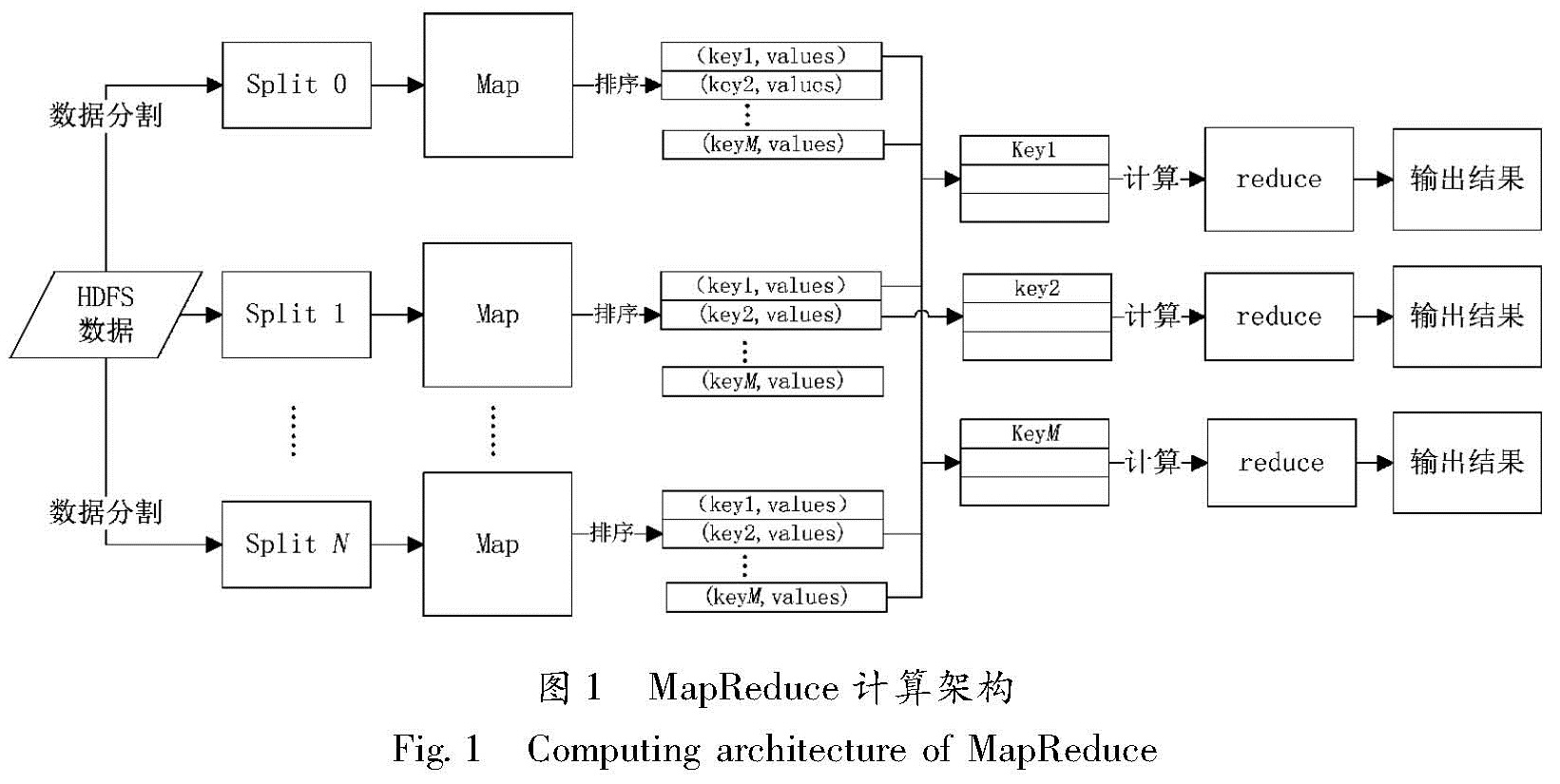
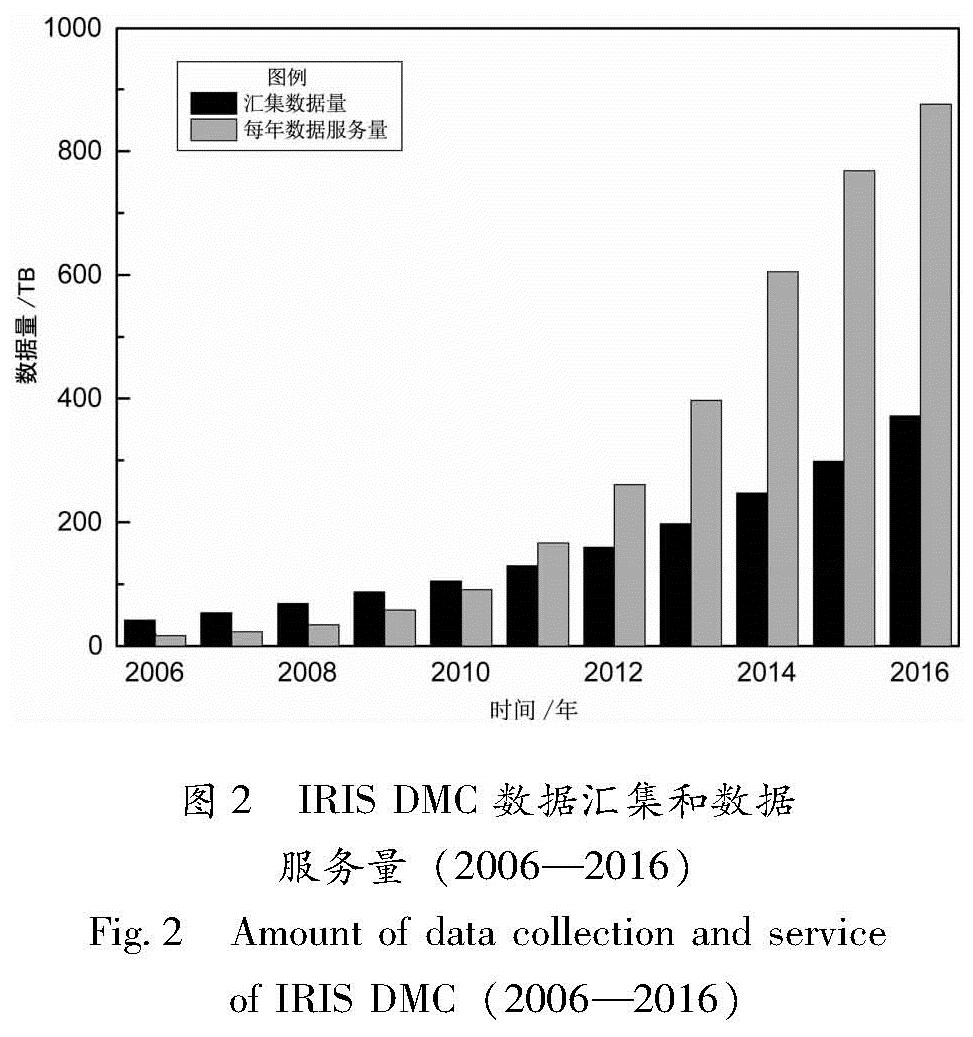
IRIS DMC 是全球地震台站最大的数据汇集中心和处理中心,世界各个地震研究中心和研究机构通过Wilber、SeedLink、ArcLink、WebService等标准传输方式从IRIS DMC获取数据。图2为IRIS DMC在2006—2016年期间数据汇集和数据服务情况,从图中可以明显看到汇集的数据量不仅从2006年的几十TB增长到现在将近400 TB,对外服务提供的数据量更是呈现爆发式增长,2016年的数据服务量比2006年增长了将近50倍,达到了900 TB。显然,如果采用普通的数据管理和服务方式,尤其是在破坏性大地震发生后面对全球用户的大量数据请求响应和处理下载,是无法满足规模日益增长的数据服务需求的。
图2 IRIS DMC数据汇集和数据服务量(2006—2016)
Fig.2 Amount of data collection and service of IRIS DMC(2006—2016)
中国地震台网中心从最初接入的47个国家标准数字地震观测台站(赵永等,2002),到已经实现了1 024个国家和区域地震台站的测震波形数据实时传输和汇集(郭凯等,2016),监测能力大幅提升的同时,需要实时处理和存储的数据量也达到了之前20多倍。以前将数据备份到光盘、磁带库的方式在急速增长的数据量面前暴露出数据易损坏、恢复难、数据导入导出速度慢等诸多问题。从数据服务的角度,由于国家测震台网西部分布相对稀疏,东部分布密集。如果M5.0~6.0地震发生在西部,震后时间波形数据由于台站密度相对稀疏,需要处理的台站数据相对较少。但如果发生在华北区域,按震中800 km选取地震台站30 min数据,最少需要处理300个台站产生约0.5 GB的数据,面对较多用户的数据处理和下载请求时,对系统IO和并发处理能力提出了非常高的要求,普通服务器很难满足。
