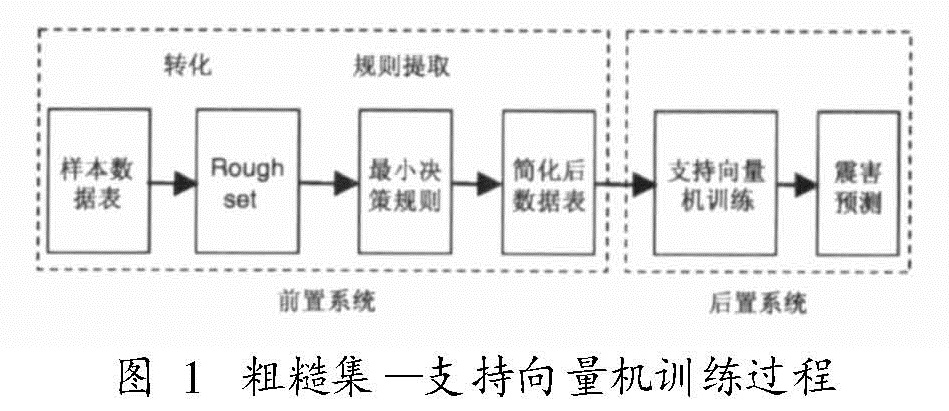
3.1 宏观震害经验及震害影响因子
随着我国经济的飞速发展,近年来新建了大量高层建筑,但还存在一定比例老旧房屋和一些抗震性能较差的房屋,其中多层砖房问题尤为突出。笔者以多层砖房为研究对象,从狭义震害预测角度分析了建筑物的易损性,即对结构在确定的地震强度作用下,发生某种破坏程度的概率或可能性进行了预测。多层砖房在地震作用下,其破坏的部位、特点以及具体形态多种多样,但概括起来,可依据其破坏的程度将震害划分为5个等级(表1),大量的宏观震害经验表明,多层砖房的震害程度与下列因素密切相关。
(1)地震特性。在以往的研究中,通常采用烈度指标表示地震特性,而本文选取地面加速度峰值作为地震特性指标。震害经验表明,对于强震而言,地面运动力特别是地面运动水平加速度峰值是造成建筑物破坏的主要因素; 而且以峰值加速度和特征周期为参数的中国地震区划图已颁布实施。
(2)场地与地基条件。大量宏观震害资料表明,地震破坏程度不仅与地基有关,而且与建筑物的刚度有关。松软的地基上,地基的沉降会使其上部结构遭到局部破坏,而强烈振动是导致坚实地基上刚性建筑物破坏的主要原因。如果把刚性建筑物修建在松软地基上,则地基能吸收地震的部分能量,从而起到隔震的效果。在松软地基上的柔性房屋,其破坏原因是地震波产生低频率共振而造成的。由于地震重复性荷载的作用,地基因液化和强度骤然降低而失去稳定性,建筑物基础的竖向和水平位移以及地基的不均匀沉陷,往往是松软地基上建筑物遭受破坏的主要原因。一般说来,基岩上的地震烈度约比一般土层要低1度,而软弱土层上的地震烈度比一般土层要高近1度; 从水文地质方面来说,地下水浅的地区比地下水深的地区效应大,破坏重; 从地形地貌方面来说,地形地貌复杂的地区地震效应大,破坏严重(刘本玉,2001)。
(3)建筑物层数与层高。房屋的层数与层高不仅影响房屋的空间刚度,而且使房屋受到的地震力的大小亦大为不同,层数越多,层高越高,其震害就越重。
