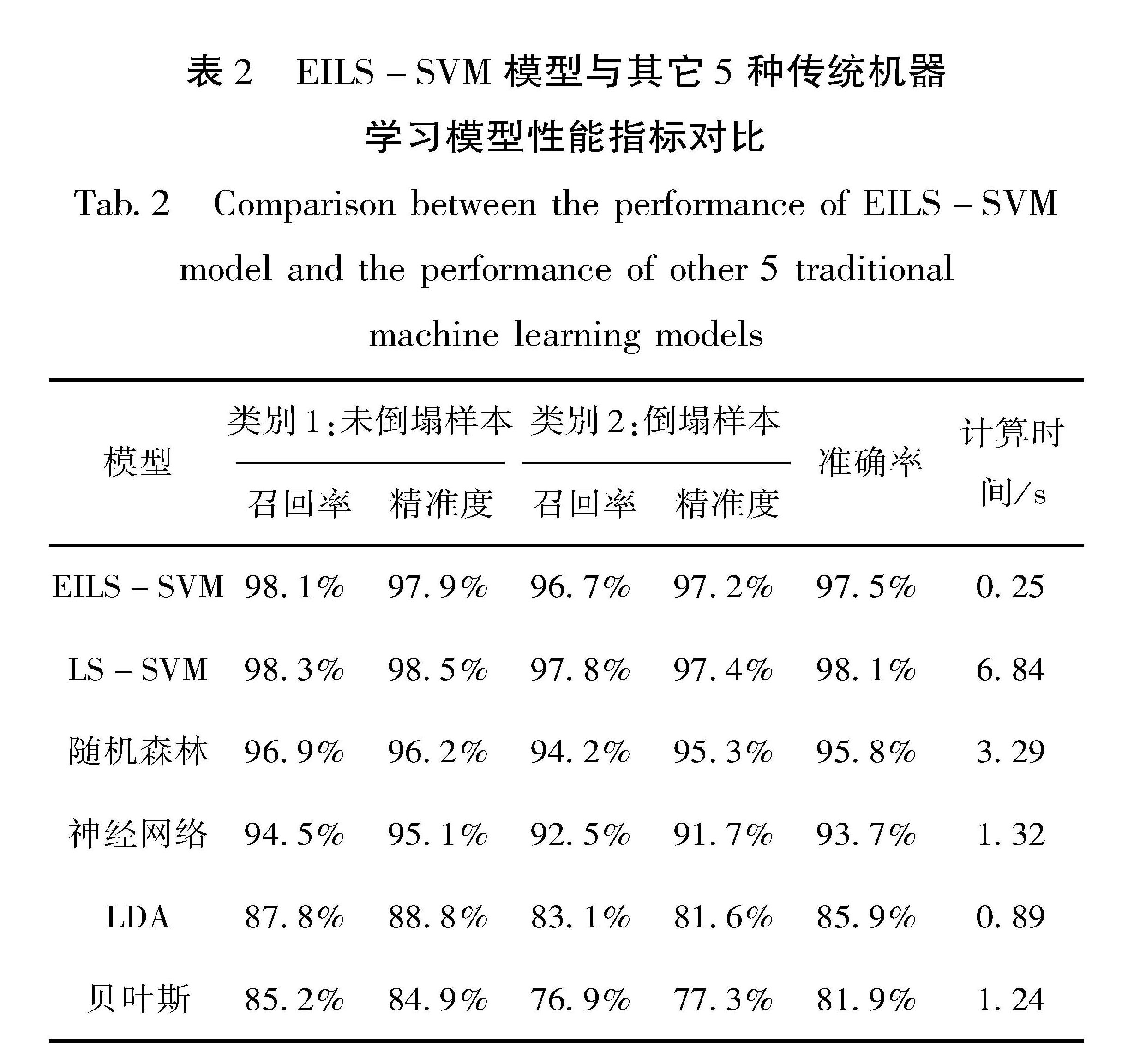
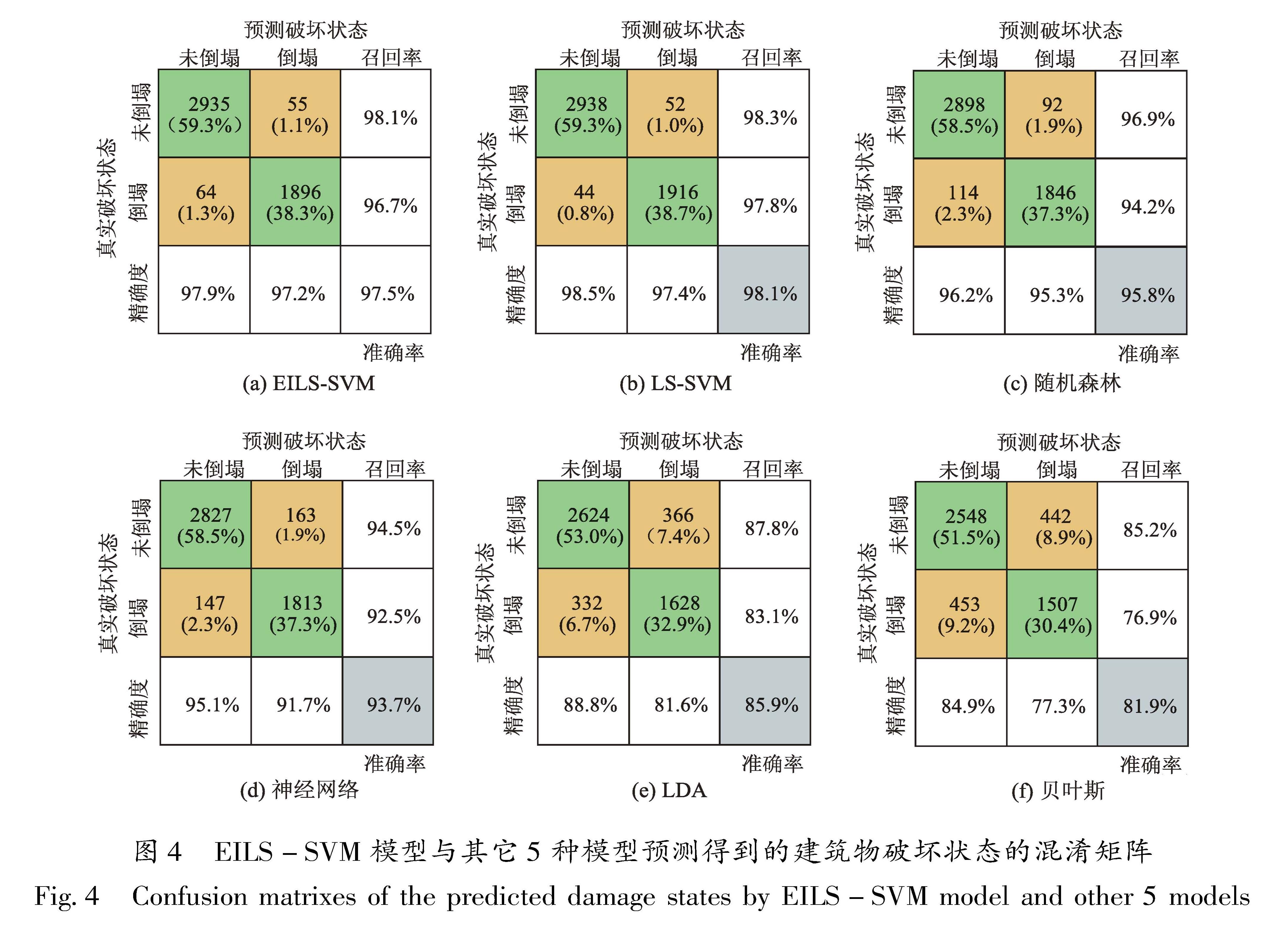
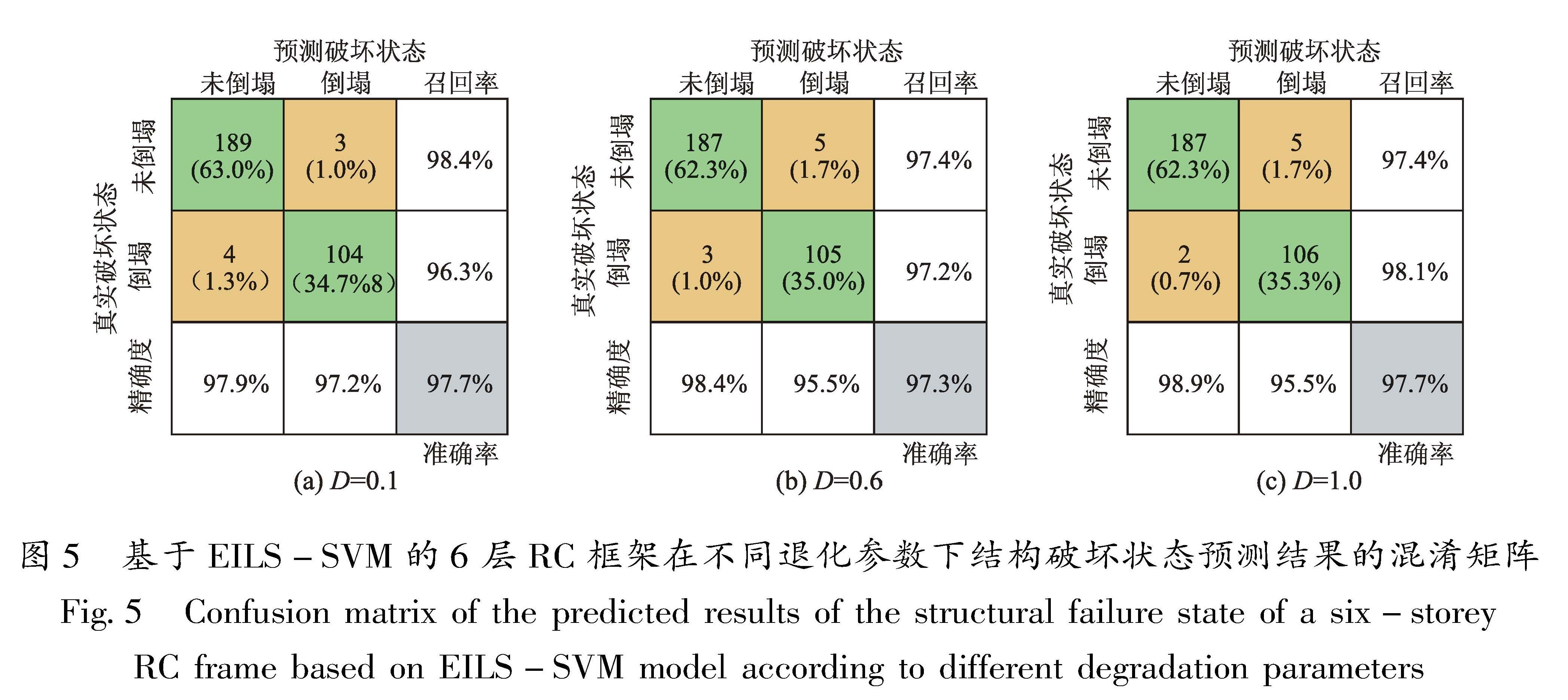
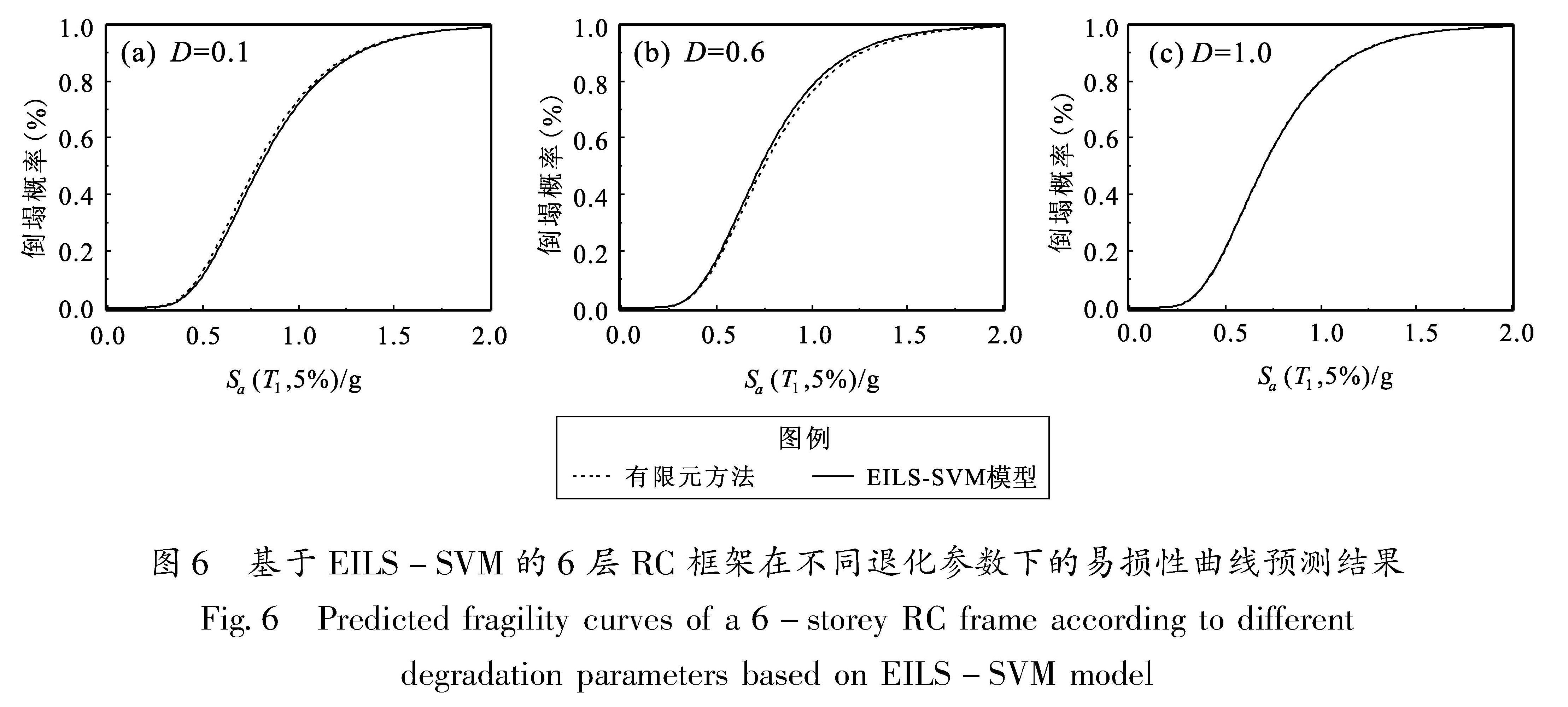
1.1 EILS-SVM数学模型构建
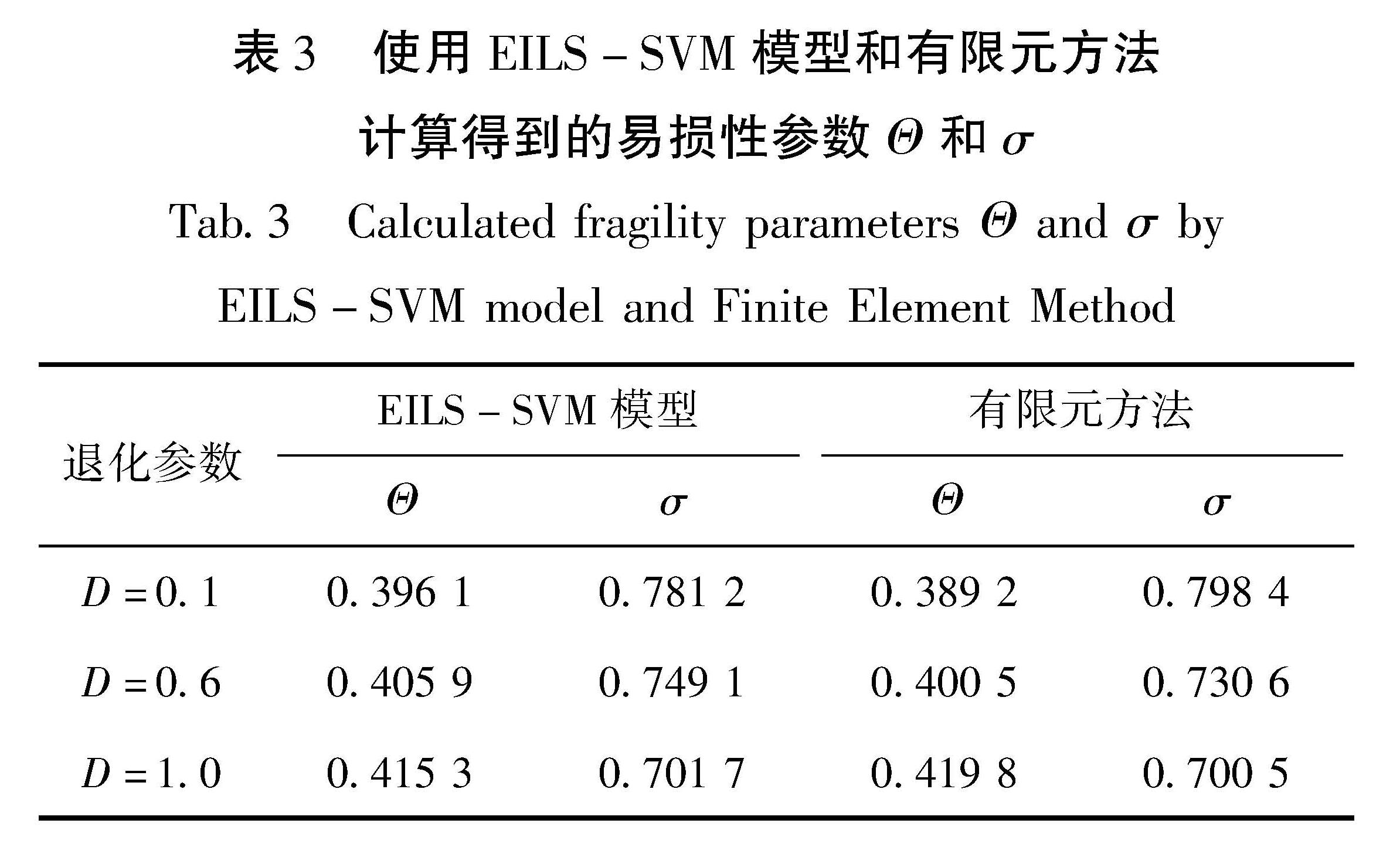
最小二乘支持向量机(LS-SVM)(Suykens,Vandewalle,1999)分类模型是一种较为常用的机器学习算法,其将支持向量机(Support Vector Machine,SVM)(Cervantes et al,2020)中求解二次规划问题转化成了求解线性方程组问题,极大地提高了SVM训练过程的计算效率。其优化问题如下所示:
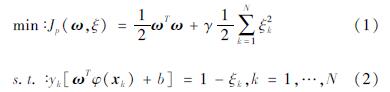
式中:ξk∈R是定义误差变量的向量; γ为正则化参数; φ(xk)∈Rh是高维输入向量,其中φ(·):Rd→Rh表示从d维到具有h维的高维度Hilbert空间的映射函数。其原始空间下的预测模型表达式为:
y(x)=sign[ωTφ(x)+b] (3)
由于高维输入向量φ(xk)未知,因此由式(1)和(2)构成的优化问题无法直接求解。为此,通过引入拉格朗日乘子αk∈R,构造式(1)和(2)的拉格朗日函数,并在对偶空间里进行求解。拉格朗日函数表达式为:
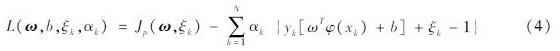
引入KTT条件求解方程式(4),可得到如下方程组:
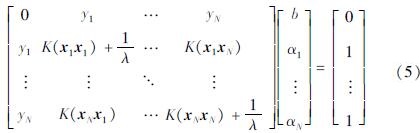
式中:K(xk,xl)=φT(xk)φ(xl)为核函数(本文所采用的核函数为高斯核(RBF)函数),通过带入核函数便可在对偶空间中得到模型参数α和b,其在对偶空间下的预测模型表达式如下:

至此,通过对偶空间建立的预测模型便可用于预测新样本数据所属的类别。但是,LS-SVM在求解矩阵方程(5)时,涉及到求解系数矩阵的逆矩阵,其计算复杂度与训练样本的规模N有关,为O[(N+1)3]。当给定训练样本数据{xk,yk}Nk=1的规模N较大时,求解这一大规模矩阵的逆矩阵就会变得极为耗时,造成模型训练过程的计算效率低下。