2.1 基于Hadoop的测震数据存储模型架构设计
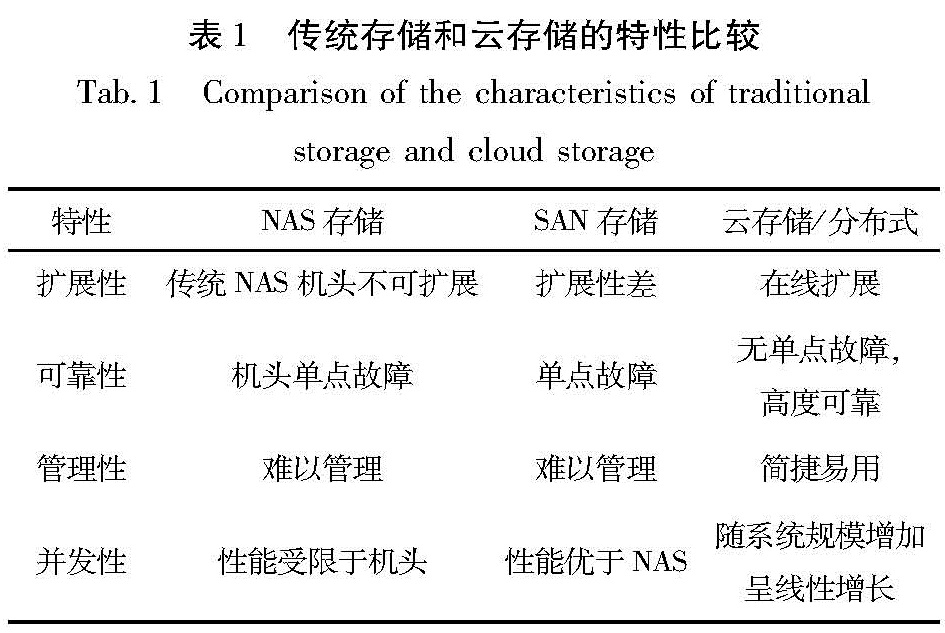
中国地震台网中心汇集的测震波形数据采用国际标准的Miniseed格式,以一个台站一个分项512字节、每个数据包1天24个小时数据做为一个文件的形式存储,目前所有的数据汇集在NAS存储上,受限于网络带宽以及NAS机头数量,传输速度很难超过100 M/s。在面对TB级规模的测震波形数据,单纯采用文件方式存储在数据汇集的速度、稳定性和安全性方面已经无法满足要求。表1为目前传统主要使用的存储和云存储特性比较。
表1 传统存储和云存储的特性比较
Tab.1 Comparison of the characteristics of traditional storage and cloud storage
目前国内已开展的地震大数据存储方式主要分为2种:①将数据按照原始格式导入Hbase中(王丹宁等,2016); ②对原始测震波形数据进行解压缩,整理成ASCII码放入Hbase中。由于Miniseed格式本身采用了Steim2的压缩算法,直接将其放入Hbase,对于提取数据时的计算效率会有一定的影响,而将数据解压成ASCII码的形式,则增长的数据量达到了将近4倍,会造成很大的存储消耗。从测震数据的使用需求来看,主要分为2种:①实时性计算,主要用于地震速报、地震预警和烈度速报等; ②数据分析,主要对历史数据进行计算分析,如噪声成像、区域速度结构等科学研究领域。由于HDFS是为了处理大型数据集分析任务的,是为达到高的数据吞吐量而设计的,这就可能要求以高延迟作为代价。
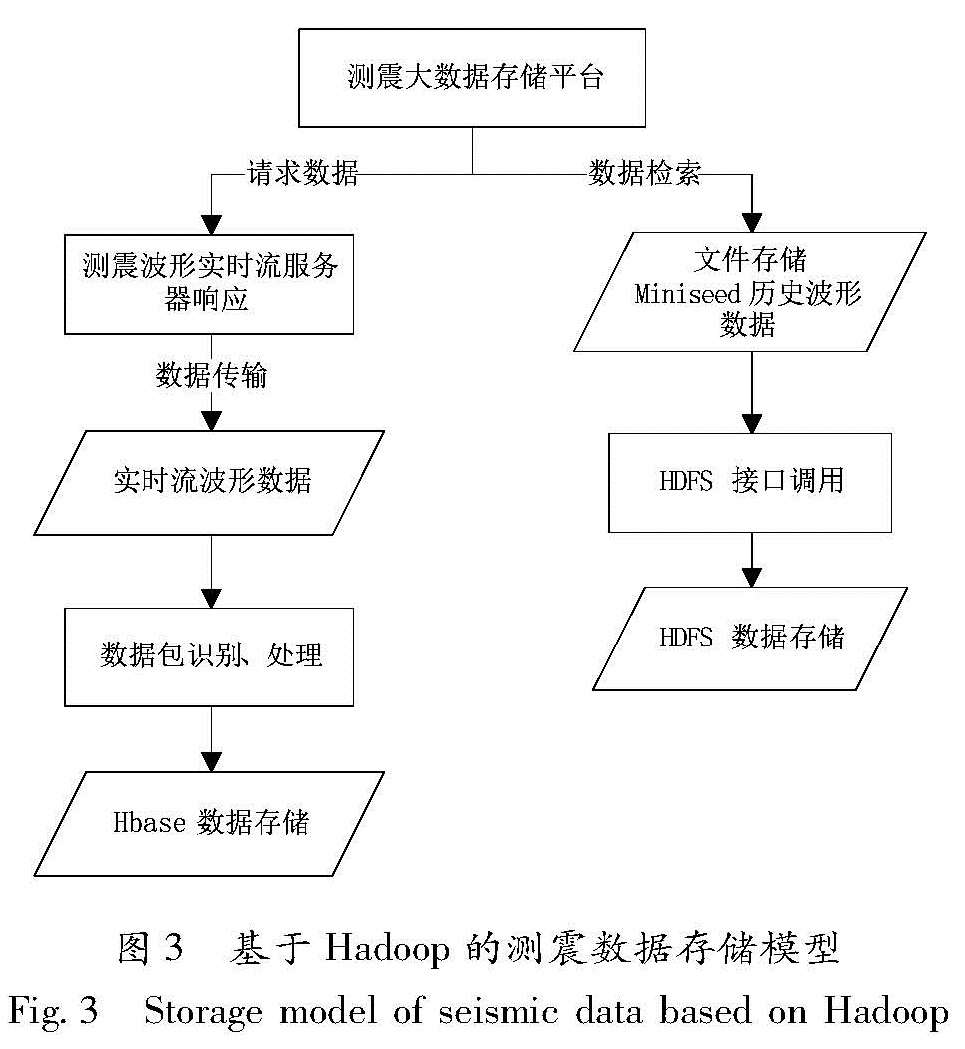
