高精度地震定位是唯一能够揭示发震深度和断层几何形态的方法(Waldhauser,Ellsworth,2000; Mendoza et al,2019),一般使用大地震后余震的空间分布提供先验的断层几何模型,并据此反演地震破裂过程(Ross et al,2019); 波形相似度分析能够将空间上重叠的微震事件聚类为属于不同子断层的集群,从而展示出高精度的断层结构(Shelly,Hardebeck,2019)。因此获取研究区微震活动分布可为进一步开展该地区的强震危险性预测提供基础。
目前国内外学者优先使用双差地震定位方法获得高精度的地震定位结果,用以分析地震活动的空间分布特征及其与活动构造之间的关系,该方法在一定程度上消除了地壳速度结构横向不均匀性带来的定位误差,进而在计算中消除了路径异常(实际走时相对于由模型计算得到的理论走时的偏离),因此比常规绝对地震定位方法的精度更高(Waldhauser,Ellsworth,2000)。在实际工作中,双差地震定位方法在对特定断裂周围发生地震后的余震序列进行重新定位方面具有显著优势(Fang et al,2013; 龙锋等,2021; 王未来等,2021),但处理大规模数据集(例如超过3万次地震的震相数据)时,由于受计算机内存的限制,传统的双差地震定位程序可能会遭遇运行障碍。[HJ1.95mm]故当研究区域范围较大且地震活动密集时,如何有效划分子区域以实施精确定位成为一个亟待解决的问题。