(4)房屋的整体性。在多层砖房中,水平承重构件为楼屋盖。历次震害表明,现浇钢筋混凝土、预制混凝土与木楼屋盖的地震表现是有差异的,其原因是现浇楼屋盖整体性最好,预制楼屋盖次之,而木盖最差。横墙承重或纵横墙承重的房屋比纵墙承重的房屋抗震能力要强; 用钢筋混凝土构造柱和圈梁来增强多层砖房的抗倒能力效果显著。
(5)建筑物体型。建筑体型对建筑结构的抗震性能有着显著的影响,当建筑体形不规则,墙体位置不均匀,建筑物刚度中心与荷载作用点有较大间距时,会产生扭转。当在水平地震力作用下剪切与扭转组合时,其所受应力加大,震害显著加重。特别是平面突出部分与主体中心部分震动不同步时破坏更明显。同样地,多层砖房在立面竖向的变化,即刚度在竖向的不均匀或突变也使震害更为严重。
(6)施工质量。施工质量对房屋抗震性能的影响是显而易见的。施工质量好、达到抗震设计标准的房屋抗震能力就好; 施工质量差的房屋其抗震性能必定不好。建筑年代的影响也需要综合考虑。
(7)含砖墙率。它表达了房屋的刚度、强度、空旷程度等特征。含砖墙率越大房屋的空间刚度越大,抗剪能力越强,震害就越轻。
(8)承重墙体砂浆标号。多层砖房的地震破坏主要是由于砖墙首先开裂,这是由砂浆强度较低造成的。
在用特征向量建立预测模型时,除了要考虑各因子对房屋结构的抗震性能的影响外,还需考虑参数的容易获取性和关联性(或独立性)。
3.3 实例及分析
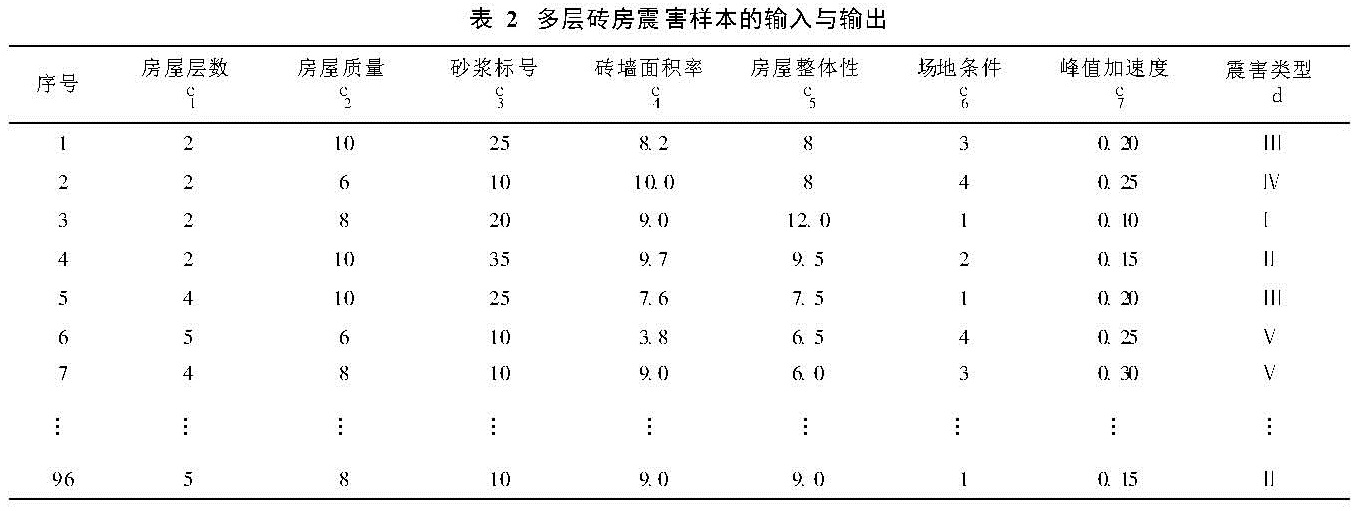
笔者收集了1966年云南东川地震、1978年唐山大地震、1988年云南澜沧—耿马地震、1995年云南武定地震和1997年云南丽江地震、2001年云南施甸地震、2007年云南保山隆阳地震中的多层砖房震害资料(刘恢先,1986,缪升等,2000,白良等,1989,汤皓,2006,非明伦,2002,2007),选择其中96个样本用于训练基于粗糙神经网络的多层砖房震害模型。