因此,当训练样本的规模N较大时,在LS-SVM标准框架下通过方程(5),在对偶空间下求解模型参数进而构建预测模型(6)就会变得尤为低效。而反观原始空间下预测模型(3),其模型参数ω的维度与高维输入向量φ(xk)的维度h有关,计算复杂度为O[(h+1)3]。因此,即使训练样本数据{xk,yk}Nk=1的规模N较大, 若φ(xk)的维度hN,在原空间中建立预测模型将比在对偶空间下建立预测模型更为高效。这是因为,当hN时,在原始空间建立预测模型的计算复杂度要远远小于对偶空间,即O[(h+1)3]O[(N+1)3]。为了能在原空间建立预测模型,需要显示地构建非线性映射函数φ(·)的数学模型。然而,通常情况下φ(·)的数学模型无法显示。
为了解决这一问题,本文采用Nystrom方法中特征值和特征向量理论(Girolami,2002)近似估计出高维输入向量φ(xk),使得可以在原空间建立预测模型(3),进而解决LS-SVM在大样本训练数据集下预测模型训练效率低下的问题。首先,将方程(5)中由RBF核函数构成的核矩阵记为Ω(N,N)∈RN×N,其中Ω(k,l)=K(xk,xl),k,l=1,…,N。根据Mercer定理(Girolami,2002),可得到如下表达式:
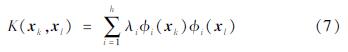
式中:λi和φi分别是特征值和相应的特征函数。这些特征值和特征函数与如下积分方程相关联,其表达式如下:
∫K(xk,x)φi(x)p(x)dx=λiφi(xk)(8)
式中:p(x)表示大规模训练样本输入变量xk的概率密度函数。在给定大规模数据集{xk,yk}Nk=1的条件下,假设输入样本xk,k=1,…,N之间服从独立同分布。为了近似估计特征函数的积分方程,可从大规模训练样本数据中随机抽取m个子样本{xt,yt}mt=1(mN),用子样本中的输入变量xt近似p(x),进而达到稀疏化的目的。基于此,式(8)可通过如下表达式近似:
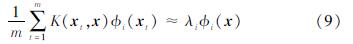
通过从大样本训练数据集中选取的m个子样本{xt,yt}mk=1可建立相应的核矩阵Ω(m,m),并对核矩阵进行特征值分解,可得到如下方程:
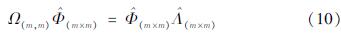
式中:Ω(m,m)∈Rm×m表示近似大规模核矩阵Ω(N,N)的稀疏化核矩阵;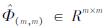 ,表示由Ω(m,m)的特征向量组成的矩阵;