基于测震数据的实际业务需求和汇集情况,并且考虑到数据存储的成本,本文提出了如图3所示的基于Hadoop的测震数据存储架构。将实时数据和近期1年的测震波形数据放入Hbase中存储,这样可以满足对实时性计算要求较高的地震速报和地震预警要求; 将历史数据放入HDFS中,并采用1:3的比例进行数据备份,提高了数据的安全性,并可以开展基于MapReduce和Spark的高效计算。
图3 基于Hadoop的测震数据存储模型
Fig.3 Storage model of seismic data based on Hadoop
当然,测震数据在Hbase中的存储要结合实际的业务需求进行设计。目前国家台网中心采用基于JOPENS的SSS流服务器来负责接收和分发近实时波形数据,接收数据为512字节的纯数据SEED卷(Miniseed数据),包含有固定头段部分(48字节)和数据部分,主要记录台站名、通道名、记录起始时间、样本数目、测震数据等,以一个台站一个分项(周辉等,2011)。刘坚等(2015)对测震数据存入Hbase的数据结构进行相关设计和研究,设计了Row Key 为<Netid><Stationid><Pointid><Intrid><Itemid><Samplerate><Timestamp><Protype>,主要基于512字节数据头段所包含的台站信息来进行数据的快速检索(刘坚等,2015)。根据台网中心的测震波形文件存储格式,并考虑实际业务需求和数据检索效率,本文设计了如表1所示的基于Hbase的测震波形数据存储格式。考虑性能和维护性,采用每月数据存储在一张表的设计思想,每张表有2列,一列是ROWKEY,另一列存储每条实时流,以北京BST台站2016年4月9日16点10分32秒接收到的数据为例,设计的表结构如表2所示。
表2 基于Hbase的测震波形文件存储格式
