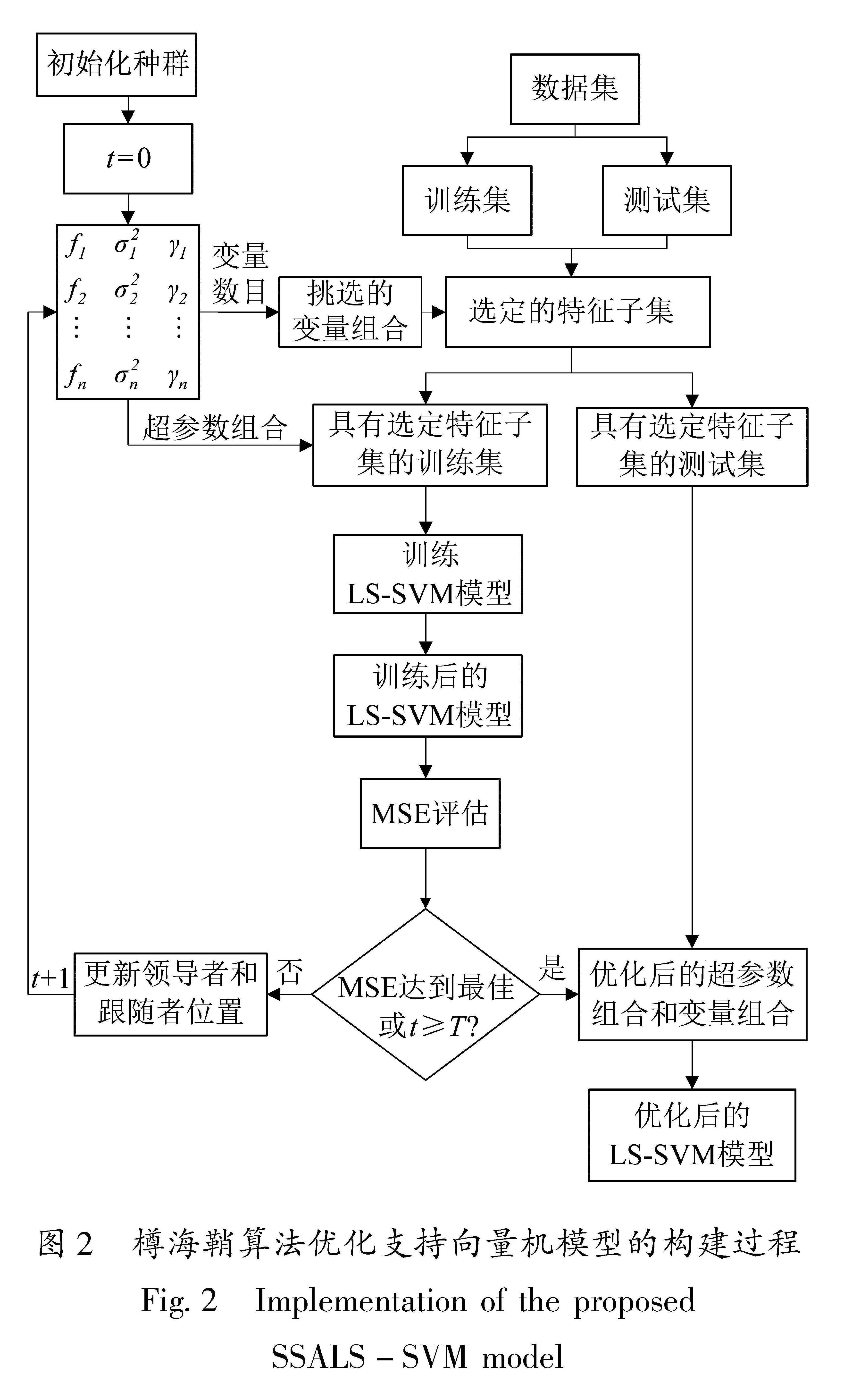
图2 樽海鞘算法优化支持向量机模型的构建过程
Fig.2 Implementation of the proposed SSALS-SVM model
形式。因此,从理论分析上看,本文提出的SSALS-SVM方法既能够优化模型的超参数σ2和γ,又能自动筛选数据中最能影响模型预测性能的解释变量x,形成最优特征组合(P1,…,Pf)。
给定一组数据集,图2描述了本文提出的SSALS-SVM的构建过程,其大致分为以下几个步骤:
①随机生成n个(f,σ2,γ)组合。
②将生成的n个(f,σ2,γ)组合输入目标函数中进行评估,以确定F。该过程需要将控制解释变量组合的参数f转化为f个解释变量构成的特征组合。
③更新领导者和跟随者的位置,并重新对更新后的(f,σ2,γ)组合进行评估。
④重复迭代,直到达到最佳适应度或最大迭代次数,输出最佳超参数组合和最优特征组合,进而得到最优LS-SVM模型。