一种常用的策略是将研究区域分割为多个较小的子区域,依据网格或特定几何形状进行划分,并对每个子区域进行重新定位,最后将各个子区域的结果合并(Shearer et al,2005; Zhou et al,2022)。为了保证边界地震事件的准确性,通常需要设置一定的重叠区域,但这种方法可能会导致同一地震事件在不同子区域内重复定位,出现震中位置和发震时间不一致的情况,原因在于去除这些重复记录增加了人为因素的影响。
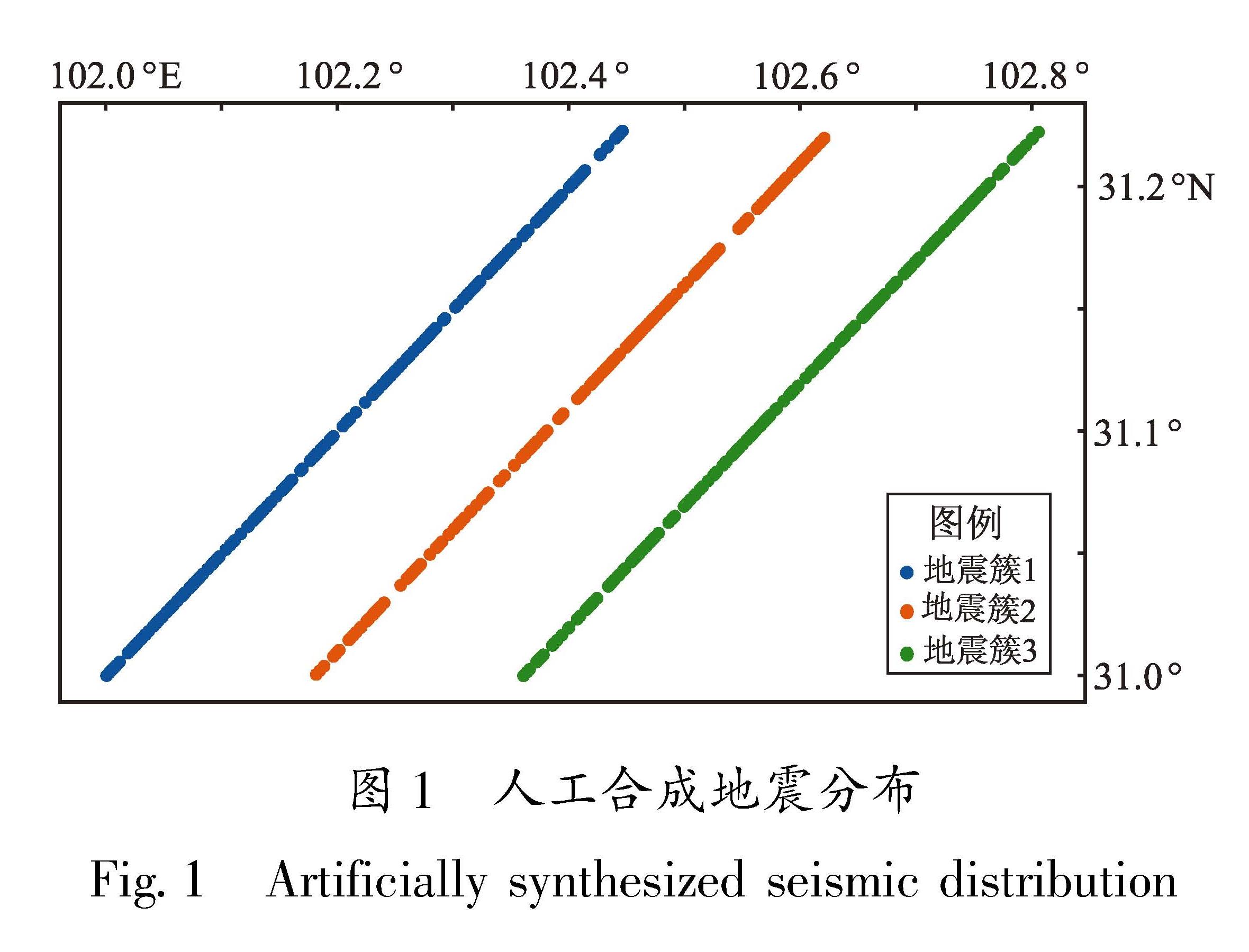
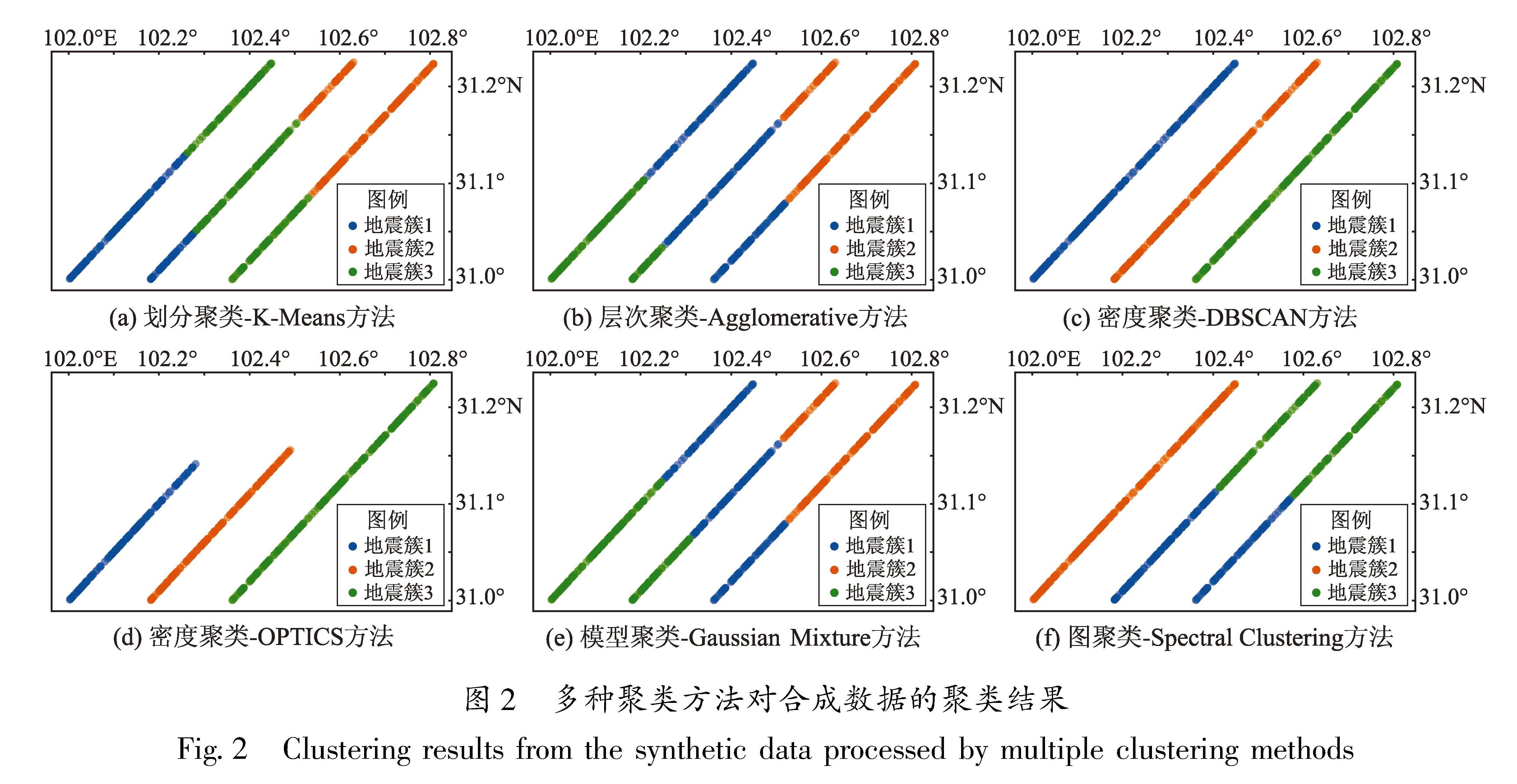
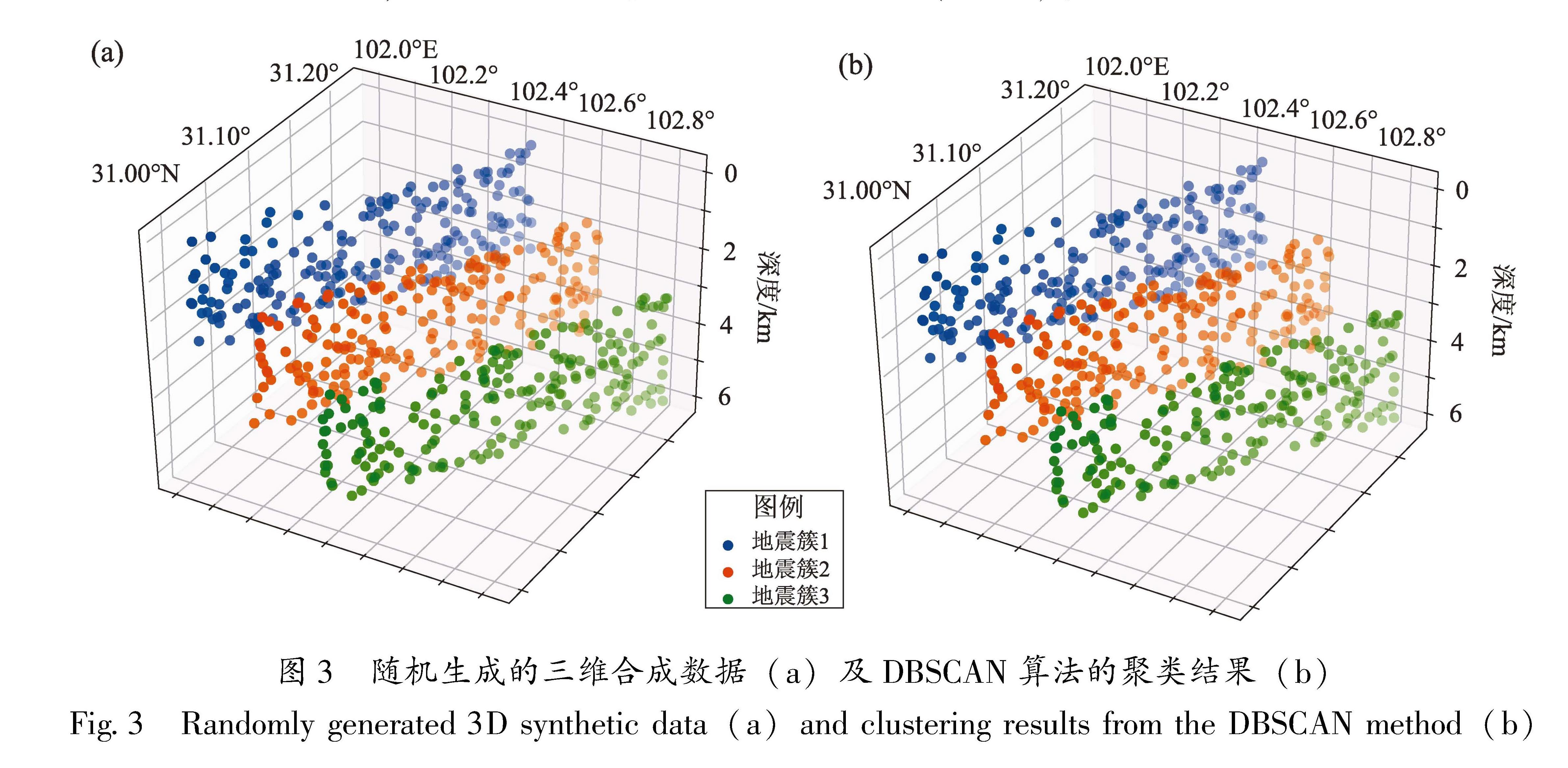
近年来,随着计算技术的迅速发展,机器学习聚类算法可以较好地解决上述问题,能够在没有预设答案的情况下揭