Tab.2 Seismic data format based on Hbase
ROWKEY设计的月份_时间戳_台网代码_台站代码_测项_分项_采样率,可以从实时流中的数据头段解析而来,VALUE为整个实时流数据。由于很多测震数据的研究往往以台网为单位进行数据处理,为了进一步提高数据的检索效率,可以基于台网编码建立二级索引来进一步提高数据的检索效率,但在提高效率的同时要付出消耗更多空间的代价。
2.2 数据管理和计算模型设计
测震波形数据质量控制是数据共享和服务非常关键的一步,而运行率是评估台站数据质量在一定时间范围内的一个重要指标。如果以5年全国测震台站波形数据1 024个台站约65 TB数据,每个台站1个分项1小时运行率作为基本单位进行统计并存储该小时段的运行率,则产生的数据量超过了2亿多条,而传统的数据库如Mysql在规模达到几百万条数据的时,检索的速度就已经达到了瓶颈,同时,计算如此海量的数据,即使采用高性能计算机进行数据运行率检索,也会受限于IO瓶颈和CPU的数量,计算的时间会非常漫长。
基于台网中心目前的数据存储情况以及本文设计的测震数据存储模型,设计了一套基于Hadoop的分布式历史数据运行率检索计算模型,同时兼容考虑了对实时流数据运行率的实时检索,如图4所示。模型基于表2的数据存储结构将历史数据首先导入HDFS中,采用Spark计算模式开展多节点的数据运行率计算,以小时为周期将计算结果实时放入Hbase中,实时流数据的计算流程同历史数据一样,结果放入MySql,并按一定周期导入Hbase中。
图4中,自底向上分为3个层面。