,表示由Ω(m,m)的特征向量组成的矩阵;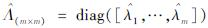 ∈Rm×m表示由Ω(m,m)的特征值组成的对角矩阵。
∈Rm×m表示由Ω(m,m)的特征值组成的对角矩阵。
将式(10)中的矩阵进行向量分解,可得到如下表达式:
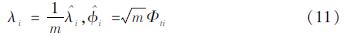
将式(11)带到方程(9)中可得到第i个特征函数的表达式:
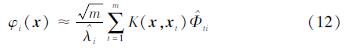
将式(7)与式(12)结合可以得到φ(xk)中第i个元素与第i个特征函数之间的关系式:
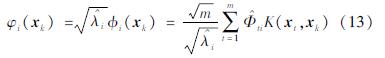
根据式(13)即可求出非线性高维向量的显性估计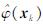 ,其中
,其中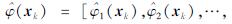
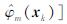 。因此,基于估计的高维输入变量
。因此,基于估计的高维输入变量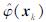 ,可利用最小二乘法直接求解由方程(1)和(2)构成的优化问题,进而可求得原空间下预测模型(3)中的模型参数ω和b。其计算公式为:
,可利用最小二乘法直接求解由方程(1)和(2)构成的优化问题,进而可求得原空间下预测模型(3)中的模型参数ω和b。其计算公式为:
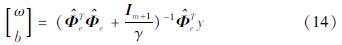
式中:Im+1为(m+1)×(m+1)的单位矩阵; y=[y1,y2,…,yN]T; 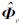 是N×(m+1)特征增广矩阵,具体形式如下:
是N×(m+1)特征增广矩阵,具体形式如下:
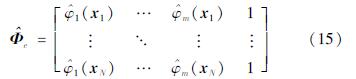
由方程(14)可知,本文所提出的EILS-SVM模型的计算复杂度与高维映射函数φ(xk)的维度m有关, 为O(m3)。因为mN, 所以O(m3)O(N3)。因此,从理论上分析,本文提出的EILS-SVM模型能显著提高计算效率。