示数据中的潜在结构,旨在根据数据间的相似性将其分组,使得同一个簇内的对象尽可能相似,而不同簇的对象之间则具有较大的差异。根据聚类算法思想和实现方式的不同主要有划分聚类、层次聚类、密度聚类、模型聚类和图聚类。其中划分聚类是以某种方式选择一个聚类中心,根据一定的距离度量将数据点划分到不同的簇中,如K-Means算法等; 层次聚类是将数据集按照一定的层次进行分解,形成树状的聚类结构,如Agglomerative算法等; 密度聚类是通过分析数据点之间的密度(或距离)发现聚类,如DBSCAN和OPTICS算法等; 模型聚类是假设每个簇都服从一个概率分布或模型,使用模型拟合数据并发现聚类,如Gaussian Mixture Model(高斯混合模型)算法等; 图聚类是将数据点视为图中的节点,通过图的划分或社区发现算法识别聚类,如Spectral Clustering(谱聚类)算法等。本文对以上几种算法进行了检验,综合对比发现DBSCAN密度聚类算法效果较好。
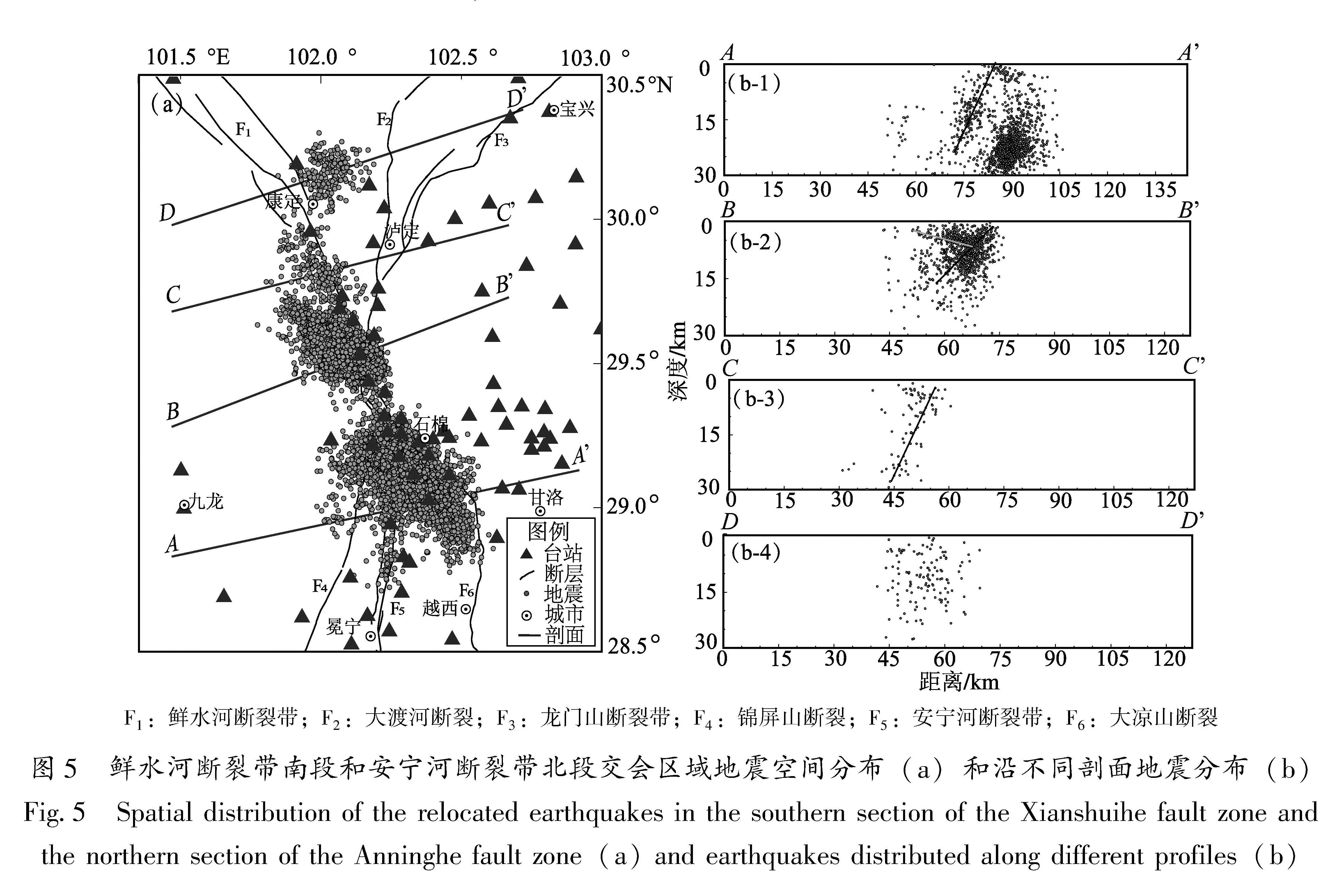
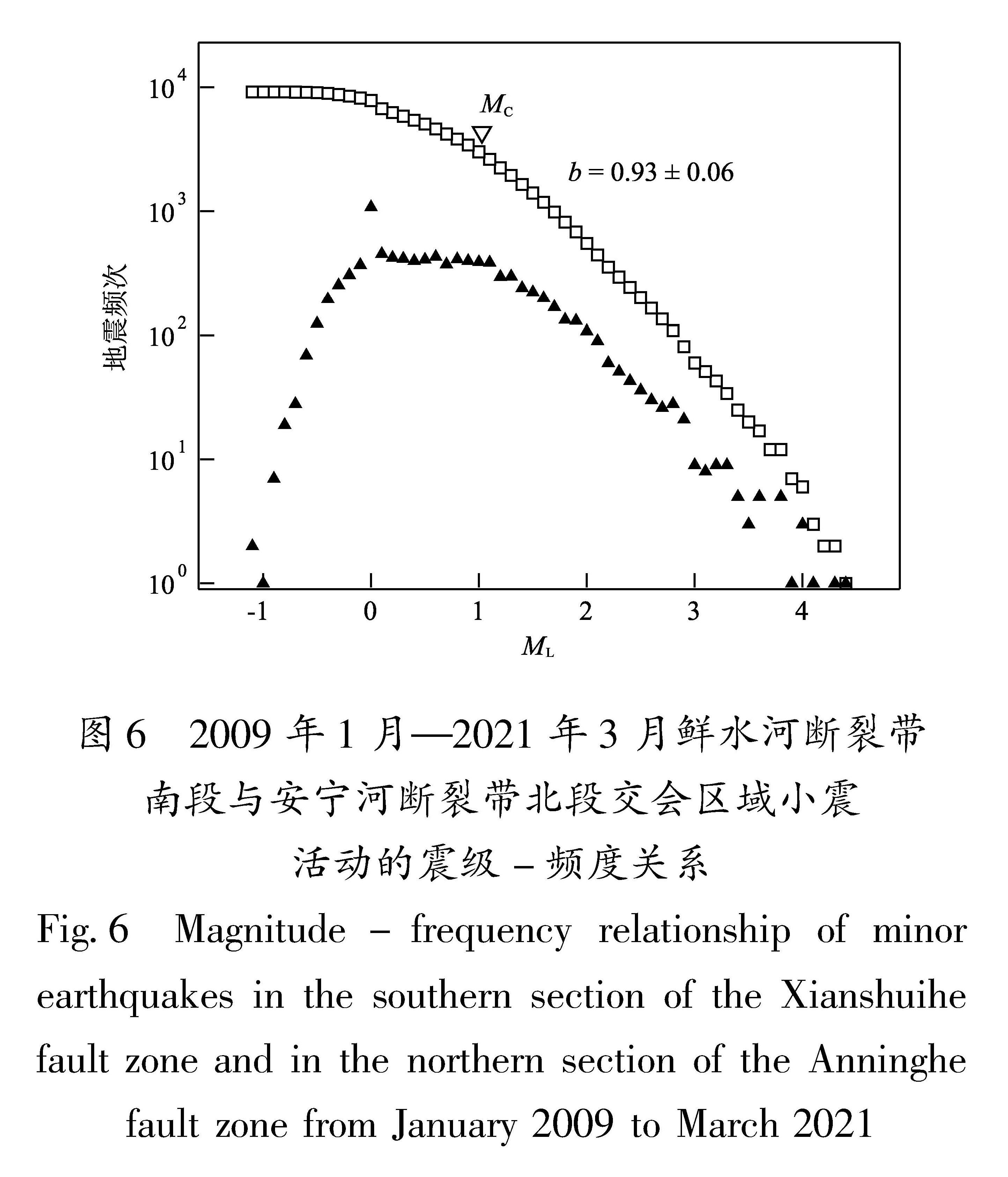
川滇地区位于青藏高原东南缘,包括多个活动块体和一系列不同规模、产状各异、活动速率不同的断裂,地质构造复杂,是我国地震活动最强烈的地区之一,自1900年以来该地区发生了多次M≥6.0强震。2008—2009年国家数字测震台网基本建成,地震台站的密度进一步增加,布设也更加合理,监测能力有了大幅提高。2009年1月—2021年7月,国家数字测震台网记录到川滇地区发生的地震事件多达32万余条,利用这些地震事件开展地震精定位工作可为该地区开展强震危险性预测提供基础信息。本文使用DBSCAN算法对川滇地区共322 070个地震事件进行了聚类,共得到9个明显地震簇,使用双差地震定位方法对其中的鲜水河断裂带南段和安宁河断裂带北段交会区域的地震簇以及鲜水河—安宁河断裂带西北部区域的2014年康定MS6.3地震序列地震簇进行了精定位,分析了地震空间分布特征,并对2009年1月—2021年3月鲜水河断裂带南段与安宁河断裂带北段交会区域开展b值扫描,用于分析和揭示断裂带当前构造应力积累的相对水平的空间差异,进而分析断裂(段)当前活动习性与潜在强震危险段落(易桂喜,闻学泽,2007)。