第1层是数据源层,主要包括地震波形数据文件以及测震实时流,最新的地震波形数据文件存储在NAS存储服务器上,可通过脚本将其挂载到本地进行读写,历史地震波形数据文件存储在HDFS分布式文件系统中,用HDFS接口进行存储和访问; 第2层是处理层,主要完成系统所需要数据计算功能,主要提供基于历史地震波形数据文件的连续率计算以及实时地震波形数据文件的连续率计算; 第3层是云平台中系统的数据持久层,主要提供处理层中各类计算结果的存储,包括测震连续波形数据、索引数据以及台站通道信息数据等。其中,连续率数据由于数据量巨大,将存储在分布式数据库Hbase中,通过Hbase接口进行存储和访问处理; 而其它类似基础信息类的数据,即数据量不大但处理响应性能要求较高的数据,将存储在关系数据库系统Mysql中,用JDBC/SQL进行存储和访问处理。
2.3 基于大数据架构的测震数据计算测试
本次测试编写了2个测震数据运行率计算程序,分别为基于Hadoop的大数据计算版本和基于多线程的单机版本。这里主要介绍大数据计算版本的程序设计和执行步骤:首先数据处理模块的主线程获取HDFS上的数据目录集合,并将目录集合以任务集的方式提交至计算节点进行计算,计算节点每次取出一天的数据进行计算,work从HDFS上取出某天目录下的所有Miniseed文件依次进行解析,每个Miniseed文件按512个字节为单位进行读取,读取时需要对重复数据进行选优计算,
图4 基于Hadoop的测震数据运行率计算模型
Fig.4 The calculation model of the operation rate of the seismic data based on Hadoop
并按每个小时为key,n个Miniseed数据为集合对value生成一个该日的HashMap; 接下来按每小时为单位遍历该日的HashMap,读取Miniseed数据的台站信息并计算该小时的连续率; 最后每个Miniseed文件计算完毕后,将解析出台网代码、台站代码、连续率计算结果一起推送到数据存储层进行存储。
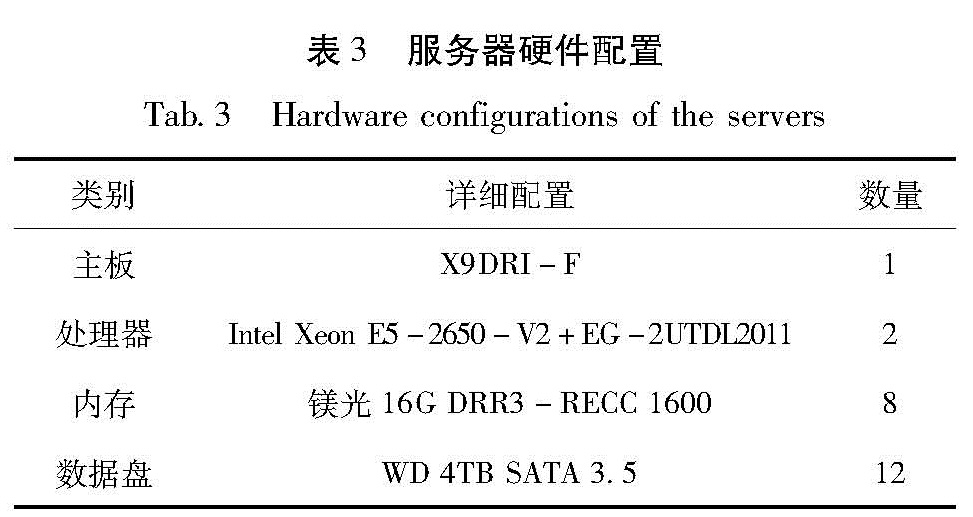