此外,由于系数矩阵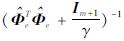 的规模为(m+1)且(m+1)N,因此EILS-SVM也能显著降低对计算机内存的需求。
的规模为(m+1)且(m+1)N,因此EILS-SVM也能显著降低对计算机内存的需求。
1.2 EILS-SVM预测模型建立步骤
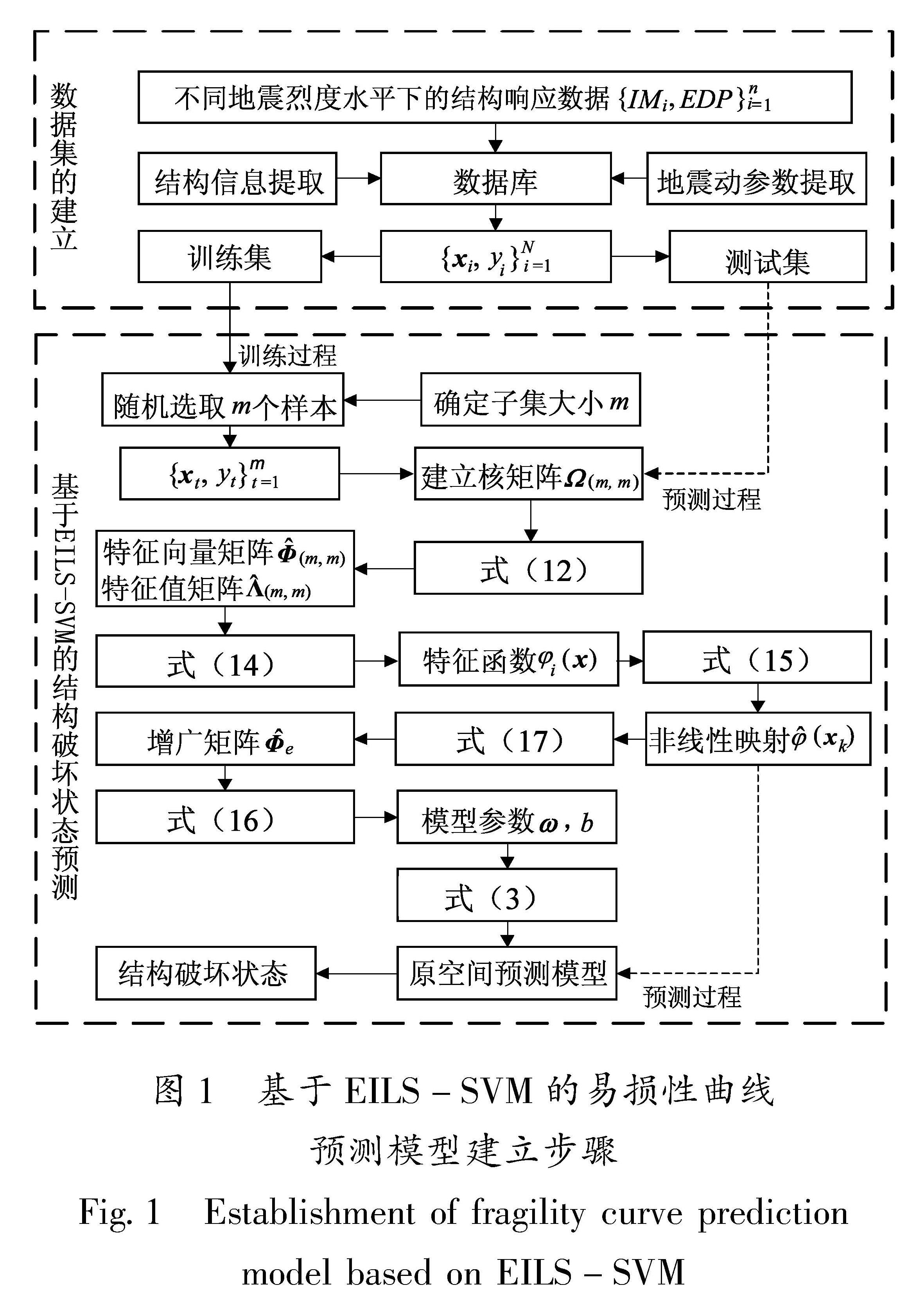
基于EILS-SVM的结构破坏状态预测模型的建立步骤如图1所示,具体分为以下8个步骤:
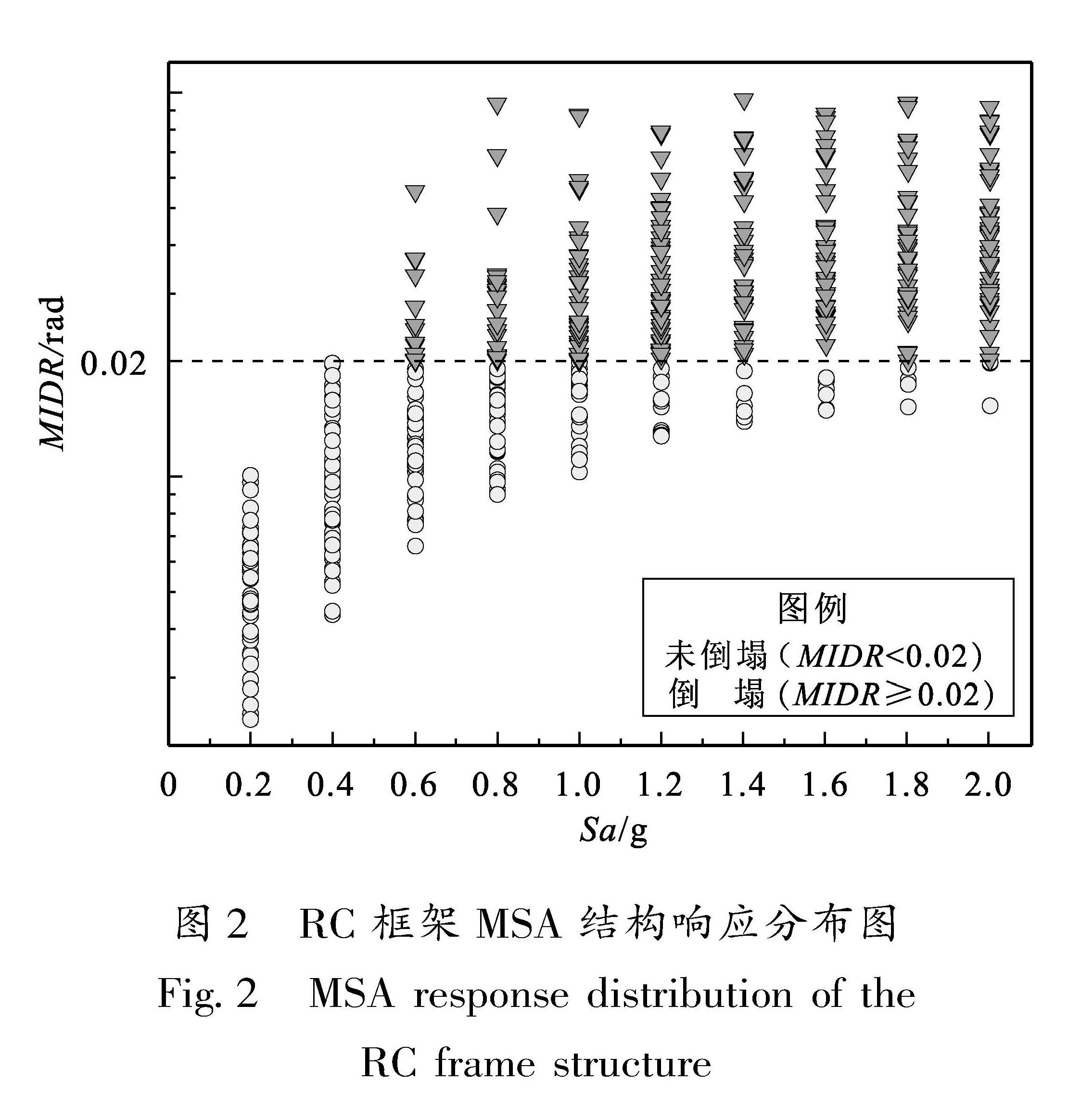
步骤1:建立结构响应数据库,获得不同地震强度和不同地震强度下结构的工程需求参数(Engineering Demand Parameter,EDP)所组成的样本集{IMi,EDPi}ni=1。
步骤2:为样本集{IMi,EDPi}ni=1中的每个样本点提取对应的结构设计变量和地震动参数建立样本信息数据库。
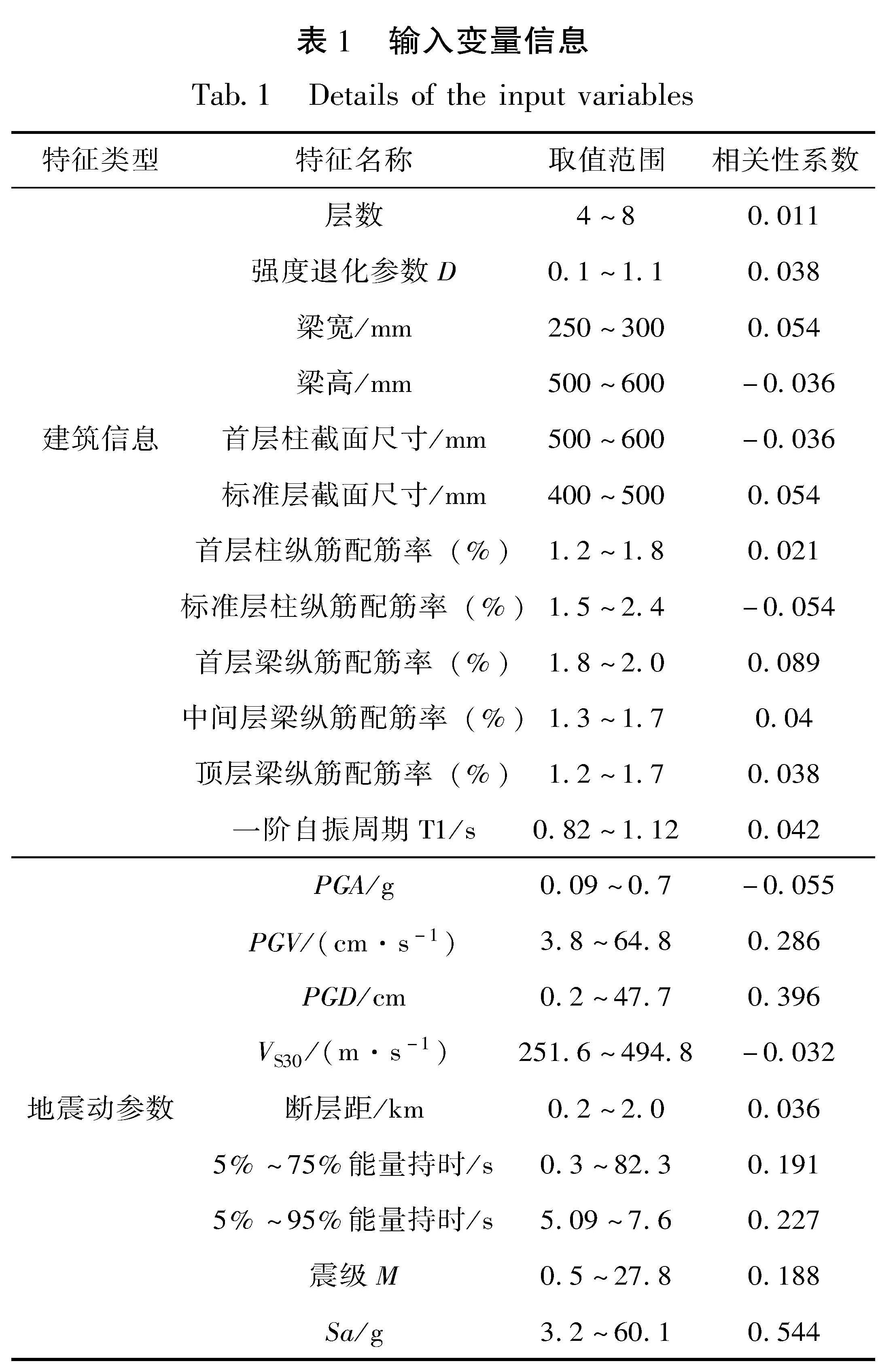