本文选择以下震害影响因子:房屋层数、房屋质量、砂浆标号、砖墙面积率、房屋整体性、场地条件、地震峰值加速度作为模型的输入。对于定性指标参考专家经验赋值。① 房屋质量:施工质量优取为10、中取8、差取6,同时考虑建筑年代进行房屋折旧,每5年减0.5; ② 房屋的整体性:楼盖和屋盖,现浇取5、预制取4、木屋盖取3,有圈梁加1、有构造柱再加1,有地下室、筏基加1,房屋开裂减1; ③ 场地条件:Ⅰ类场地取1、Ⅱ类取2、Ⅲ类取3、Ⅳ类取4。将给定地震下可能的建筑物的震害程度为模型的输出震害作为系统的最终输出,把震害程度划分为5级:基本完好、轻微破坏、中等破坏、严重破坏、毁坏,所收集的样本资料如表2(限于篇幅仅列出部分样本)。
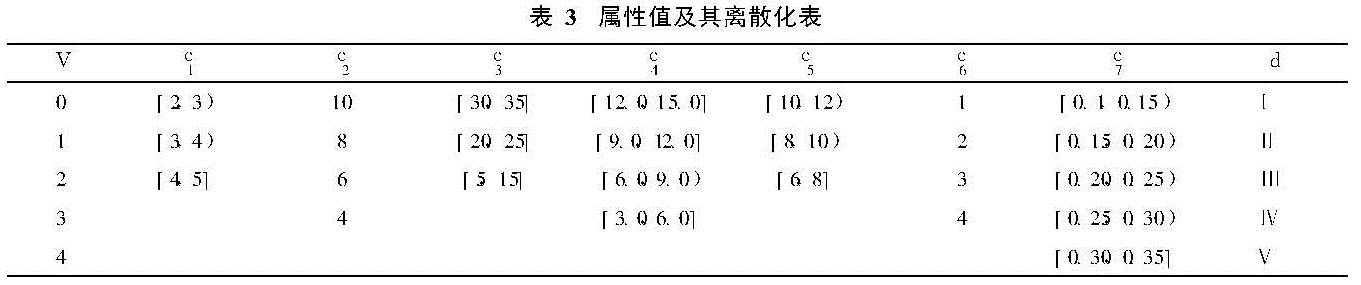
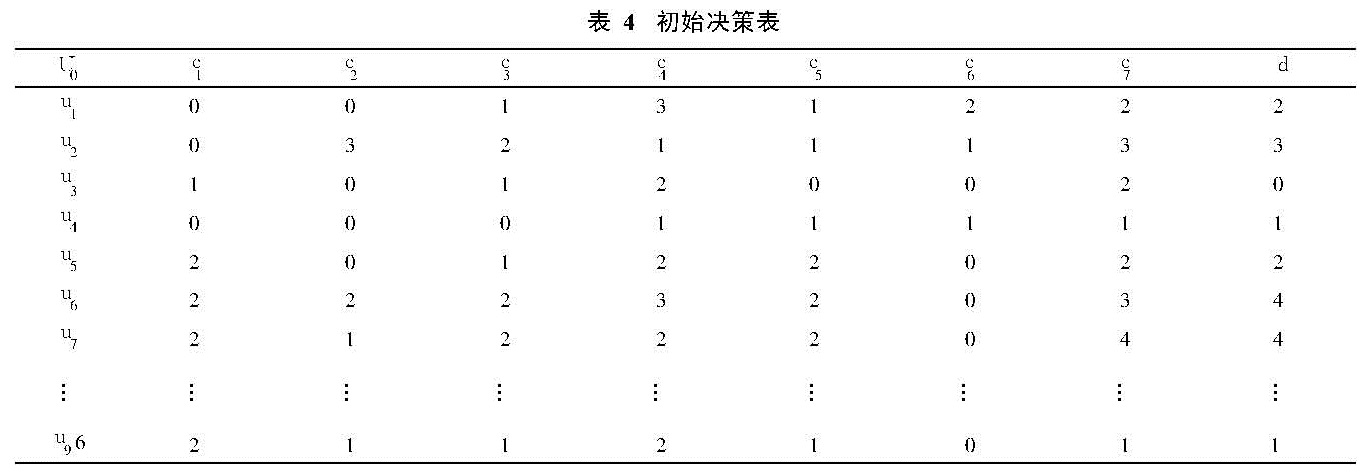
震害预测信息系统S=(U,R,V,f)中,将研究区域内的全部建筑物组成的集合作为论域U={U1,U2,…,U96},震害影响因子作为条件属性C={c1,c2,c3,c4,c5,c6,c7},给定地震加速度峰值下建筑物可能的破坏程度为决策属性D={d1,d2,d3,d4,d5},其中d1=基本完好、d2=轻微破坏、d3=中等破坏、d4=严重破坏、d5=毁坏,属性集R=C∪D,C∩D≠φ。决策表的表头为各属性,其每一行表示论域中的一个事例或称一条决策规则,每一列表示属性及属性值。各因子变化范围及其离散化值如表3,按表3离散化后形成初始决策如表4。
利用本文前述的重要性概念,分别分析建筑震害影响因子(条件属性)的重要性。
(1)按决策属性D对U进行划分得:U/D={Y1,Y2,Y3,Y4,Y5},其中,Y1={U3,U8,…,U90}23, Y2={U4,U9,…,U96}31,…, Y5={U6,U11,…,U93}9,下标表示组中所含元素的个数。则可得p(Y1)=23/96, p(Y2)=31/96, …, p(Y5)=9/96。