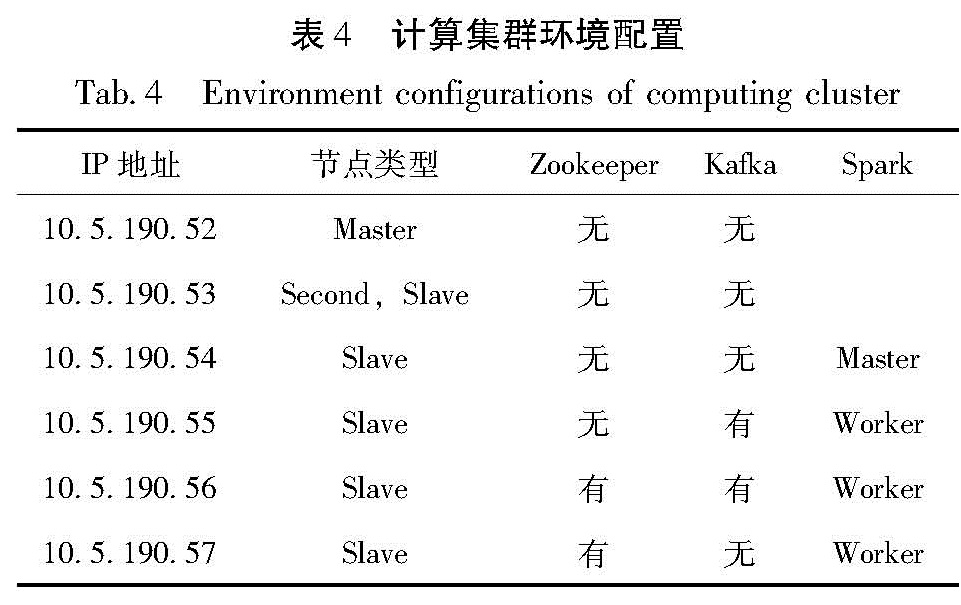
测试采用6台服务器组成的集群进行测试,集群中每台服务器的软硬件情况如表3、4所示。
表3 服务器硬件配置
Tab.3 Hardware configurations of the servers
表4 计算集群环境配置
Tab.4 Environment configurations of computing cluster
ZooKeeper是一个开放源码的分布式应用程序协调服务,是Hadoop和Hbase的重要组件,提供的功能包括配置维护、域名服务、分布式同步、组服务等; Hbase是一个分布式的、面向列的非结构化开源数据库,在纵向上可以提供无限扩展能力; Kafka是一种高吞吐量的分布式发布订阅消息系统,它通过Hadoop的并行加载机制来统一各类消息处理,也是为了通过集群来提供实时数据的缓存和消费; Spark 是一种与 Hadoop 相似的基于内存的开源集群计算环境,由于Spark 启用了内存分布数据集,除了能够提供交互式查询外,它还可以优化迭代工作负载。
测试数据采用2015年12月的全国测震波形数据,数据量约1 TB。多线程版本测试将1个月的Miniseed文件保存在10.5.190.56服务器的硬盘上,目录按每天1个文件夹进行存放,通过多线程技术分别将1个月的文件进行解析,测试结果如表5所示。
表5 多线程程序计算结果
Tab.5 Calculation results of multithreaded program
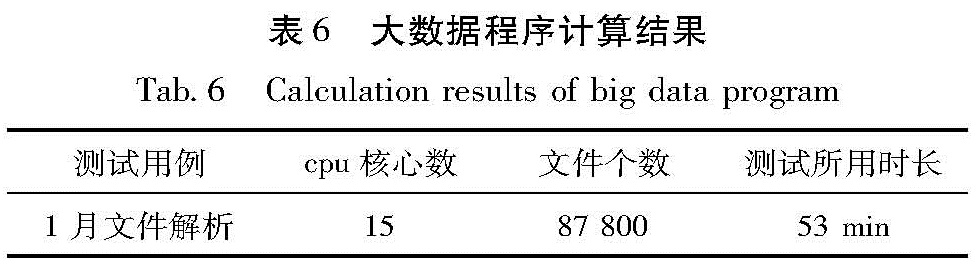
大数据版本测试将1个月的Minieed文件保存在10.5.190.56服务器的硬盘上,目录按每天1个文件夹进行存放,通过执行Hadoop的数据导入命令,将这些数据上传至HDFS文件系统上,执行Spark程序进行测试,测试结果如表6所示(Spark配置使用15个cpu内核,以1个任务进行提交)。