步骤3:基于结构的EDP极限状态阈值,将样本信息数据库中的每个样本点按照EDP是否超过阈值分为两类,从而构建大规模数据集{xk,yk }Nk=1。其中xk=[x1,x2,…,xd]为结构的设计变量和地震动参数组成的向量,yk∈{1,-1}为不同结构破坏状态的类别标签。
步骤4:将数据集划分为训练集与测试集。其中训练集中的部分数据(支持向量)用来训练预测模型,测试集的数据则用来预测结构破坏状态。
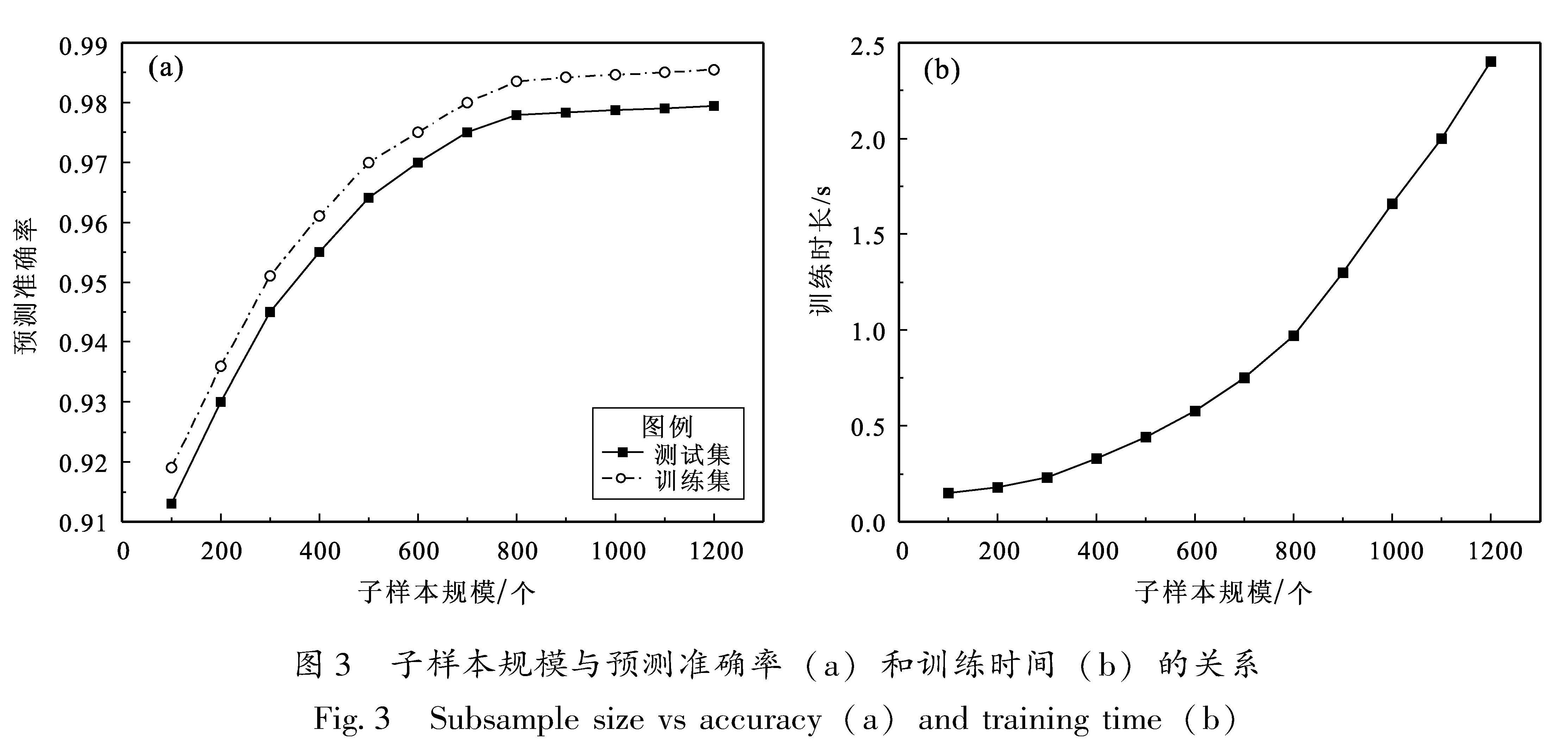
步骤5:确定子样本规模大小m(mN)。子样本规模大小直接影响EILS-SVM的性能,m过小会导致EILS-SVM的预测精度较低,m过大则会增加模型的计算成本,降低计算效率。
步骤6:从训练集中随机抽取m个样本作为支持向量用于训练EILS-SVM模型。
步骤7:按照本文提出的EILS-SVM理论求解出模型参数ω和b,建立支持向量机原空间预测模型。
步骤8:将测试集数据输入建立好的原空间预测模型,开展结构在不同地震动强度IMi下的破坏状态的预测。
图1 基于EILS-SVM的易损性曲线预测模型建立步骤
Fig.1 Establishment of fragility curve prediction model based on EILS-SVM