(2)按条件属性C={c1,c2,c3,c4,c5,c6,c7}对U进行划分得U/C={Xi,X2,…,X81},可计算出X1={U1}1, X2={U2}2, …, X81={U81}81,则可得p(X1)=1/96, p(X2)=1/96, …, p(X81)=1/96。计算条件信息熵得H(D/C)=-∑81i=1p(Xi)∑5j=1p(Yi/Xi)lgp(Yj/Xi)=0。
(3)按式(8)计算各因子的重要性系数γi,得γ1=0.023, γ2=0.009, γ3=0.018, γ4=0.049, γ5=0.034, γ6=0.025, γ7=0.012 7,各因子的重要性排序为:γ7>γ4>γ5>γ6>γ1>γ3>γ2,若取ε=0.02,得该决策表的条件属性集C相对于D的一个近似相对简约B={C1,C4,C5,C6,C7}。
将经过条件信息熵简约后的5个关键特征因子{C1,C4,C5,C6,C7}作为支持向量机的输入向量,而以建筑物震害等级D作为输出。用对决策表进行约简后得到的规则作为样本数据进行训练。选择径向基函数作为核函数,即
K(x,xi)=exp(-│x-xi│2/σ2).(13)
式中,xi,xj为训练输入,σ为核函数宽度。
支持向量机的训练参数为σ和C。σ的大小影响样本的输出响应区间,当σ越小时,响应区间越窄,得到的分类面经验风险越小,表现为函数曲线光滑,但结构风险越大。惩罚因子C表征对错误的惩罚程度,C越大表示对错误分类的惩罚越大。我们通过试算,取σ=0.1,C=1 000。
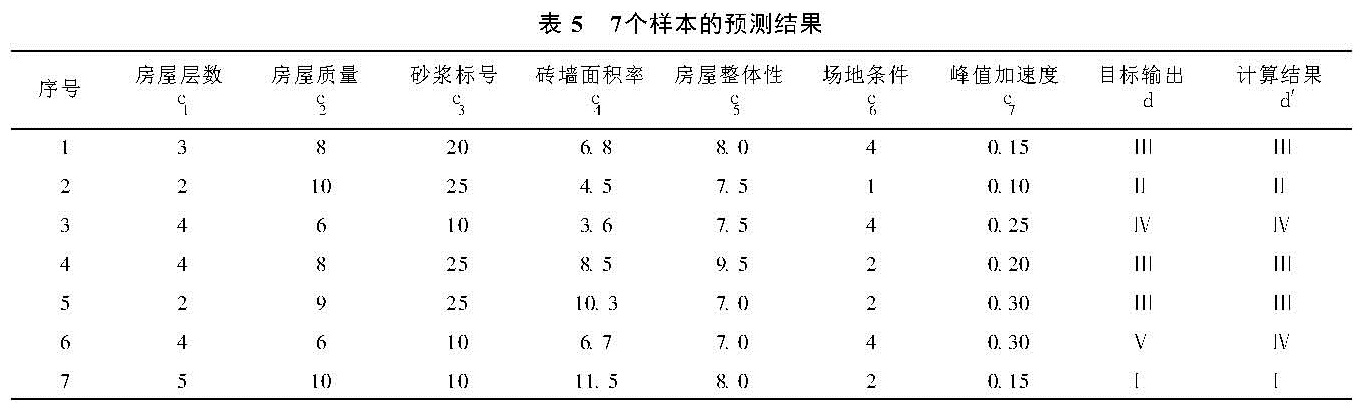
为了验证模型的性能,另选7个样本进行测试,计算结果如表5所示,除6号样本的预测结果有偏差外,其余6个样本的计算结果与实测结果完全吻合。出现误判的原因可能是由于建模所采用的原始样本中缺乏与6号相近的样本。因此,选样本建模时要特别注意原始样本的代表性。