表6 大数据程序计算结果
Tab.6 Calculation results of big data program
通过上面测试,发现大数据版本的处理时间仅为多线程版本的1/6,多线程版本的数据放在本地硬盘,受限制于文件读取效率,而从HDFS文件系统读取,不限制于硬盘读取速率,且可以成倍的提高读取解析效率; 另外,如图5所示,其中计算节点10.5.190.53(图5a)上只有HDFS,所以上传速率是30~40 M/s,下载速度为0,表示该节点在为spark运算提供文件数据; 计算节点10.5.190.55(图5b)上不仅有HDFS节点,还有Spark计算节点,上传和下载速度约264 M/s,表明该节点不仅有Spark的work节点在接受并解析数据,同时,该节点在向外发送数据; 计算节点10.5.190.56(图5c)上也是不仅有HDFS节点,同时有Spark计算节点,但是上传速率很低,说明该解析的数据并没有存放在该节点上或存放量偏少。但是该节点文件接受速率为120 M/s,说明该节点在解析数据。由于本次测试的Hadoop集群配置的是千兆网卡,因此,120 M/s左右的速率为正常速率,220 M/s的上传下载速度表明该节点不仅接受其他HDFS节点传输过来的数据,同时在处理本机上的HDFS节点数据。综上可知,通过Spark计算,还有一定提升空间,由于网络带宽达到上限,通过增加服务器的方式,对网络进行负载均衡,可以进一步提升Spark解析任务的文件读取效率,进一步提升解析速度。
图5 基于Hadoop的集群计算节点运行界面
Fig.5 Running interface of computing cluster base on Hadoop